Innovation Drain: Is Palantir Losing Its Edge In 2025?
“Innovation doesn’t always begin in a boardroom. Sometimes, it starts in someone’s resignation email.”

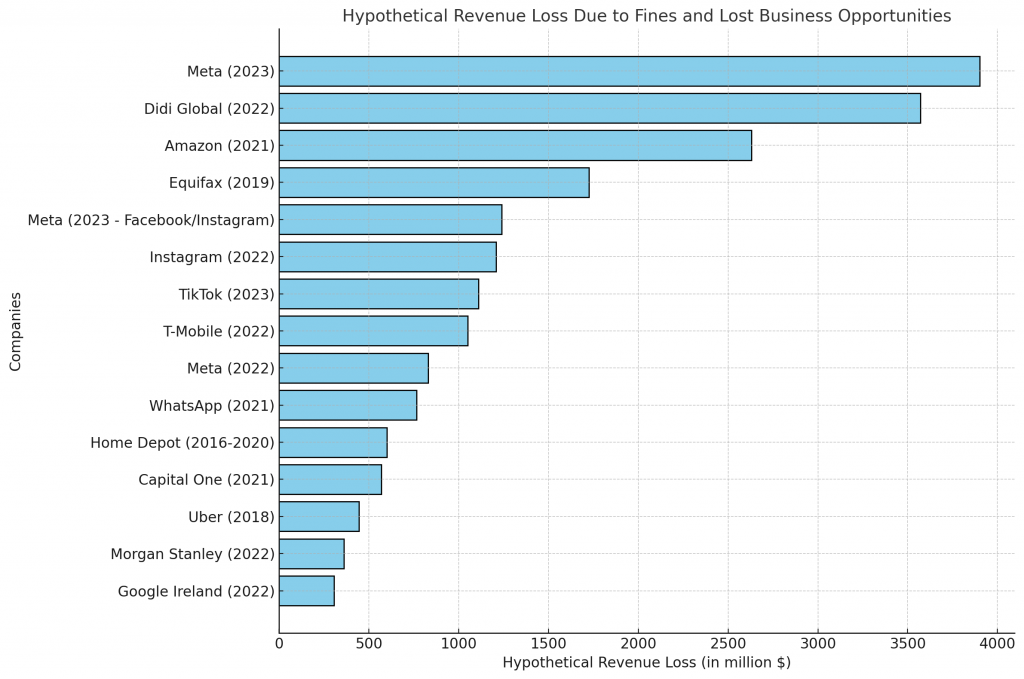
In April 2025, Palantir dropped a lawsuit-shaped bombshell on the tech world. It accused Guardian AI—a Y-Combinator-backed startup founded by two former Palantir employees—of stealing trade secrets. Within weeks of leaving, the founders had already launched a new platform and claimed their tool saved a client £150,000.
Whether that speed stems from miracle execution or muscle memory is up for debate. But the legal question is simpler: Did Guardian AI walk away with Palantir’s crown jewels?
Here’s the twist: this is not an isolated incident. It’s part of a long lineage in tech where forks, clones, and spin-offs are not exceptions—they’re patterns.
Innovation Splinters: Why People Fork and Spin Off
Commercial vs Ideological vs Governance vs Legal Grey Zone
To better understand the nature of these forks and exits, it’s helpful to bucket them based on the root cause. Some are commercial reactions, others ideological; many stem from poor governance, and some exist in legal ambiguity.
Commercial and Strategic Forks
MySQL to MariaDB: Preemptive Forking
When Oracle acquired Sun Microsystems, the MySQL community saw the writing on the wall. Original developers forked the code to create MariaDB, fearing Oracle would strangle innovation.
To this day, both MySQL and MariaDB co-exist, but the fork reminded everyone: legal ownership doesn’t mean community trust. MariaDB’s success hinged on one truth—if you built it once, you can build it better.
Cassandra: When Innovation Moves On
Born at Facebook, Cassandra was open-sourced and eventually handed over to the Apache Foundation. Today, it’s led by a wide community of contributors. What began as an internal tool became a global asset.
Facebook never sued. Instead, it embraced the open innovation model. Not every exit has to be litigious.
Governance and Ideological Differences
SugarCRM vs vTiger: Born of Frustration
In the early 2000s, SugarCRM was the darling of open-source CRM. But its shift towards commercial licensing alienated contributors. Enter vTiger CRM—a fork by ex-employees and community members who wanted to stay true to open principles. vTiger wasn’t just a copy. It was a critique.
