The Axios Supply Chain Compromise: A Post-Mortem on Infrastructure Trust, Nation-State Proxy Warfare, and the Fragility of Modern JavaScript Ecosystems
TL:DR: This is a Developing Situation and I will try to update it as we dissect more. If you’d prefer the remediation protocol directly, you can head to the bottom. In case you want to understand the anatomy of the attack and background, I have made a video that can be a quick explainer.
The software supply chain compromise of the Axios npm package in late March 2026 stands as a definitive case study in the escalating complexity of cyber warfare targeting the foundations of global digital infrastructure.1 Axios, an ubiquitous promise-based HTTP client for Node.js and browser environments, serves as a critical abstraction layer for over 100 million weekly installations, facilitating the movement of sensitive data across nearly every major industry.1 On March 31, 2026, this trusted utility was weaponised by threat actors through a sophisticated account takeover and the injection of a cross-platform Remote Access Trojan (RAT), exposing a vast blast radius of developer environments, CI/CD pipelines, and production clusters to state-sponsored espionage.2 The incident represents more than a localized breach of an npm library; it is a manifestation of the “cascading” supply chain attack model, where the compromise of a single maintainer cascades into the theft of thousands of high-value credentials, including AWS keys, SSH credentials, and OAuth tokens, which are then leveraged for further lateral movement within corporate and government networks.6 This analysis reconstructs the technical anatomy of the attack, explores the operational tradecraft of the adversary, and assesses the structural vulnerabilities in registry infrastructure that allowed such a breach to bypass modern security gates like OIDC-based Trusted Publishing.6
The Architectural Criticality of Axios and the Magnitude of the Blast Radius
The positioning of Axios within the modern software stack creates a high-density target for supply chain poisoning. As a library that manages the “front door” of network communication for applications, it is inherently granted access to sensitive environment variables, authentication headers, and API secrets.1 The March 31 compromise targeted this architectural criticality by poisoning the very mechanism of installation.2

The blast radius of this incident was significantly expanded by the library’s role as a transitive dependency. Countless other npm packages, orchestration tools, and automated build scripts pull Axios as a secondary or tertiary requirement.3 Consequently, organisations that do not explicitly use Axios in their primary codebases were still vulnerable if their build systems resolved to the malicious versions, 1.14.1 or 0.30.4, during the infection window.1 This “hidden” exposure is a hallmark of modern supply chain risk, where the attack surface is not merely your code, but your vendor’s vendor’s vendor.2
The Anatomy of the Poisoning: Technical Construction of plain-crypto-js
The compromise was executed not by modifying the Axios source code itself, which might have been caught by source-control monitoring or automated diffs; but by manipulating the registry metadata to include a “phantom dependency” named [email protected]. This dependency was never intended to provide cryptographic functionality; it served exclusively as a delivery vehicle for the initial stage dropper.6
The attack began when a developer or an automated CI/CD agent executed npm install.6 The npm registry resolved the dependency tree, identified the malicious Axios version, and automatically fetched [email protected].6. Upon installation, the package triggered a postinstall hook defined in its package.json, executing the command node setup.js.6 This script functioned as the primary dropper, utilising a sophisticated obfuscation scheme to hide its intent from static analysis tools.5
The setup.js script utilised a two-layer encoding mechanism. The first layer involved a string reversal and a modified Base64 decoder where standard padding characters were replaced with underscores.5 The second layer employed a character-wise XOR cipher with a key derived from the string “OrDeR_7077”.5 The logic for the decryption can be represented mathematically. Let be the array of obfuscated character codes and
