What Caused Cloudflare’s Big Crash? It’s Not Rust
The Promise
Cloudflare’s outage did not just take down a fifth of the Internet. It exposed a truth we often avoid in engineering: complex systems rarely fail because of bad code. They fail because of the invisible assumptions we build into them.
This piece cuts past the memes, the Rust blame game and the instant hot takes to explain what actually broke, why the outrage misfired and what this incident really tells us about the fragility of Internet-scale systems.
If you are building distributed, AI-driven or mission-critical platforms, the key takeaways here will reset how you think about reliability and help you avoid walking away with exactly the wrong lesson from one of the year’s most revealing outages.

1. Setting the Stage: When a Fifth of the Internet Slowed to a Crawl
On 18 November, Cloudflare experienced one of its most significant incidents in recent years. Large parts of the world observed outages or degraded performance across services that underpin global traffic.
As always, the Internet reacted the way it knows best: outrage, memes, instant diagnosis delivered with absolute confidence.
Within minutes, social timelines flooded with:
- “It must be DNS”
- “Rust is unsafe after all”
- “This is what happens when you rewrite everything”
- “Even Downdetector is down because Cloudflare is down”
- Screenshots of broken CSS on Cloudflare’s own status page
- Accusations of over-engineering, under-engineering and everything in between
The world wanted a villain. Rust happened to be available. But the actual story is more nuanced and far more interesting. (For the record, I am still not convinced we should rewrite Linux kernel in Rust !)
2. What Actually Happened: A Clear Summary of Cloudflare’s Report
Cloudflare’s own post-incident write-up is unusually thorough. If you have not read it, you should. In brief:
- Cloudflare is in the middle of a major multi-year upgrade of its edge infrastructure, referred to internally as the 20 percent Internet upgrade.
- The rollout included a new feature configuration file.
- This file contained more than two hundred features for their FL2 component, crossing a size limit that had been assumed but never enforced through guardrails.
- The oversized file triggered a panic in the Rust-based logic that validated these configurations.
- That panic initiated a restart loop across a large portion of their global fleet.
- Because the very nodes that needed to perform a rollback were themselves in a degraded state, Cloudflare could not recover the control plane easily.
- This created a cascading, self-reinforcing failure.
- Only isolated regions with lagged deployments remained unaffected.
The root cause was a logic-path issue interacting with operational constraints. It had nothing to do with memory safety and nothing to do with Rust’s guarantees.
In other words: the failure was architectural, not linguistic.
3.2 The “unwrap() Is Evil” Argument (I remember writing a blog titled Eval() is not Evil() ~2012)
One of the most widely circulated tweets framed the presence of an unwrap() as a ticking time bomb, casting it as proof that Rust developers “trust themselves too much”. This is a caricature of the real issue.
The error did not arise because of an unwrap(), nor because Rust encourages poor error handling. It arose because:
- an unexpected input crossed a limit,
- guards were missing,
- and the resulting failure propagated in a tightly coupled system.
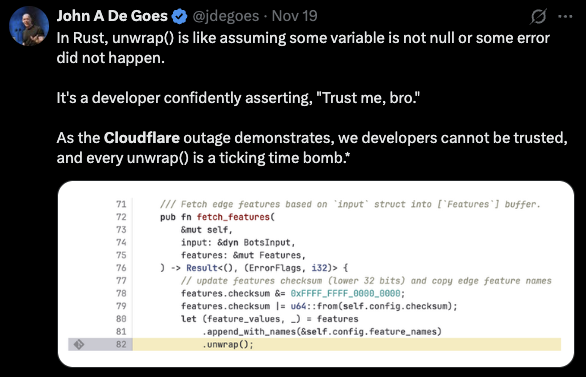
The same failure would have occurred in Go, Java, C++, Zig, or Python.
3.3 Transparency Misinterpreted as Guilt
Cloudflare did something rare in our industry.
They published the exact code that failed. This was interpreted by some as:
“Here is the guilty line. Rust did it.”
In reality, Cloudflare’s openness is an example of mature engineering culture. More on that later.
4. The Internet Rage Cycle: Humour, Oversimplification and Absolute Certainty
The memes and tweets around this outage are not just entertainment. They reveal how the broader industry processes complex failure.
4.1 The ‘Everything Balances on Open Source’ Meme
Images circulated showing stacks of infrastructure teetering on boxes labelled DNS, Linux Foundation and unpaid open source developers, with Big Tech perched precariously on top.