Forks like this aren’t always about competition. They’re about ideology, governance, and autonomy.
OpenOffice to LibreOffice: Governance is Everything
StarOffice, then OpenOffice.org, eventually became a symbol of open productivity tools. But Oracle’s acquisition led to concerns over the project’s future. A governance rift triggered the formation of LibreOffice, led by The Document Foundation.
LibreOffice wasn’t born because of a feature war. It was born because developers didn’t trust the stewards. As your own LinkedIn article rightly noted: open-source isn’t just about access to code—it’s about access to decision-making.
Elastic, Redis, and Your Fork Writings
In my earlier articles on Elastic’s open-source licensing journey and the Redis licensing shift, I unpacked how open-source communities often respond to perceived shifts in governance and monetisation priorities:
- Elastic’s licensing changes—primarily to counter cloud hyperscaler monetisation—sparked the creation of OpenSearch.
- Redis’ decision to adopt more restrictive licensing prompted forks like Valkey, driven by a desire to preserve ecosystem openness.
These forks weren’t acts of rebellion. They were community-led efforts to preserve trust, autonomy, and the spirit of open development—especially when governance structures were seen as diverging from community expectations.
Speculative Malice and Legal Grey Zones
Zoho vs Freshworks: The Legal Grey Zone
In a battle closer to Palantir’s turf, Zoho sued Freshdesk (now Freshworks), alleging its ex-employee misused proprietary knowledge. The legal line between know-how and trade secret blurred. The case eventually settled, but it spotlighted the same dilemma:
When does experience become intellectual property?
Palantir vs Guardian AI: Innovation or Infringement?
The lawsuit alleges the founders used internal documents, architecture templates, and client insights from their time at Palantir. According to the Forbes article, Palantir has presented evidence suggesting the misappropriated information includes key architectural frameworks for deploying large-scale data ingestion pipelines, client-specific insurance data modelling configurations, and a set of reusable internal libraries that formed the backbone of Palantir’s healthcare analytics solutions.
Moreover, the codebase referenced in Guardian AI’s marketing demos reportedly bore similarities to internal Palantir tools—raising questions about whether this was clean-room engineering or a case of re-skinning proven IP.
Palantir might win the case. Or it might just win headlines. Either way, it won’t undo the launch or rewind the execution.
The 72% Problem: Trade Secrets Walk on Two Legs
As Intanify highlights: 72% of employees take material with them when they leave. Not out of malice, but because 59% believe it’s theirs.
The problem isn’t espionage. It’s misunderstanding.
If engineers build something and pour years into it, they believe they own it—intellectually if not legally. That’s why trade secret protection is more about education, clarity, and offboarding rituals than it is about courtroom theatrics.
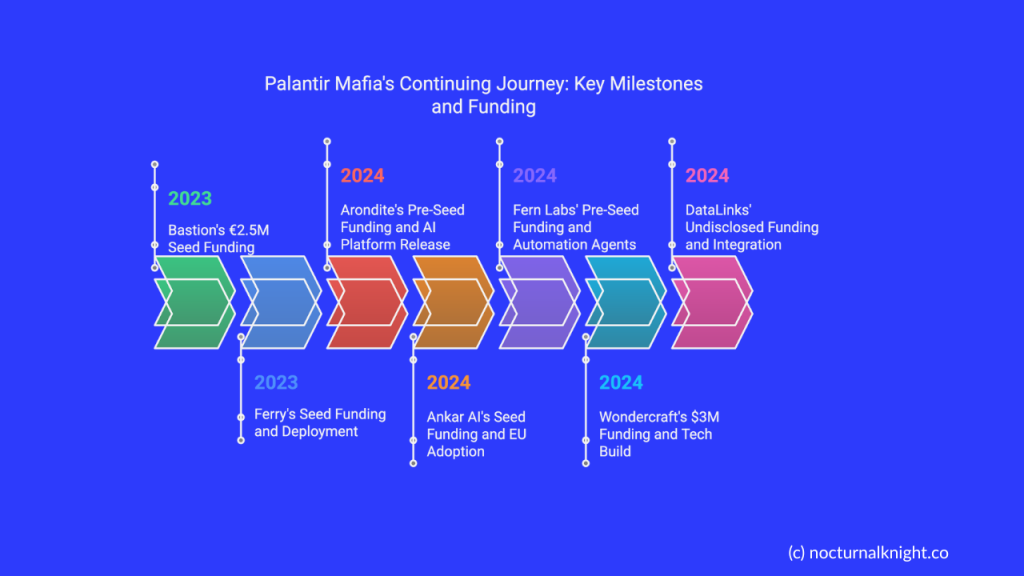
Palantir: The Google of Capability, The PayPal of Alumni Clout
Palantir has always operated in a unique zone. Internally, it combines deep government contracts with Silicon Valley mystique. Externally, its alumni—like those from PayPal before it—are launching startups at a blistering pace.