be the derived key array. The character index for the XOR operation is calculated as:
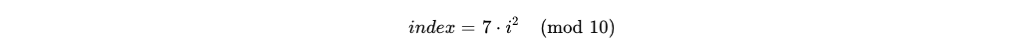
Where is the current character position in the string being decrypted. 5 This position-dependent transformation ensured that even if a security tool identified a repeating key pattern, the actual character transformation would vary non-linearly across the string.5
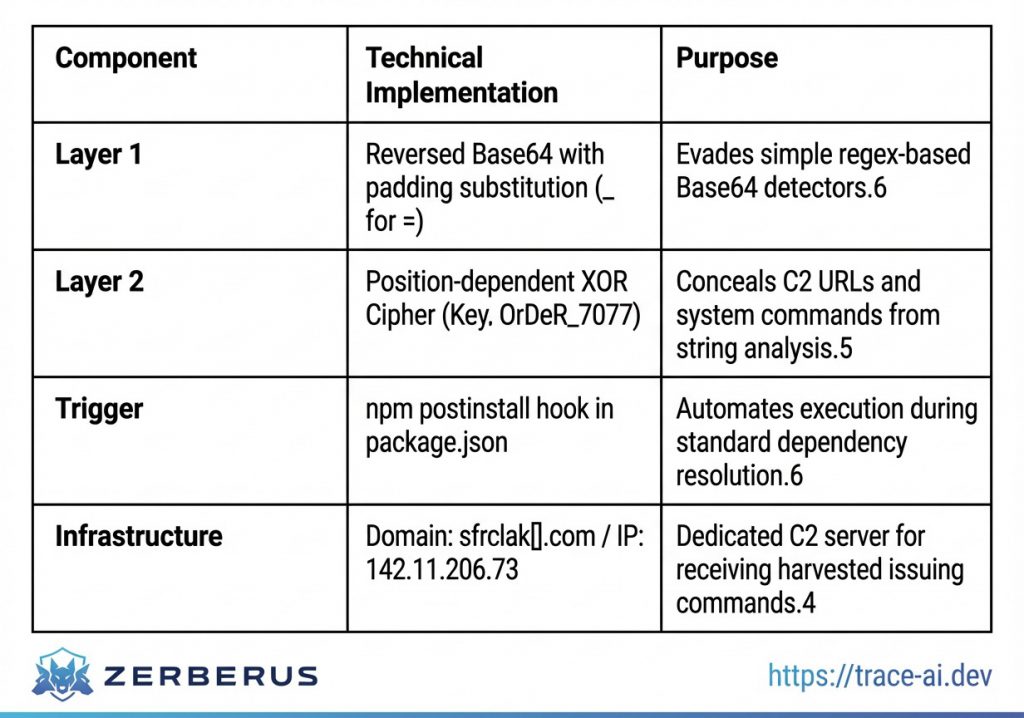
The dropper’s primary function was to identify the host operating system via the os.platform() module and download the corresponding second-stage RAT binary from the C2 server.6 This stage demonstrated high operational maturity, providing specific payloads for Windows, macOS, and Linux, ensuring that no developer workstation would be exempt from the infection chain.5
The Discovery Narrative: From Automated Scanners to Community Alarms
The identification of the Axios compromise was not the result of a single security failure, but rather a coordinated response between automated monitoring systems and the broader cybersecurity community.5 The earliest indications of the breach emerged on March 30, 2026, when researchers at Elastic Security Labs detected anomalous registry activity.5. Automated monitors flagged a significant change in the project’s metadata: the registered email for lead maintainer jasonsaayman was abruptly changed from a legitimate Gmail address to the attacker-controlled [email protected].5This discovery triggered a rapid forensic investigation. Researchers noted that while previous legitimate versions of Axios were published using GitHub Actions OIDC with SLSA provenance attestations, the malicious versions, 1.14.1 and 0.30.4, were published directly via the npm CLI.3 This shift in publishing methodology provided the first evidence of an account takeover.3 By 01:50 AM UTC on March 31, 2026, a GitHub Security Advisory was filed, and the coordination between Axios maintainers and the npm registry began in earnest to remove the poisoned packages.5

Despite the relatively short duration of the infection window (approximately three hours), the impact was profound.2 Automated build systems, particularly those that do not use pinned dependencies or committed lockfiles, pulled the malicious releases immediately upon their publication.2 The “two-hour window” between publication and removal was sufficient for the attackers to establish persistence on thousands of systems, highlighting the fundamental problem with reactive security: IOCs often arrive after the initial objective of the attacker has already been realised.2
The Adversary Persona: BlueNoroff and the Lazarus Connection
The technical signatures and infrastructure used in the Axios attack allow for high-confidence attribution to BlueNoroff, a prominent subgroup of the North Korean Lazarus Group.16 BlueNoroff, also tracked as Jade Sleet and TraderTraitor, is widely recognised as the financial and infrastructure-targeting arm of the North Korean state, responsible for massive thefts of cryptocurrency and attacks on financial systems like SWIFT.16
The attribution is supported by several “ironclad” pieces of evidence recovered during forensic analysis.18 The macOS variant of the Remote Access Trojan, which the attackers dubbed macWebT, is identified as a direct evolution of the webT malware module previously documented in the group’s “RustBucket” campaign.18 Furthermore, the C2 protocol structure, the JSON-based message formats, and the specific system enumeration patterns are identical to those used in the “Contagious Interview” campaign, where North Korean hackers used fake job offers to distribute malicious npm packages.15
The strategic objective of the Axios compromise was twofold: credential harvesting and infrastructure access.1 By gaining access to developer environments, BlueNoroff can steal the “keys to the kingdom”, SSH keys for private repositories, cloud service account tokens, and repository deploy keys.6 These credentials are then used to penetrate further into corporate and government networks, enabling long-term espionage or the eventual theft of cryptocurrency assets to fund the North Korean regime.15
| Attribution Characteristic | Evidence / Signature |
| Malware Lineage | macWebT project name linked to BlueNoroff’s webT (RustBucket 2023).18 |
