Hidden Threats in PyPI and NPM: What You Need to Know
Introduction: Dependency Dangers in the Developer Ecosystem
Modern software development is fuelled by open-source packages, ranging from Python (PyPI) and JavaScript (npm) to PHP (phar) and pip modules. These packages have revolutionised development cycles by providing reusable components, thereby accelerating productivity and creating a rich ecosystem for innovation. However, this very reliance comes with a significant security risk: these widely used packages have become an attractive target for cybercriminals. As developers seek to expedite the development process, they may overlook the necessary due diligence on third-party packages, opening the door to potential security breaches.
Faster Development, Shorter Diligence: A Security Conundrum
Today, shorter development cycles and agile methodologies demand speed and flexibility. Continuous Integration/Continuous Deployment (CI/CD) pipelines encourage rapid iterations and frequent releases, leaving little time for the verification of every dependency. The result? Developers often choose dependencies without conducting rigorous checks on package integrity or legitimacy. This environment creates an opening for attackers to distribute malicious packages by leveraging popular repositories such as PyPI, npm, and others, making them vectors for harmful payloads and information theft.
Malicious Package Techniques: A Deeper Dive
While typosquatting is a common technique used by attackers, there are several other methods employed to distribute malicious packages:
- Supply Chain Attacks: Attackers compromise legitimate packages by gaining access to the repository or the maintainer’s account. Once access is obtained, they inject malicious code into trusted packages, which then get distributed to unsuspecting users.
- Dependency Confusion: This technique involves uploading packages with names identical to internal, private dependencies used by companies. When developers inadvertently pull from the public repository instead of their internal one, they introduce malicious code into their projects. This method exploits the default behaviour of package managers prioritising public over private packages.
- Malicious Code Injection: Attackers often inject harmful scripts directly into a package’s source code. This can be done by compromising a developer’s environment or using compromised libraries as dependencies, allowing attackers to spread the malicious payload to all users of that package.
These methods are increasingly sophisticated, leveraging the natural behaviours of developers and package management systems to spread malicious code, steal sensitive information, or compromise entire systems.
Timeline of Incidents: Malicious Packages in the Spotlight
A series of high-profile incidents have demonstrated the vulnerabilities inherent in unchecked package installations:
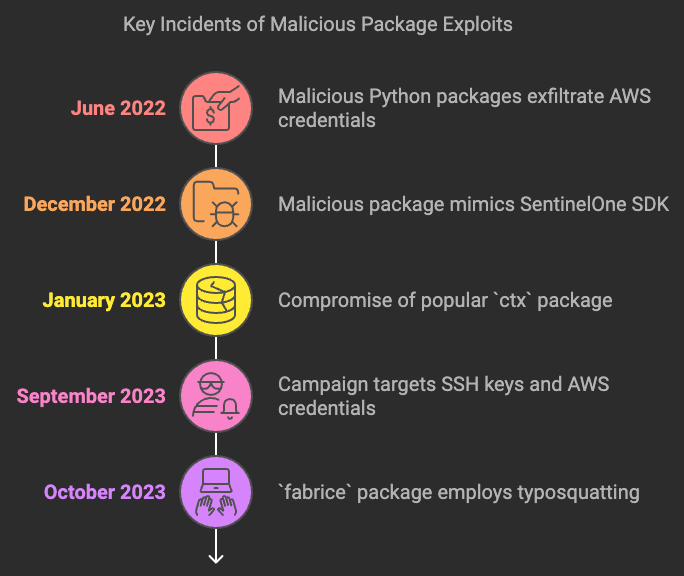
- June 2022: Malicious Python packages such as
loglib-modules,pyg-modules,pygrata,pygrata-utils, andhkg-sol-utilswere caught exfiltrating AWS credentials and sensitive developer information to unsecured endpoints. These packages were disguised to look like legitimate tools and fooled many unsuspecting developers. (BleepingComputer) - December 2022: A malicious package masquerading as a SentinelOne SDK was uploaded to PyPI, with malware designed to exfiltrate sensitive data from infected systems. (The Register)
- January 2023: The popular
ctxpackage was compromised to steal environment variables, including AWS keys, and send them to a remote server. This instance affected many developers and highlighted the scale of potential data leakage through dependencies. (BleepingComputer) - September 2023: An extended campaign involving malicious npm and PyPI packages targeted developers to steal SSH keys, AWS credentials, and other sensitive information, affecting numerous projects globally. (BleepingComputer)
- October 2023: The recent incident involving the
fabricepackage is a stark reminder of how easy it is for attackers to deceive developers. Thefabricepackage, designed to mimic the legitimatefabriclibrary, employed a typosquatting strategy, exploiting typographical errors to infiltrate systems. Since its release, the package was downloaded over 37,000 times and covertly collected AWS credentials using theboto3library, transmitting the stolen data to a remote server via VPN, thereby obscuring the true origin of the attack. The package contained different payloads for Linux and Windows systems, utilising scheduled tasks and hidden directories to establish persistence. (Developer-Tech)
The Impact: Scope of Compromise
The estimated number of affected companies and products is difficult to pin down precisely due to the widespread usage of open-source packages in both small-scale and enterprise-level applications. Given that some of these malicious packages garnered tens of thousands of downloads, the potential damage stretches across countless software projects. With popular packages like ctx and others reaching a substantial audience, the economic and reputational impact could be significant, potentially costing affected businesses millions in breach recovery and remediation costs.