This exaggeration contains a real truth. We live in a dependency monoculture. A few layers of open source and a handful of service providers hold up everything else.
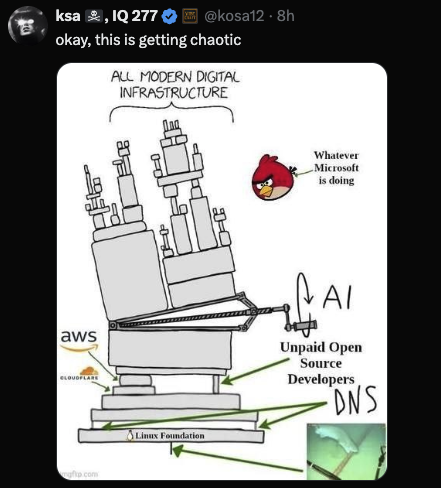
The meme became shorthand for Internet fragility.
4.2 The ‘It Was DNS’ Routine
The classic:
“It is not DNS. It cannot be DNS. It was DNS.”
Except this time, it was not DNS.
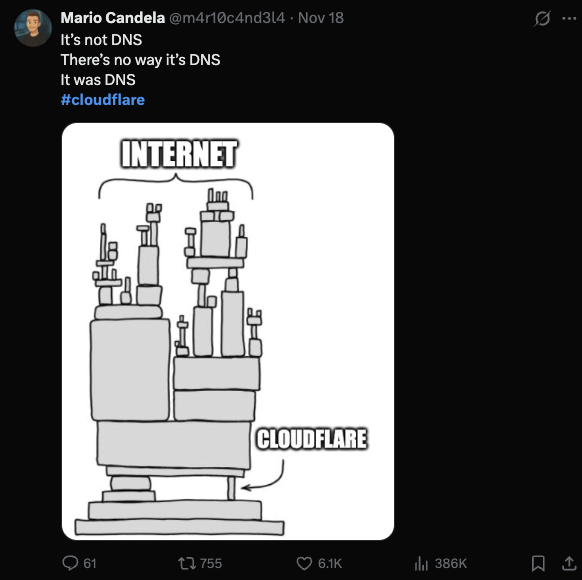
Yet the joke resurfaces because DNS has become the folk villain for any outage. People default to the easiest mental shortcut.
4.3 The Rust Panic Narrative
Tweets claiming:
“Cloudflare rewrote in Rust, and half the Internet went down 53 days later.”
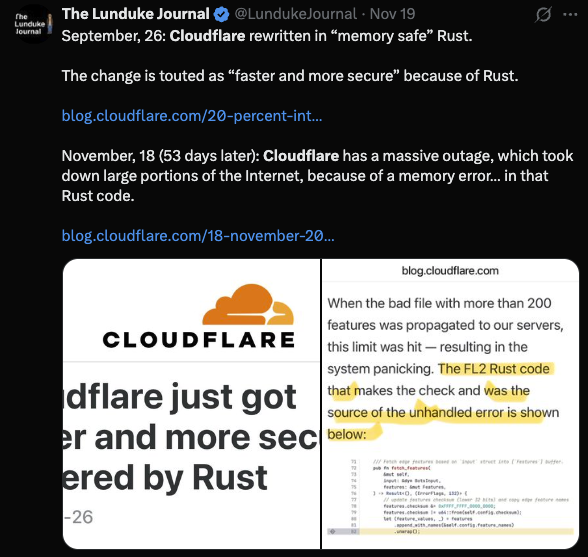
This inference is wrong, but emotionally satisfying.
People conflate correlation with causation because it creates a simple story: rewrites are dangerous.
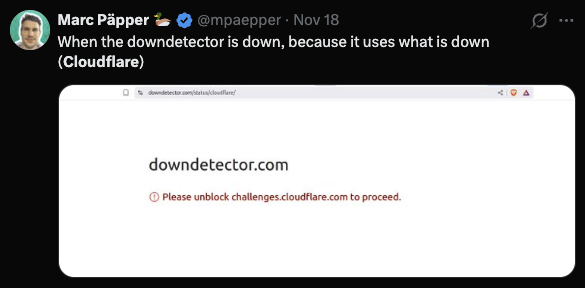
4.4 The Irony of Downdetector Being Down
The screenshot of Downdetector depending on Cloudflare and therefore failing is both funny and revealing. This outage demonstrated how deeply intertwined modern platforms are. It is an ecosystem issue, not a Cloudflare issue.