| Campaign Overlap | C2 message types and “FirstInfo” sequence mirror “Contagious Interview” TTPs.15 |
| Target Profile | High-value developers, blockchain firms, and infrastructure maintainers.16 |
| Infrastructure | Use of anonymous ProtonMail accounts and bulletproof hosting for C2 nodes.10 |
The Axios incident marks a significant escalation in BlueNoroff’s tactics.10 Rather than relying on social engineering to target individuals, the group has successfully moved “upstream” in the supply chain, poisoning a tool used by millions to achieve a massive, automated reach that bypasses traditional phishing defences.10
The Cross-Platform RAT: Windows, macOS, and Linux Payloads
The second-stage Remote Access Trojan (RAT) delivered during the Axios breach demonstrates the technical sophistication of the adversary. Rather than using three different tools, the attackers developed a single, unified RAT framework with native-language implementations for each major operating system, sharing a common C2 protocol and command set.5
Windows Implementation: The wt.exe Masquerade
On Windows systems, the setup.js dropper wrote a VBScript to the %TEMP% directory.6 This script performed an evasion manoeuvre by copying the legitimate powershell.exe to %PROGRAMDATA%\wt.exe, masquerading as the Windows Terminal binary to evade process-name based security heuristics.6 The script then downloaded and executed a PowerShell-based RAT, which established persistence through the Windows registry:
- Registry Key: HKCU\Software\Microsoft\Windows\CurrentVersion\Run\MicrosoftUpdate
- Persistent Artifact: %PROGRAMDATA%\system.bat (a hidden batch file that re-downloads the RAT on login).5
macOS Implementation: The com.apple.act.mond Daemon
The macOS variant was a compiled Mach-O universal binary (supporting both x86_64 and ARM64 architectures).6 The dropper used an AppleScript to download the binary to /Library/Caches/com.apple.act.mond, a path chosen to mimic legitimate Apple system processes.6 To bypass Gatekeeper security checks, the malware used the codesign tool to ad hoc sign its own components.4 This C++ binary utilised the nlohmann/json library for parsing C2 commands and libcurl for secure network communications.6
Linux Implementation: The ld.py Python RAT
The Linux variant was a 443-line Python script that relied exclusively on the standard library to minimise its footprint.4 It was downloaded to /tmp/ld.py and launched as an orphaned background process via the nohup command.4 This technique ensured that even if the terminal session where npm install was run was closed, the RAT would continue to operate as a child of the init process (PID 1), severing any obvious parent-child process relationships that security tools might use for attribution.4
| Platform | Persistence Mechanism | Key Discovery Paths |
| Windows | Registry Run Key + %PROGRAMDATA%\system.bat.6 | Check for %PROGRAMDATA%\wt.exe masquerade.6 |
| macOS | Masquerades as system daemon; survives user logout.4 | Check /Library/Caches/com.apple.act.mond.4 |
| Linux | Detached background process (PID 1) via nohup.4 | Check /tmp/ld.py for Python script.6 |
Across all three platforms, the RAT engaged in immediate and aggressive system reconnaissance.6 It enumerated user directories (Documents, Desktop), cloud configuration folders (.aws), and SSH keys (.ssh), packaging this data into a “FirstInfo” beacon sent to the C2 server within seconds of infection.6
Credential Harvesting and Post-Exfiltration Tradecraft
The primary objective of the Axios compromise was not system disruption, but the systematic harvesting of credentials that facilitate further lateral movement.1 The BlueNoroff actors recognised that a developer’s workstation is the nexus of an organisation’s infrastructure, housing the secrets required to modify source code, deploy cloud resources, and access sensitive internal databases.6
Upon establishing a connection to the sfrclak[.]com C2 server, the RAT immediately began a deep scan for high-value secrets.6 The malware was specifically programmed to prioritise the following categories of data:
- Cloud Infrastructure: Searching for AWS credentials (via IMDSv2 and ~/.aws/), GCP service account files, and Azure tokens.2
- Development and CI/CD: Harvesting npm tokens from .npmrc, GitHub personal access tokens, and repository deploy keys stored in ~/.ssh/.3
