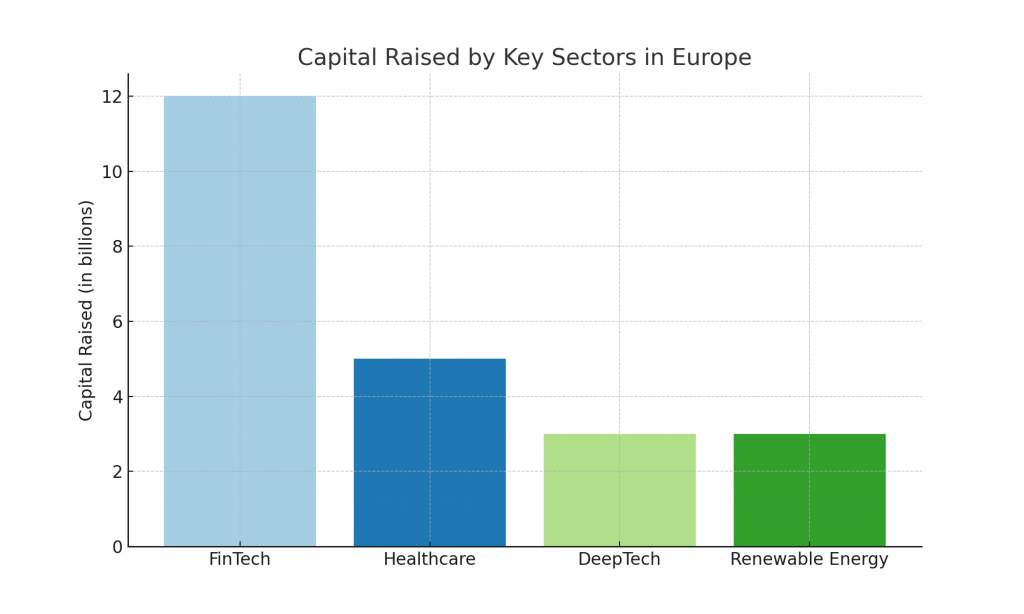
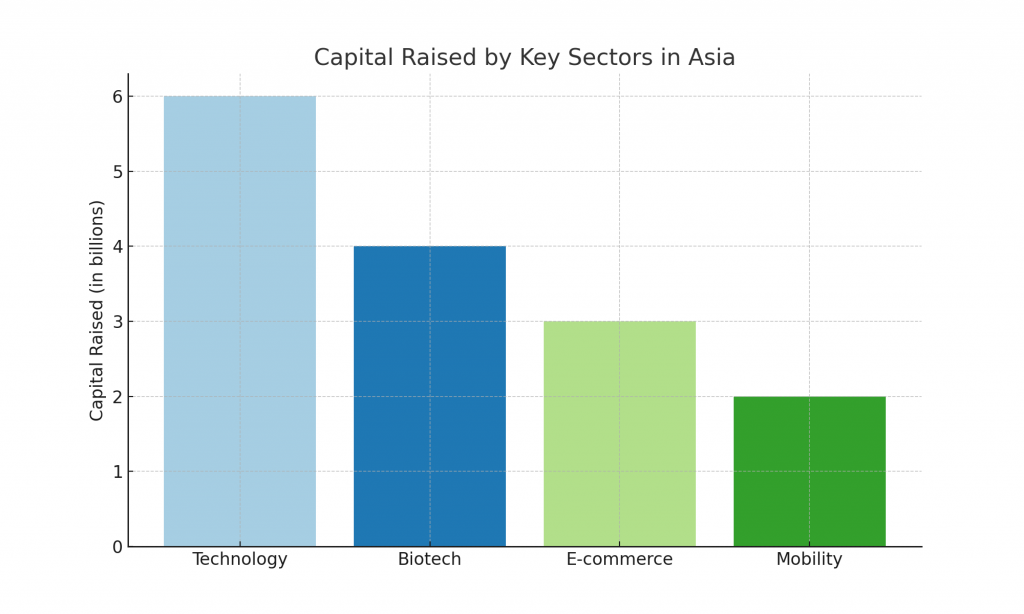
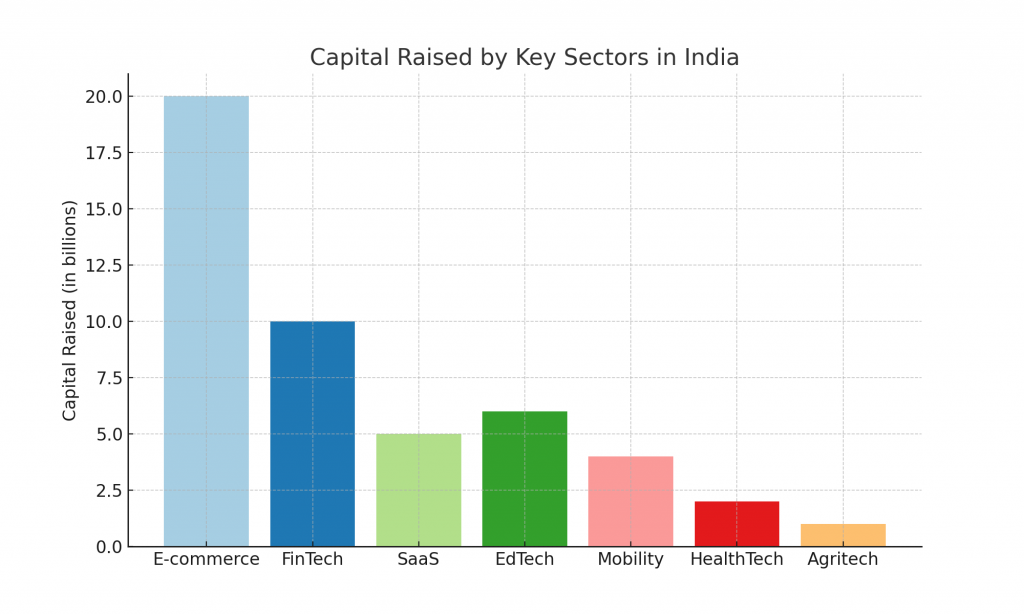
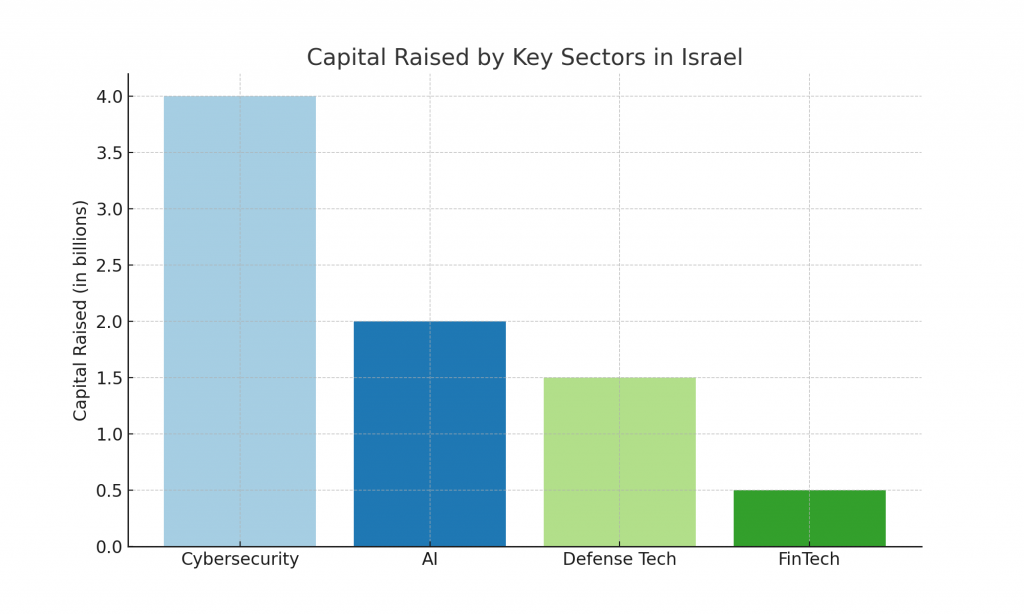
Why Startups Should Put Security First: Push from Five Eyes
Five Eyes intelligence chiefs warn of ‘sharp rise’ in commercial espionage

The Five Eyes nations—Australia, Canada, New Zealand, the UK, and the US—have launched a joint initiative, Secure Innovation, to encourage tech startups to adopt robust security practices. This collaborative effort aims to address the increasing cyber threats faced by emerging technology companies, particularly from sophisticated nation-state actors.
The Growing Threat Landscape
The rapid pace of technological innovation has made startups a prime target for cyberattacks. These attacks can range from intellectual property theft and data breaches to disruption of critical services. A recent report by the Five Eyes alliance highlights that emerging tech ecosystems are facing unprecedented threats. To mitigate these risks, the Five Eyes have outlined five key principles for startups to follow, as detailed in guidance from the National Cyber Security Centre (NCSC):
- Know the Threats: Startups must develop a strong understanding of the threat landscape, including potential vulnerabilities and emerging threats. This involves staying informed about the latest cyber threats, conducting regular risk assessments, and implementing effective threat intelligence practices.
- Secure the Business Environment: Establishing a strong security culture within the organization is essential. This includes appointing a dedicated security leader, implementing robust access controls, and conducting regular security awareness training for employees. Additionally, startups should prioritize incident response planning and testing to minimize the impact of potential cyberattacks.
- Secure Products by Design: Security should be integrated into the development process from the outset. This involves following secure coding practices, conducting regular security testing, and using secure software development frameworks. By prioritizing security from the beginning, startups can reduce the risk of vulnerabilities and data breaches.
- Secure Partnerships: When collaborating with third-party vendors and partners, startups must conduct thorough due diligence to assess their security practices. Sharing sensitive information with untrusted partners can expose the startup to significant risks, making it crucial to ensure all partners adhere to robust security standards.