In your own writing on the Palantir Mafia and its invisible footprint, you explore how Palantir alumni are quietly reshaping defence tech, logistics, public policy, and AI infrastructure. Much like Google’s former engineers dominate web infrastructure and machine learning, Palantir’s ex-engineers carry deep understanding of secure-by-design systems, modular deployments, and multi-sector analytics.
Guardian AI is not an aberration—it’s the natural consequence of an ecosystem that breeds product-savvy problem-solvers trained at one of the world’s most complex software institutions.
If Palantir is the new Google in terms of engineering depth, it’s also the new PayPal in terms of spinoff potential. What follows isn’t just competition. It’s a diaspora.
What Companies Can Actually Do
You can’t fork-proof your company. But you can make it harder for trade secrets to walk out the door:
- Run exit interviews that clarify what’s owned by the company
- Monitor code repository access and exports
- Create intrapreneurship pathways to retain ambitious employees
- Invest in role-based access and audit trails
- Sensitise every hire on what “IP” actually means
Hire smart people? Expect them to eventually want to build their own thing. Just make sure they build their own thing.
Conclusion: Forks Are Features, Not Bugs
Palantir’s legal drama isn’t unique. It’s a case study in what happens when ambition, experience, and poor IP hygiene collide.
From LibreOffice to MariaDB, vTiger to Freshworks—innovation always finds a way. Trade secrets are important. But they’re not fail-safes.
When you hire fiercely independent minds, you get fire. The key is to manage the spark—not sue the flame.
References
Byfield, B. (n.d.). The Cold War Between OpenOffice.org and LibreOffice. Linux Magazine. Available at: https://www.linux-magazine.com/Online/Blogs/Off-the-Beat-Bruce-Byfield-s-Blog/The-Cold-War-Between-OpenOffice.org-and-LibreOffice
Feldman, A. (2025). Palantir Sues Y-Combinator Startup Guardian AI Over Alleged Trade Secret Theft. Forbes. Available at: https://www.forbes.com/sites/amyfeldman/2025/04/01/palantir-sues-y-combinator-startup-guardian-ai-over-alleged-trade-secret-theft-health-insurance/
Intanify Insights. (n.d.). Palantir, People, and the 72% Problem. Available at: https://insights.intanify.com/palantir-people-and-the-72-problem
PACERMonitor. (2025). Palantir Technologies Inc v. Guardian AI Inc et al. Available at: https://www.pacermonitor.com/public/case/57171731/Palantir_Technologies_Inc,_v_Guardian_AI,_Inc,_et_al
Sundarakalatharan, R. (2023). Elastic’s Open Source Reversal. NocturnalKnight.co. Available at: https://nocturnalknight.co/why-did-elastic-decide-to-go-open-source-again/
Sundarakalatharan, R. (2023). Inside the Palantir Mafia: Secrets to Succeeding in the Tech Industry. NocturnalKnight.co. Available at: https://nocturnalknight.co/inside-the-palantir-mafia-secrets-to-succeeding-in-the-tech-industry/
Sundarakalatharan, R. (2024). The Fork in the Road: The Curveball That Redis Pitched. NocturnalKnight.co. Available at: https://nocturnalknight.co/the-fork-in-the-road-the-curveball-that-redis-pitched/
Sundarakalatharan, R. (2024). Inside the Palantir Mafia: Startups That Are Quietly Shaping the Future. NocturnalKnight.co. Available at: https://nocturnalknight.co/inside-the-palantir-mafia-startups-that-are-quietly-shaping-the-future/
Sundarakalatharan, R. (2023). Open Source vs Open Governance: The State and Future of the Movement. LinkedIn. Available at: https://www.linkedin.com/pulse/open-source-vs-governance-state-future-movement-sundarakalatharan/
Inc42. (2020). SaaS Giants Zoho And Freshworks End Legal Battle. Available at: https://inc42.com/buzz/saas-giants-zoho-and-freshworks-end-legal-battle/
ExpertinCRM. (2019). vTiger CRM vs SugarCRM: Pick a Side. Medium. Available at: https://expertincrm.medium.com/vtiger-crm-vs-sugarcrm-pick-a-side-4788de2d9302