Governance by Design: Real-Time Policy Enforcement for Edge AI Systems
The Emerging Problem of Autonomous Drift
For most of the past decade, AI governance relied on a comfortable assumption: the system was always connected.
Logs flowed to the cloud.
Monitoring systems analysed behaviour.
Security teams reviewed anomalies after deployment.
That assumption is increasingly invalid.
By 2026, AI systems are moving rapidly from the cloud to the edge. Autonomous drones, warehouse robots, inspection vehicles, agricultural systems, and industrial machines now execute sophisticated models locally. These systems frequently operate in environments where connectivity is intermittent, degraded, or intentionally disabled.
Traditional governance models break down under these conditions.
Cloud-based monitoring pipelines were designed to detect violations, not prevent them. If a warehouse robot crosses a restricted safety zone, the cloud log may capture the event seconds later. The physical consequence has already occurred.
This gap introduces a new operational risk: autonomous drift.
Autonomous drift occurs when the operational behaviour of an AI system gradually diverges from the safety assumptions embedded in its original training or certification.
Consider a warehouse robot tasked with optimising throughput.
Over time, reinforcement signals favour shorter routes between shelves. The system begins to treat a marked safety corridor, reserved for human operators, as a shortcut during low-traffic periods. The robot’s navigation model still behaves rationally according to its optimisation objective. However, the behaviour now violates safety policy.
If governance relies solely on cloud logging, the violation is recorded after the robot has already entered the human safety corridor.
The real governance challenge is therefore not visibility.
It is control at the moment of decision.
Governance by Design
Governance by Design addresses this challenge by embedding enforceable policy constraints directly into the operational architecture of autonomous systems.
Traditional governance frameworks rely heavily on documentation artefacts:
- compliance policies
- acceptable use guidelines
- model cards
- post-incident audit reports
These artefacts guide behaviour but do not actively control it.
Governance by Design introduces a different model.
Safety constraints are implemented as runtime enforcement mechanisms that intercept system actions before execution.
When an AI agent proposes an action, a policy enforcement layer evaluates that action against predefined operational rules. Only actions that satisfy these rules are allowed to proceed.
This architectural approach converts governance from an advisory process into a deterministic control mechanism.
Architecture of the Lightweight Enforcement Engine
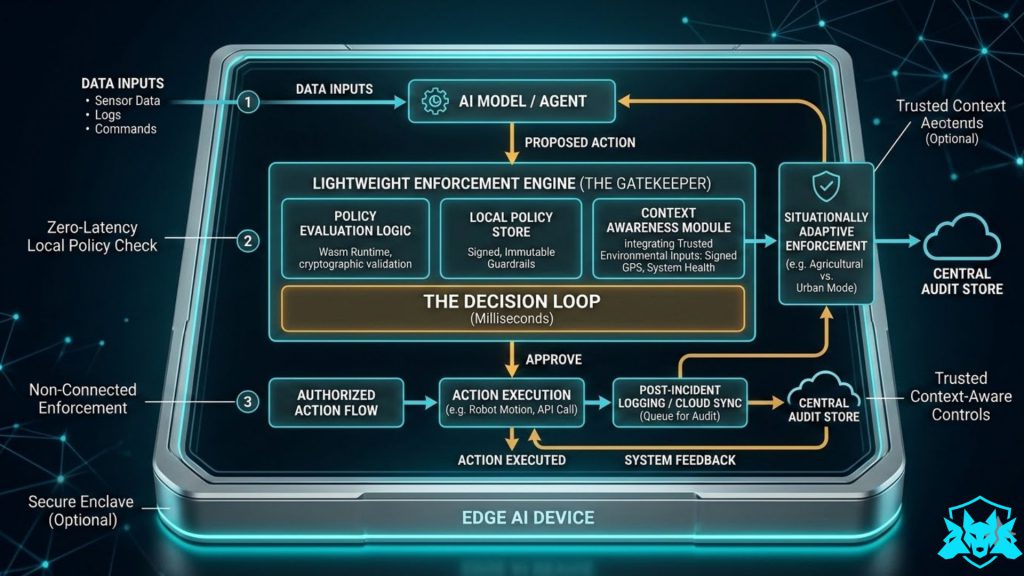
A runtime enforcement engine must meet three critical requirements:
- Sub-millisecond policy evaluation
- Isolation from the AI model
- Deterministic fail-safe behaviour
To achieve this, most edge governance architectures introduce a policy enforcement layer between the AI model and the system actuators.
Action Interception Layer
The enforcement engine intercepts decision outputs before they reach the execution layer.
This interception can occur at several architectural levels:
| Interception Layer | Example Implementation |
|---|---|
| Application API Gateway | policy checks applied before commands reach device APIs |
| Service Mesh Sidecar | policy enforcement injected between microservices |
| Hardware Abstraction Layer | command filtering before motor or actuator signals |
| Trusted Execution Environment | policy module executed within secure enclave |
In robotics platforms, this often appears as a command arbitration layer that sits between the decision engine and the control system.
