Why One AWS Spot Still Crashes Sites In 2025?
It started innocently enough. Morning coffee, post-workout calm, a quick “Computer, drop in on my son.”
Instead of his sleepy grin, I got the polite but dreaded:
“There is an error. Please try again later.”
-Alexa (i call it “Computer” as a wannabe Capt of NCC1701E)
Moments later, I realised it wasn’t my internet or device. It was AWS again.
A Familiar Failure in a Familiar Region
If the cloud has a heartbeat, it beats somewhere beneath Northern Virginia.
That is the home of US-EAST-1, Amazon Web Services’ oldest and busiest region, and the digital crossroad through which a large share of the internet’s authentication, routing, and replication flows. It is also the same region that keeps reminding the world that redundancy and resilience are not the same thing.
In December 2022, a cascading power failure at US-EAST-1 set off a chain of interruptions that took down significant parts of the internet, including internal AWS management consoles. Engineers left that incident speaking of stronger isolation and better regional independence.
Three years later, the lesson has returned. The cause may differ, but the pattern feels the same.
The Current Outage
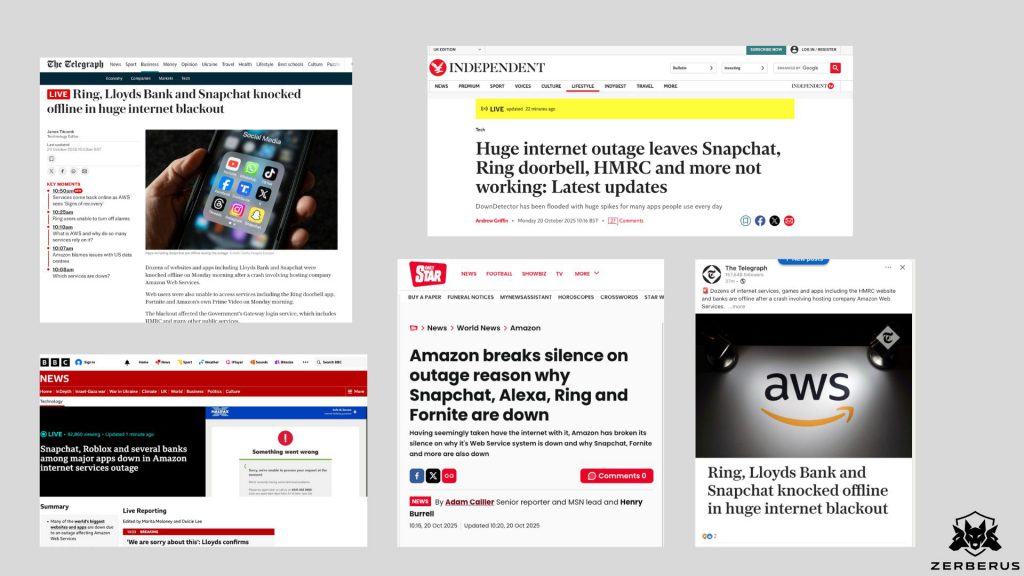
As of this afternoon, AWS continues to battle a widespread disruption in US-EAST-1. The issue began early on 20 October 2025, with elevated error rates across DynamoDB, Route 53, and related control-plane components.
The impact has spread globally.
- Snapchat, Ring, and Duolingo have reported downtime.
- Lloyds Bank and several UK financial platforms are seeing degraded service.
- Even Alexa devices have stopped responding, producing the same polite message: “There is an error. Please try again later.”
For anyone who remembers 2022, it feels uncomfortably familiar. The more digital life concentrates in a handful of hyperscale regions, the more we all share the consequences when one of them fails.
The Pattern Beneath the Problem
Both the 2022 and 2025 US-EAST-1 events reveal the same architectural weakness: control-plane coupling.
Workloads may be distributed across regions, yet many still rely on US-EAST-1 for:
- IAM token validation
- DynamoDB global tables metadata
- Route 53 DNS propagation
- S3 replication management
When that single region falters, systems elsewhere cannot authenticate, replicate, or even resolve DNS. The problem is not the hardware; it is that so many systems rely on a single control layer.