Real-world Impact: Consequences of Malicious Packages
The real-world impact of malicious packages is profound, with consequences ranging from data breaches to financial loss and severe reputational damage. The following are some of the key impacts:
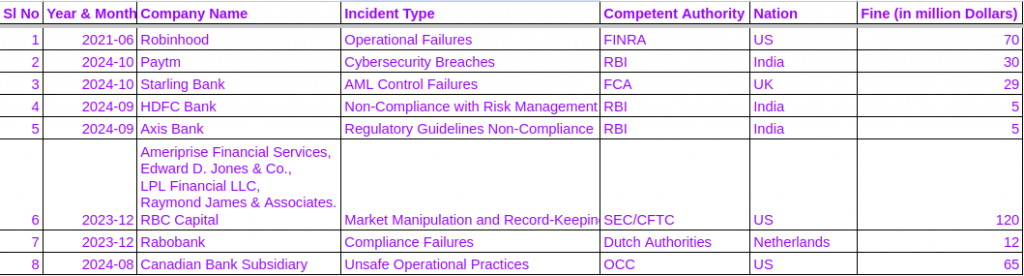
- British Airways and Ticketmaster Data Breach: In 2018, the Magecart group exploited vulnerabilities in third-party scripts used by British Airways and Ticketmaster. The attackers injected malicious code to skim payment details of customers, leading to significant data breaches and financial loss. British Airways was fined £20 million for the breach, which affected over 400,000 customers. (BBC)
- Codecov Bash Uploader Incident: In April 2021, Codecov, a popular code coverage tool, was compromised. Attackers modified the Bash Uploader script, which is used to send coverage reports, to collect sensitive information from Codecov’s users, including credentials, tokens, and keys. This supply chain attack impacted hundreds of customers, including notable companies like HashiCorp. (GitGuardian)
- Event-Stream NPM Package Attack: In 2018, a popular JavaScript library
event-streamwas hijacked by a malicious actor who added code to steal cryptocurrency from applications using the library. The compromised version was downloaded millions of times before the attack was detected, affecting numerous developers and projects globally. (Synk)
These incidents highlight the potential repercussions of malicious packages, including severe financial penalties, reputational damage, and the theft of sensitive customer information.
Fabrice: A Case Study in Typosquatting
The recent incident involving the fabrice package is a stark reminder of how easy it is for attackers to deceive developers. The fabrice package, designed to mimic the legitimate fabric library, employed a typosquatting strategy, exploiting typographical errors to infiltrate systems. Since its release, the package was downloaded over 37,000 times and covertly collected AWS credentials using the boto3 library, transmitting the stolen data to a remote server via VPN, thereby obscuring the true origin of the attack. The package contained different payloads for Linux and Windows systems, utilising scheduled tasks and hidden directories to establish persistence. (Developer-Tech)
Lessons Learned: Importance of Proactive Security Measures
The cases highlighted in this article offer important lessons for developers and organisations:
- Dependency Verification is Crucial: Typosquatting and dependency confusion can be avoided by carefully verifying package authenticity. Implementing strict naming conventions and utilising internal package repositories can help prevent these attacks.
- Security Throughout the SDLC: Integrating security checks into every phase of the SDLC, including automated code reviews and security testing of modules, is essential. This ensures that vulnerabilities are identified early and mitigated before reaching production.
- Use of Vulnerability Scanning Tools: Tools like
SnykandOWASP Dependency-Checkare invaluable in proactively identifying vulnerabilities. Organisations should make these tools a mandatory part of the development process to mitigate risks from third-party dependencies. - Security Training and Awareness: Developers must be educated about the risks associated with third-party packages and taught how to identify potentially malicious code. Regular training can significantly reduce the likelihood of falling victim to these attacks.
By recognising these lessons, developers and organisations can better safeguard their software supply chains and mitigate the risks associated with third-party dependencies.
Prevention Strategies: Staying Safe from Malicious Packages
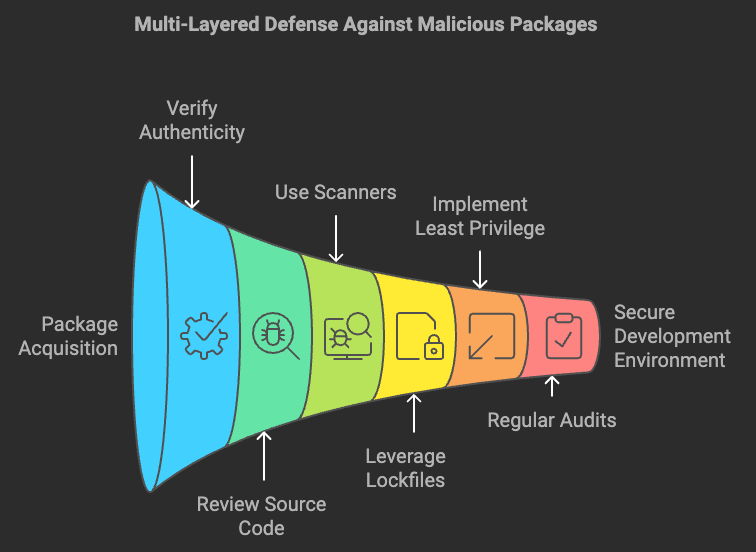
To mitigate the risks associated with malicious packages, developers and startups must adopt a multi-layered defence approach:
- Verify Package Authenticity: Always verify package names, descriptions, and maintainers. Opt for well-reviewed and frequently updated packages over relatively unknown ones.