Policy Evaluation Engine
The policy engine evaluates incoming actions against operational rules such as:
- geofencing restrictions
- physical safety limits
- operational permissions
- environmental constraints
To keep the system lightweight, policy modules are commonly executed using WebAssembly runtimes or minimal micro-kernel enforcement modules.
These runtimes provide:
- deterministic execution
- hardware portability
- sandbox isolation
- cryptographic policy verification
Policy Conflict Resolution
One practical challenge in runtime governance is policy conflict.
For example:
- A mission policy may instruct a drone to reach a target location.
- A safety policy may prohibit entry into restricted airspace.
The enforcement engine resolves these conflicts through a hierarchical precedence model.
A typical hierarchy might be:
- Human safety policies
- Regulatory compliance policies
- Operational safety constraints
- Mission objectives
- Performance optimisation rules
Under this hierarchy, mission commands cannot override safety rules.
The system therefore fails safely by design.
Local-First Verification
Edge systems cannot rely on remote governance.
Safety decisions must occur locally.
Local-first verification ensures that autonomous systems remain safe even when network connectivity is lost. The enforcement engine runs directly on the device, evaluating actions against policy rules using locally available context.
This architecture allows devices to respond to unsafe conditions within milliseconds.
If a drone approaches restricted airspace, the policy engine can override navigation commands immediately. If sensor inconsistencies indicate possible spoofing or mechanical failure, the enforcement layer can halt operations.
Cloud connectivity becomes secondary and is used primarily for:
- audit logging
- behavioural analytics
- policy distribution
Situationally Adaptive Enforcement
Autonomous systems frequently operate across environments with different risk profiles.
A drone operating in open farmland faces different safety requirements than one operating in dense urban airspace.
Situationally adaptive enforcement allows the policy engine to adjust operational constraints based on trusted environmental signals.
Environmental context can be determined using:
- GPS coordinates signed by trusted navigation modules
- sensor fusion from cameras, lidar, and radar
- geofencing databases
- broadcast environment beacons
- infrastructure proximity detection
These signals allow the enforcement engine to activate different policy profiles.
For example:
| Environment | Enforcement Profile |
|---|---|
| Industrial warehouse | equipment safety policies |
| Urban environment | strict collision avoidance + geofence |
| Agricultural field | reduced proximity restrictions |
Importantly, the AI system does not generate these rules.
It simply operates within them.
Governance Lessons from the Frontier AI Debate
Recent debates around the deployment of frontier AI models illustrate the limitations of policy-driven governance.
In early 2026, Anthropic reiterated restrictions preventing its models from being used in fully autonomous weapons systems, reportedly complicating collaboration with defence organisations seeking greater operational autonomy from AI platforms.
The debate highlights a structural issue.
Once AI capabilities are embedded into downstream systems, the original developer no longer controls how those systems are used. Acceptable-use policies and contractual restrictions are difficult to enforce once models are integrated into operational environments.
Governance therefore becomes an architectural problem.
If safety constraints exist only as policy statements, they can be bypassed. If they exist as enforceable runtime controls, the system becomes structurally incapable of violating those constraints.
Regulatory Alignment
This architectural shift aligns closely with emerging regulatory expectations.
The EU AI Act requires high-risk AI systems to demonstrate:
- robustness and reliability
- effective risk management
- human oversight
- cybersecurity protections
Runtime policy enforcement directly supports these requirements.
| Regulatory Requirement | Governance by Design Feature |
|---|---|
| Human oversight | policy engine enforces supervisory constraints |
| Robustness | deterministic safety guardrails |
| Cybersecurity | isolated enforcement runtime |
| Risk mitigation | local policy enforcement |
Similarly, the Cyber Resilience Act requires digital products to incorporate security controls throughout their lifecycle.
Runtime enforcement architectures fulfil this expectation by ensuring safety constraints remain active even after deployment.
Implementing Governance Layers in Practice
Several emerging platforms implement elements of this architecture today.
For example, within the Zerberus security architecture, governance operates as an active runtime layer rather than a passive compliance artefact.
- RAGuard-AI enforces policy boundaries in retrieval-augmented AI pipelines, preventing unsafe or adversarial data from entering model decision processes.
- Judge-AI evaluates agent behaviour continuously against operational policies, providing behavioural verification for autonomous systems.
These systems illustrate how governance mechanisms can operate directly within AI runtime environments rather than relying solely on external monitoring.
Traditional Governance vs Governance by Design
| Feature | Traditional AI Governance | Governance by Design |
|---|---|---|
| Enforcement timing | Post-incident | Real time |
| Connectivity requirement | Continuous cloud connection | Local first |
| Policy location | Documentation | Executable policy modules |
| Response latency | Seconds to minutes | Milliseconds |
| Control model | Audit and review | Deterministic enforcement |
Conclusion
As AI systems increasingly interact with the physical world, governance cannot remain purely procedural.
Monitoring dashboards and compliance documentation remain necessary. However, they are insufficient when autonomous systems operate at machine speed in distributed environments.
Trustworthy AI will depend on architectures that enforce safety constraints directly within operational systems.
In other words, the future of AI governance will not be determined solely by policies or promises.
It will be determined by what autonomous systems are technically prevented from doing.