- Local Environments: Dumping all environment variables, which in modern development often contain API keys for services like OpenAI, Anthropic, or database connection strings.2
- System and Shell History: Searching shell history files (.bash_history, .zsh_history) for sensitive commands, passwords, or internal URLs that could reveal system topology.8
The exfiltration process was designed for stealth. Harvested data was bundled and often encrypted using a hybrid scheme similar to that seen in the LiteLLM attack, where data is encrypted with a session-specific AES-256 key, which is then itself encrypted with a hardcoded RSA public key.8 This ensures that even if the C2 traffic is intercepted, the underlying data remains unreadable without the attacker’s private key.8
| Targeted Data Type | Specific Artifacts | Operational Outcome |
| Auth Tokens | .npmrc, ~/.git-credentials, .env | Access to modify upstream packages and hijack CI/CD pipelines.1 |
| Network Access | ~/.ssh/id_rsa, shell history | Lateral movement into production servers and internal repositories.6 |
| Cloud Secrets | ~/.aws/credentials, IMDS metadata | Full control over cloud-hosted infrastructure and data lakes.2 |
| Crypto Wallets | Browser logs, wallet files (BTC, ETH, SOL) | Direct financial theft for purported state revenue.8 |
The anti-forensic measures employed by the RAT further complicate recovery. After the initial exfiltration, the setup.js dropper deleted itself and replaced the malicious package.json with a clean decoy version (package.md).6 This swap included reporting the version as 4.2.0 (the clean pre-staged version) instead of the malicious 4.2.1.6. Consequently, incident responders running npm list might conclude their system was running a safe version of the dependency, even while the RAT remained active as an orphaned background process. 10
Strategic Failures in npm Infrastructure: The OIDC vs. Token Conflict
One of the most critical findings of the Axios post-mortem is the failure of OIDC-based Trusted Publishing to prevent the malicious releases.6 The industry has widely advocated for OIDC (OpenID Connect) as the “gold standard” for securing the software supply chain, as it replaces long-lived, static API tokens with short-lived, cryptographically signed identity tokens generated by the CI/CD provider.6
The Axios project had successfully implemented Trusted Publishing, yet the attackers were still able to publish malicious versions.6 This was made possible by a design choice in the npm authentication hierarchy: when both a long-lived NPM_TOKEN and OIDC credentials are provided, the npm CLI prioritises the token.6 The attackers exploited this by using a stolen, long-lived token, likely harvested in a prior breach, to publish directly from a local machine, completely bypassing the secure GitHub Actions workflow that was intended to be the only path for new releases.6
| Feature | Long-Lived API Tokens | Trusted Publishing (OIDC) |
| Lifetime | Static (often 30-90+ days).22 | Ephemeral (seconds to minutes).9 |
| Storage | Environmental variables, .npmrc.6 | Not stored; generated per-job.9 |
| Security Risk | High; primary vector for supply chain attacks.22 | Low; no static secret to leak.9 |
| Verification | Simple possession-based.6 | Identity-based via cryptographic signature.9 |
| Bypass Potential | Can override OIDC in current npm implementations.6 | Secure, if legacy tokens are revoked.6 |
This “shadow token” problem highlights a critical gap in infrastructure assurance. Many organisations “upgrade” to secure workflows without deactivating the legacy systems they were meant to replace.6 In the case of Axios, the presence of a single unrotated token rendered the entire SLSA (Supply-chain Levels for Software Artefacts) provenance framework ineffective for the malicious versions.6 For professionals, the lesson is clear: identity-based security is only effective when possession-based security is explicitly revoked.6
Remediation Protocol: Recovery and Hardening Strategies
The ephemeral nature of the Axios infection window does not diminish the severity of the compromise. Organisations must treat any system that resolved to [email protected] or 0.30.4 as fully compromised, characterised by a state of “assumed breach” where an interactive attacker had arbitrary code execution.