- Review Source Code: Whenever possible, review the source code of the package, especially for dependencies with recent uploads or unknown maintainers.
- Use Package Scanners: Employ tools like
Sonatype Nexus,npm audit, orPyUpto identify vulnerabilities and malicious code within packages. - Leverage Lockfiles: Tools like
package-lock.json(npm) orPipfile.lock(pip) can help prevent unintended updates by locking dependencies to a specific version. - Implement Least Privilege: Limit the permissions assigned to development environments to reduce the impact of compromised keys or credentials.
- Regular Audits: Conduct regular security audits of dependencies as part of the CI/CD pipeline to minimise risk.
Software Security: Embedding Security in the Development Lifecycle
To mitigate the risks associated with malicious packages and other vulnerabilities, it is essential to integrate security into every phase of the Software Development Lifecycle (SDLC). This practice, known as the Secure Software Development Lifecycle (SSDLC), emphasises incorporating security best practices throughout the development process.
Key Components of SSDLC
- Automated Code Reviews: Leveraging tools that automatically scan code for vulnerabilities and flag potential issues early in the development cycle can significantly reduce the risk of security flaws making it into production. Tools like SonarQube, Checkmarx, and Veracode help in ensuring that security is built into the code from the beginning.
- Security Testing of Modules: Security testing should be conducted on third-party modules before integrating them into the project. Tools like Snyk and OWASP Dependency-Check can identify vulnerabilities in dependencies and provide remediation advice.
Deep Dive into Technical Details
- Malicious Package Techniques: As discussed earlier, typosquatting is just one of the many attack techniques. Supply chain attacks, dependency confusion, and malicious code injection are also common methods attackers use to compromise software projects. It is essential to understand these techniques and incorporate checks that can prevent such attacks during the development process.
- Vulnerability Analysis Tools:
- Snyk: Snyk helps developers identify vulnerabilities in open-source libraries and container images. It scans the project dependencies and cross-references them with a constantly updated vulnerability database. Once vulnerabilities are identified, Snyk provides detailed remediation advice, including fixing the version or applying patches.
- OWASP Dependency-Check: OWASP Dependency-Check is an open-source tool that scans project dependencies for known vulnerabilities. It works by identifying the libraries used in the project, then checking them against the National Vulnerability Database (NVD) to highlight potential risks. The tool also provides reports and actionable insights to help developers remediate the issues.
- Sonatype Nexus: Sonatype Nexus offers a repository management system that integrates directly with CI/CD pipelines to scan for vulnerabilities. It uses machine learning and other advanced techniques to continuously monitor and evaluate open-source libraries, providing alerts and remediation options.
Best Practices for Secure Dependency Management
- Dependency Pinning: Pinning dependencies to specific versions helps in preventing unexpected updates that may contain vulnerabilities. By using tools like
package-lock.json(npm) orPipfile.lock(pip), developers can ensure that they are not inadvertently upgrading to a compromised version of a dependency. - Use of Private Registries: Hosting private package registries allows organisations to maintain tighter control over the dependencies used in their projects. By using tools like Nexus Repository or Artifactory, companies can create a trusted repository of dependencies and mitigate risks associated with public registries.
- Robust Security Policies: Organisations should implement strict policies around the use of open-source components. This includes performing security audits, using automated tools to scan for vulnerabilities, and enforcing review processes for any new dependencies being added to the codebase.
By integrating these practices into the development process, organisations can build more resilient software, reduce vulnerabilities, and prevent incidents involving malicious dependencies.
Conclusion
As the developer community continues to embrace rapid innovation, understanding the security risks inherent in third-party dependencies is crucial. Adopting preventive measures and enforcing better dependency management practices are vital to mitigate the risks of malicious packages compromising projects, data, and systems. By recognising these threats, developers and startups can secure their software supply chains and build more resilient products.
References & Further Reading
- BleepingComputer: PyPI Python Packages Caught Sending Stolen AWS Keys to Unsecured Sites
- BleepingComputer: Popular Python and PHP Libraries Hijacked to Steal AWS Keys
- The Register: PyPI Malware Disguised as SentinelOne SDK
- BleepingComputer: SSH Keys Stolen by Malicious PyPI and npm Packages
- Developer-Tech: Python Package Fabrice Steals AWS Credentials
- BBC: British Airways Fined Over Data Breach
- Reuters: Codecov Hacked
- Wired: NPM Event-Stream Hack