What makes today’s event more concerning is how little has changed since the last one. The fragility is known, yet few businesses have redesigned their architectures to reduce the dependency.
How Zerberus Responded to the Lesson
When we began building Zerberus, we decided that no single region or provider should ever be critical to our uptime. That choice was not born from scepticism but from experience in building 2 other platforms that had millions of users across 4 continents.
Our products, Trace-AI, ComplAI™, and ZSBOM, deliver compliance and security automation for organisations that cannot simply wait for the cloud to recover. We chose to design for failure as a permanent condition rather than a rare event.
Inside the Zerberus Architecture
Our production environment operates across five regions: London, Ireland, Frankfurt, Oregon, and Ohio. The setup follows an active-passive pattern with automatic failover.
Two additional warm standby sites receive limited live traffic through Cloudflare load balancers. When one of these approaches a defined load threshold, it scales up and joins the active pool without manual intervention.
Multi-Cloud Distribution
- AWS runs the primary compute and SBOM scanning workloads.
- Azure carries the secondary inference pipelines and compliance automation modules.
- Digital Ocean maintains an independent warm standby, ensuring continuity even if both AWS and Azure suffer regional difficulties.
This diversity is not a marketing exercise. It separates operational risk, contractual dependence, and control-plane exposure across multiple vendors.
Network Edge and Traffic Management
At the edge, Cloudflare provides:
- Global DNS resolution and traffic steering
- Web application firewalling and DDoS protection
- Health-based routing with zero-trust enforcement
By externalising DNS and routing logic from AWS, we avoid the single-plane dependency that is now affecting thousands of services.
Data Sovereignty and Isolation
All client data remains within each client’s own VPC. Zerberus only collects aggregated pass/fail summaries and compliance evidence metadata.
Databases replicate across multiple Availability Zones, and storage is separated by jurisdiction. UK data remains in the UK; EU data remains in the EU. This satisfies regulatory boundaries and limits any failure to its own region.
Observability and Auto-Recovery
Telemetry is centralised in Grafana, while Cloudflare health checks trigger regional routing changes automatically.
If a scanning backend becomes unavailable, queued SBOM analysis tasks shift to a healthy region within seconds.
Even during an event such as the present AWS disruption, Zerberus continues to operate—perhaps with reduced throughput, but never completely offline.
Learning from 2022
The 2022 outage made clear that availability zones do not guarantee availability. The 2025 incident reinforces that message.
At Zerberus, we treat resilience as a practice, not a promise. We simulate network blackouts, DNS failures, and database unavailability. We measure recovery time not in theory but in behaviour. These tests are themselves automated(monitored), because the cost of complacency is always greater than the cost of preparation.
Regulation and Responsibility
Europe’s Cyber Resilience Act and NIS2 Directive are closing the gap between regulatory theory and engineering reality. Resilience is no longer an optional control; it is a legal expectation.
A multi-region, multi-cloud, data-sovereign architecture is now both a technical and regulatory necessity. If a hyperscaler outage can lead to non-compliance, the responsibility lies in design, not in the service-level agreement.
Designing for the Next Outage
US-EAST-1 will recover; it always does. The question is how many services will redesign themselves before the next event.
Every builder now faces a decision: continue to optimise for convenience or begin engineering for continuity.
The 2022 failure served as a warning. The 2025 outage confirms the lesson. By the next one, any excuse will sound outdated.
Final Thoughts
The cloud remains one of the greatest enablers of our age, but its weaknesses are equally shared. Each outage offers another chance to refine, distribute, and fortify what we build.
At Zerberus, we accept that the cloud will falter from time to time. Our task is to ensure that our systems, and those of our clients, do not falter with it.
🟩 Author: Ramkumar Sundarakalatharan
Founder & Chief Architect, Zerberus Technologies Ltd
(This article reflects an ongoing incident. For live updates, refer to the AWS Status Page and technology news outlets such as BBC Tech and The Independent.)
References:
https://www.bbc.co.uk/news/live/c5y8k7k6v1rt
https://www.independent.co.uk/tech/aws-amazon-internet-outage-latest-updates-b2848345.html
https://www.dailystar.co.uk/news/world-news/amazon-breaks-silence-outage-reason-36096705