- Secure Growth: As startups scale, they must continue to prioritize security. This involves expanding security teams, implementing advanced security technologies, and maintaining a strong security culture. Startups should also consider conducting regular security audits and penetration testing to identify and address potential vulnerabilities.
Why Is Secure by Design So Difficult for Startups?
While the concept of “Secure by Design” is critical, many startups find it challenging to implement due to several reasons:
- Limited Resources: Startups often operate on tight budgets, focusing on minimum viable products (MVPs) to prove market fit. Allocating funds to security can feel like a competing priority, especially when the immediate goal is rapid growth.
- Time Pressure: The urgency to get products to market quickly means that startups may overlook secure development practices, viewing them as “nice-to-haves” rather than essential components. This rush often leads to security gaps that may only become apparent later.
- Talent Shortage: Finding experienced security professionals is difficult, especially for startups with limited financial leverage. Skilled engineers who can integrate security into the development lifecycle are often more interested in established firms that can offer competitive salaries.
- Perceived Incompatibility with Innovation: Security measures are sometimes seen as inhibitors to creativity and innovation. Secure coding practices, frequent testing, and code reviews are viewed as processes that slow down development, making startups hesitant to incorporate them during their early stages.
- Complexity of Security Requirements: Startups often struggle to understand and implement comprehensive security measures without prior experience or guidance. Security requirements can be perceived as overwhelming, especially for small teams already juggling development, marketing, and scaling responsibilities.
This perceived incompatibility of security with growth, coupled with resource and talent constraints, results in many startups postponing a “secure by design” approach, potentially exposing them to higher risks down the line.
How Startups Can Achieve Secure by Design Architectures
Despite these challenges, achieving a Secure by Design architecture is both feasible and advantageous for startups. Here are key strategies to help build secure foundations:
- Hiring and Building a Security-Conscious Team:
- Early Inclusion of Security Expertise: Hiring a security professional or appointing a security-focused technical co-founder can lay the groundwork for embedding security into the company’s DNA.
- Upskilling Existing Teams: Startups may not be able to hire dedicated security engineers immediately, but they can train existing developers. Investing in security certifications like CISSP, CEH, or courses on secure coding will improve the team’s overall competency.
- Integrating Security into Design and Development:
- Threat Modeling and Risk Assessment: Incorporate threat modeling sessions early in product development to identify potential risks. By understanding threats during the design phase, startups can adapt their architectures to minimize vulnerabilities.
- Secure Development Lifecycle: Implement a secure software development lifecycle (SDLC) with consistent code reviews and static analysis tools to catch vulnerabilities during development. Automating security checks using tools like Snyk or OWASP ZAP can help catch issues without slowing development significantly.
- Focusing on Scalable Security Frameworks:
- Microservices Architecture: Startups can consider using a microservices-based architecture. This allows them to isolate services, meaning that a compromise in one area of the product doesn’t necessarily lead to full-system exposure.
- Zero Trust Principles: Startups should build products with Zero Trust principles, ensuring that every interaction—whether internal or external—is authenticated and validated. Even at an early stage, implementing identity management protocols and ensuring encrypted data flow will create a secure-by-default product.
- Investing in Security Tools and Automation:
- Continuous Integration and Delivery (CI/CD) Pipeline Security: Integrating security checks into CI/CD processes ensures that every code commit is tested for vulnerabilities. Open-source tools like Jenkins can be configured with security plugins, making security an automated and natural part of the development workflow.
- Use of DevSecOps: Adopting a DevSecOps culture can streamline security implementation. This ensures security practices evolve alongside development processes, rather than being bolted on afterward. DevSecOps also fosters collaboration between development, operations, and security teams.
- Leveraging External Support and Partnerships:
- Partnering with Managed Security Providers: Startups lacking the capacity for in-house security can benefit from partnerships with managed security providers. This allows them to outsource their security needs to experts while they focus on core product development.
- Utilize Government and Industry Resources: Programs like Secure Innovation and government grants provide startups with the frameworks and sometimes the financial resources needed to adopt security measures without excessive cost burdens.
Conclusion
The Five Eyes’ Secure Innovation initiative is a significant step forward in protecting the interests of tech startups. By embracing these principles and striving for a secure-by-design architecture, startups can not only mitigate cyber risks but also gain a competitive advantage in the marketplace. The key to startup success is integrating security into the heart of product development from the outset, recognizing it as a value-add rather than an impediment.
With the right strategies—whether through hiring, training, automation, or partnerships—startups can create secure and scalable products, build customer trust, and position themselves for long-term success in a competitive digital landscape.
References and Further Reading:
- Five Eyes launch Secure Innovation to protect tech sector – Open Access Government
- Five Eyes launch shared advice for tech startups – National Cyber Security Centre
- Five Eye collaboration at DoDIIS Worldwide – Clearance Jobs
- Five Eyes Alliance Unveils Secure Innovation Guidance – ExecutiveGov