What is the Latest React Router Vulnerability And What Every Founder Should Know?
Today the cybersecurity world woke up to another reminder that even the tools we trust most can become security landmines. A critical vulnerability in React Router, one of the most widely-used routing libraries in modern web development, was disclosed, and the implications go far beyond the frontend codebase.
This isn’t a “just another bug.” At a CVSS 9.8 severity level, attackers can perform directory traversal through manipulated session cookies, effectively poking around your server’s filesystem if your app uses the affected session storage mechanism.
Let’s unpack why this matters for founders, CTOs, and builders responsible for secure product delivery.
What Happened?
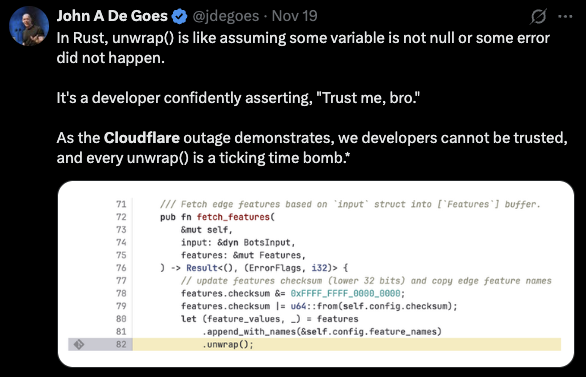
React Router recently patched a flaw in the createFileSessionStorage() module that — under specific conditions — lets attackers read or modify files outside their intended sandbox by tampering with unsigned cookies.
Here’s the risk profile:
- Attack vector: directory traversal via session cookies
- Severity: Critical (9.8 CVSS)
- Impact: Potential access to sensitive files and server state
- Affected packages:
@react-router/nodeversions 7.0.0 — 7.9.3@remix-run/denoand@remix-run/nodebefore 2.17.2
While attackers can’t immediately dump any file on the server, they can navigate the filesystem in unintended ways and manipulate session artifacts — a serious foot in the door.
The takeaway: vulnerability isn’t constrained to toy apps. If you’re running SSR, session-based routing, or Remix integrations, this hits your stack.
Why This Is a Leadership Problem — Not Just a Dev One
As founders, we’re often tempted to treat vulnerabilities like IT ops tickets: triage it, patch it, close it. But here’s the real issue:
Risk isn’t just technical — it’s strategic.
Modern web apps are supply chains of open-source components. One shipped package version can suddenly create a path for adversaries into your server logic. And as we’ve seen with other critical bugs this year — like the “React2Shell” RCE exploited millions of times in the wild — threat actors are automated, relentless, and opportunistic.
Your roadmap priorities — performance, feature velocity, UX — don’t matter if an attacker compromises your infrastructure or exfiltrates configuration secrets. Vulnerabilities like this are business continuity issues. They impact uptime, customer trust, compliance, and ultimately — revenue.
The Broader React Ecosystem Risk
This isn’t the first time React-related tooling has made headlines:
- The React Server Components ecosystem suffered a critical RCE vulnerability (CVE-2025-55182, aka “React2Shell”) late last year, actively exploited in the wild.
- Multiple states and nation-linked threat groups were observed scanning for and abusing RSC flaws within hours of disclosure.
If your product stack relies on React, Remix, Next.js, or the broader JavaScript ecosystem — you’re in a high-traffic attack corridor. These libraries are ubiquitous, deeply integrated, and therefore lucrative targets.
What You Should Do Right Now
Here’s a practical, founder-friendly checklist you can action with your engineering team:
✅ 1. Patch Immediately
Update to the patched versions:
@react-router/node→ 7.9.4+@remix-run/deno&@remix-run/node→ 2.17.2+
No exceptions.
🚨 2. Audit Session Handling
Review how your app uses unsigned cookies and session storage. Directory traversal flaws often succeed where path validation is assumed safe but not enforced.
🧠 3. Monitor for Suspicious Activity
Look for unusual session tokens, spikes in directory access patterns, or failed login anomalies. Early detection beats post-incident firefighting.
🛡 4. Bolster Your Dependency Management
Consider automated dependency scanners, SBOMs (Software Bill of Materials), and patch dashboards integrated into your CI/CD.
🗣 5. Educate the Team
Foundational libraries are as much a security concern as your application logic — upskill your developers to treat component updates like risk events.
Final Thought
Security isn’t a checkbox. It’s a continuous posture, especially in ecosystems like JavaScript where innovation and risk walk hand in hand.
The React Router vulnerability should be your wake-up call: your code is only as secure as the libraries you trust. Every build, every deploy, every npm install carries weight.
Patch fast, architect sensibly, monitor intelligently, not just for this bug, but for the next one that’s already being scanned on port 443.
Stay vigilant.
— Your co-founder in code and risk