4.5 But There Were Also Good Takes
Kelly Sommers’ observation that Cloudflare published source code is a reminder that not everyone jumped to outrage.

There were pockets of maturity. Unfortunately, they were quieter than the noise.
5. The Real Lessons for Engineering Leaders
This is the part worth reading slowly if you build distributed systems.
Lesson 1: Reliability Is an Architecture Choice, Not a Language Choice
You can build fragile systems in safe languages and robust systems in unsafe languages. Language is orthogonal to architectural resilience.
Lesson 2: Guardrails Matter More Than Guarantees
Rust gives memory safety.
It does not give correctness safety.
It does not give assumption safety.
It does not give rollout safety.
You cannot outsource judgment.
Lesson 3: Blast Radius Containment Is Everything
- Uniform rollouts are dangerous.
- Synchronous edge updates are dangerous.
- Large global fleets need layered fault domains.
Cloudflare knows this. This incident will accelerate their work here.
Lesson 4: Control Planes Must Be Resilient Under Their Worst Conditions
The control plane was unreachable when it was needed most. This is a classic distributed systems trap: the emergency mechanism relies on the unhealthy components.
Always test:
- rollback unavailability
- degraded network conditions
- inconsistent state recovery
Lesson 5: Complexity Fails in Complex Ways
The system behaved exactly as designed. That is the problem.
Emergent behaviour in large networks cannot be reasoned about purely through local correctness.
This is where most teams misjudge their risk.
6. Additional Lesson: Accountability and Transparency Are Strategic Advantages
This incident highlighted something deeper about Cloudflare’s culture.
They did not hide behind ambiguity.
They did not release a PR-approved statement with vague phrasing.
They published:
- the timeline
- the diagnosis
- the exact code
- the root cause
- the systemic contributors
- the ongoing mitigation plan
This level of transparency is uncomfortable. It puts the organisation under a microscope.
Yet it builds trust in a way no marketing claim can.
Transparency after failure is not just ethical. It is good engineering. Very few people highlighted including my man Gergely Orosz.
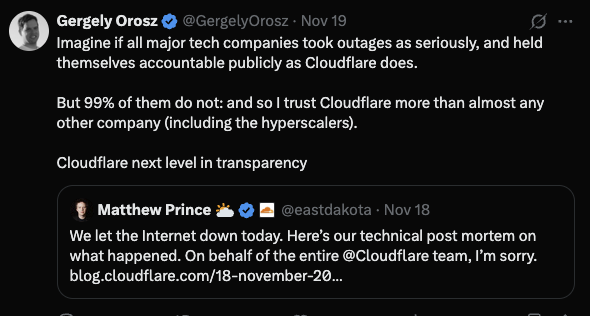
Most companies will never reach this level of accountability.
Cloudflare raised the bar.
7. What This Outage Tells Us About the State of the Internet
This was not a Cloudflare problem, This is a reminder of our shared dependency.
- Too much global traffic flows through too few choke points.
- Too many systems assume perfect availability from upstream.
- Too many platforms synchronise their rollouts.
- Too many companies run on infrastructure they did not build and cannot control.
The memes were not wrong.
They were simply incomplete.
8. Final Thoughts: Rust Did Not Fail. Our Assumptions Did.
Outages like this shape the future of engineering. The worst thing the industry can do is learn the wrong lesson.
This was not:
- a Rust failure
- a rewrite failure
- an open source failure
- a Cloudflare hubris story
This was a systems-thinking failure.
A reminder that assumptions are the most fragile part of any distributed system.
A demonstration of how tightly coupled global infrastructure has become.
A case study in why architecture always wins over language debates.
Cloudflare’s transparency deserves respect.
Their engineering culture deserves attention.
And the outrage cycle deserves better scepticism.
Because the Internet did not go down because of Rust.
It went down because the modern Internet is held together by coordination, trust, and layered assumptions that occasionally collide in surprising ways.
If we want a more resilient future, we need less blame and more understanding.
Less certainty and more curiosity.
Less language tribalism and more systems design thinking.
The Internet will fail again.
The question is whether we learn or react.
Cloudflare learned. The rest of us should too!