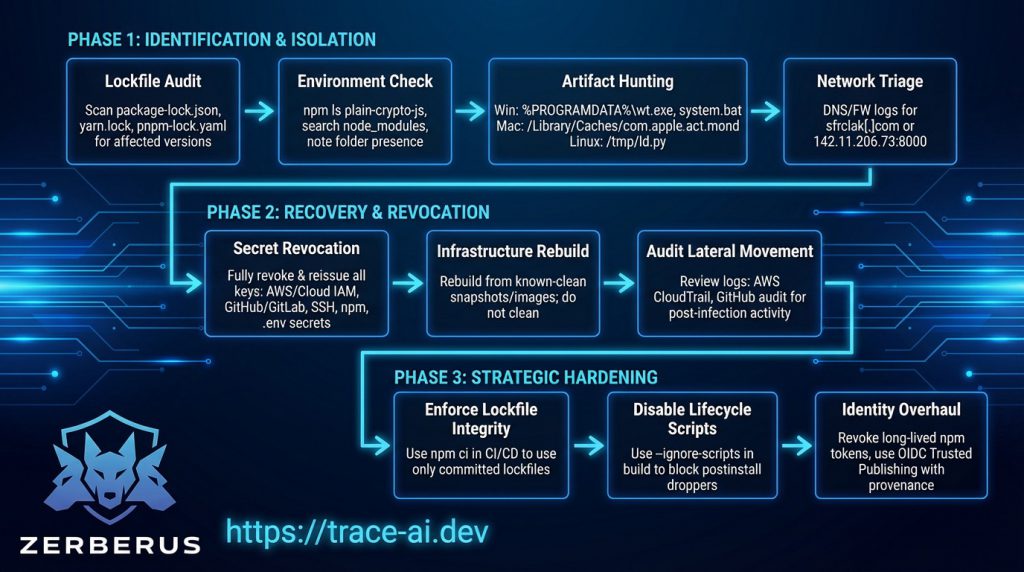
Phase 1: Identification and Isolation
- Lockfile Audit: Scan all package-lock.json, yarn.lock, and pnpm-lock.yaml files for explicit references to the affected versions or the plain-crypto-js dependency.
- Environment Check: Run npm ls plain-crypto-js or search node_modules for the directory. Note that even if package.json inside this folder looks clean, the presence of the folder itself is confirmation of execution.
- Artefact Hunting: Search for platform-specific persistence artefacts:
- Windows: %PROGRAMDATA%\wt.exe and %PROGRAMDATA%\system.bat.
- macOS: /Library/Caches/com.apple.act.mond.
- Linux: /tmp/ld.py.
- Network Triage: Inspect DNS and firewall logs for outbound connections to sfrclak[.]com or the IP 142.11.206.73 on port 8000.
Phase 2: Recovery and Revocation
- Secret Revocation: Do not simply rotate keys; they must be fully revoked and reissued. This includes AWS/Cloud IAM roles, GitHub/GitLab tokens, SSH keys, npm tokens, and all .env secrets accessible by the infected process.
- Infrastructure Rebuild: Do not attempt to “clean” infected workstations or CI runners. Rebuild them from known-clean snapshots or base images to ensure no persistence survives the remediation.
- Audit Lateral Movement: Review internal logs (e.g., AWS CloudTrail, GitHub audit logs) for unusual activity following the infection window, as the RAT was designed to move beyond the initial host.
Phase 3: Strategic Hardening
- Enforce Lockfile Integrity: Standardise on npm ci (or equivalent) in CI/CD pipelines to ensure only the committed lockfile is used, preventing silent dependency upgrades.
- Disable Lifecycle Scripts: Use the –ignore-scripts flag during installation in build environments to block the execution of postinstall droppers like setup.js.
- Identity Overhaul: Explicitly revoke all long-lived npm API tokens and mandate the use of OIDC Trusted Publishing with provenance attestations.
The Future of Infrastructure Assurance: Vibe Coding and AI Risks
The Axios incident occurred in a landscape increasingly defined by “vibe coding”—the rapid development of software using AI tools with minimal human input.23 In March 2026, Britain’s National Cyber Security Centre (NCSC) issued a stern warning that the rise of vibe coding could exacerbate the risks of supply chain poisoning.23 AI coding assistants often suggest dependencies and automatically resolve version updates based on “vibes” or perceived popularity, without performing the rigorous security vetting required for foundational libraries.23
The Axios breach perfectly exploited this dynamic. A developer using an AI-assisted “copilot” might have been prompted to “update all dependencies to resolve security alerts”.23 If the AI tool resolved to [email protected] during the infection window, it would have pulled the BlueNoroff payload into the environment with the speed of automated efficiency.23 This friction-free path for malware represents a new frontier of cyber risk, where the very tools meant to increase productivity are weaponised to accelerate the distribution of state-sponsored malware.23
Furthermore, researchers have identified that AI models themselves can be manipulated to “hallucinate” or suggest malicious packages if the naming and description are sufficiently deceptive.24 The plain-crypto-js package, with its mimicry of the legitimate crypto-js library, was designed to pass the “vibe check” of both humans and AI assistants.6
| Risk Factor | Impact on Supply Chain | Defensive Response |
| Automated Updates | AI tools pull poisoned versions in seconds.23 | Pin dependencies; use npm ci.3 |
| Shadow Identity | AI systems create untracked accounts and tokens.26 | Strict IAM governance and behavioral monitoring.26 |
| Vulnerable Generation | AI propagates known-vulnerable code patterns.23 | Automated code review and logic-based security architecture.24 |
| Speed over Safety | Tight deadlines pressure developers to skip audits.15 | Mandate human-in-the-loop for dependency changes.24 |
The Axios compromise, following closely on the heels of the LiteLLM and Trivy incidents, indicates that the “status quo of manually produced software” is being disrupted by a wave of AI-driven complexity that the security community is struggling to contain.7 Achieving future infrastructure assurance will require not just better scanners, but a deterministic security architecture that limits what code can do even if it is compromised or malicious.24
Conclusion: Strategic Recommendations for Professional Resilience
The software supply chain is no longer a peripheral concern; it is the primary battleground for nation-state actors seeking to fund their operations and gain long-term strategic access to global digital infrastructure.10 The Axios breach demonstrated that even the most trusted tools can be weaponised in minutes, and that modern security frameworks like OIDC are only as effective as the legacy tokens they leave behind.6
For organisations seeking to protect their assets from future supply chain cascades, the following recommendations are essential:
- Immediate Remediation for Axios: Any system that resolved to [email protected] or 0.30.4 must be treated as fully compromised.3 This requires the immediate revocation and reissue of all environment secrets, SSH keys, and cloud tokens accessible from that system.2 The presence of the node_modules/plain-crypto-js directory is a sufficient indicator of compromise, regardless of the apparent “cleanliness” of its manifest.6
- Legacy Token Sunset: Organisations must perform a comprehensive audit of their npm and GitHub tokens.22 All static, long-lived API tokens must be revoked and replaced with OIDC-based Trusted Publishing.9 The Axios breach proves that the mere existence of a legacy token is a vulnerability that state-sponsored actors will proactively seek to exploit.6
- Enforced Dependency Isolation: Build environments and CI/CD pipelines should be configured with a “deny-by-default” egress policy.15 Legitimate build tasks should be restricted to known, trusted domains, and all postinstall scripts should be disabled via –ignore-scripts unless explicitly required and audited.2
- Adopt Behavioural and Anomaly Detection: Traditional IOC-based detection is insufficient against sophisticated actors who use self-deleting malware and ephemeral infrastructure.7 Organisations must implement behavioural monitoring to detect the 60-second beaconing cadence, unusual process detachment (PID 1), and unauthorised directory enumeration that characterise nation-state RATs.7
The Axios compromise of 2026 was a success for the adversary, but it provides a critical empirical lesson for the defender. In an ecosystem of 100 million weekly downloads, security is a shared responsibility that must be maintained with constant vigilance and an uncompromising commitment to infrastructure assurance.8
References and Further Reading
- Axios supply chain attack chops away at npm trust – Malwarebytes, accessed on March 31, 2026, https://www.malwarebytes.com/blog/news/2026/03/axios-supply-chain-attack-chops-away-at-npm-trust
- Axios NPM Supply Chain Compromise: Malicious Packages Deliver Remote Access Trojan, accessed on March 31, 2026, https://www.sans.org/blog/axios-npm-supply-chain-compromise-malicious-packages-remote-access-trojan
- The Axios Compromise: What Happened, What It Means, and What You Should Do Right Now – HeroDevs, accessed on March 31, 2026, https://www.herodevs.com/blog-posts/the-axios-compromise-what-happened-what-it-means-and-what-you-should-do-right-now
- Axios npm Package Compromised: Supply Chain Attack Delivers …, accessed on March 31, 2026, https://snyk.io/blog/axios-npm-package-compromised-supply-chain-attack-delivers-cross-platform/
- Inside the Axios supply chain compromise – one RAT to rule them all …, accessed on March 31, 2026, https://www.elastic.co/security-labs/axios-one-rat-to-rule-them-all
- Supply-Chain Compromise of axios npm Package – Huntress, accessed on March 31, 2026, https://www.huntress.com/blog/supply-chain-compromise-axios-npm-package
- Axios Compromised: The 2-Hour Window Between Detection and Damage, accessed on March 31, 2026, https://www.stream.security/post/axios-compromised-the-2-hour-window-between-detection-and-damage
- The LiteLLM Supply Chain Cascade: Empirical Lessons in AI Credential Harvesting and the Future of Infrastructure Assurance – Nocturnalknight’s Lair, accessed on March 31, 2026, https://nocturnalknight.co/the-litellm-supply-chain-cascade-empirical-lessons-in-ai-credential-harvesting-and-the-future-of-infrastructure-assurance/
- Decoding the GitHub recommendations for npm maintainers – Datadog Security Labs, accessed on March 31, 2026, https://securitylabs.datadoghq.com/articles/decoding-the-recommendations-for-npm-maintainers/
- Axios npm package compromised, posing a new supply chain threat – Techzine Global, accessed on March 31, 2026, https://www.techzine.eu/news/security/140082/axios-npm-package-compromised-posing-a-new-supply-chain-threat/
- axios Compromised on npm – Malicious Versions Drop Remote …, accessed on March 31, 2026, https://www.stepsecurity.io/blog/axios-compromised-on-npm-malicious-versions-drop-remote-access-trojan
- Axios npm Hijack 2026: Everything You Need to Know – IOCs, Impact & Remediation, accessed on March 31, 2026, https://socradar.io/blog/axios-npm-supply-chain-attack-2026-ciso-guide/
- Axios Compromised With A Malicious Dependency – OX Security, accessed on March 31, 2026, https://www.ox.security/blog/axios-compromised-with-a-malicious-dependency/
- npm Supply Chain Attack: Massive Compromise of debug, chalk, and 16 Other Packages, accessed on March 31, 2026, https://www.upwind.io/feed/npm-supply-chain-attack-massive-compromise-of-debug-chalk-and-16-other-packages
- 338 Malicious npm Packages Linked to North Korean Hackers | eSecurity Planet, accessed on March 31, 2026, https://www.esecurityplanet.com/news/338-malicious-npm-packages-linked-to-north-korean-hackers/
- June’s Sophisticated npm Attack Attributed to North Korea | Veracode, accessed on March 31, 2026, https://www.veracode.com/blog/junes-sophisticated-npm-attack-attributed-to-north-korea/
- Technology – Axios, accessed on March 31, 2026, https://www.axios.com/technology
- Axios npm Supply Chain Compromise (2026-03-31) — Full RE + …, accessed on March 31, 2026, https://gist.github.com/N3mes1s/0c0fc7a0c23cdb5e1c8f66b208053ed6
- Cyberwar Methods and Practice 26 February 2024 – osnaDocs, accessed on March 31, 2026, https://osnadocs.ub.uni-osnabrueck.de/bitstream/ds-2024022610823/1/Cyberwar_26_Feb_2024_Saalbach.pdf
- Polyfill Supply Chain Attack Impacting 100k Sites Linked to North Korea – SecurityWeek, accessed on March 31, 2026, https://www.securityweek.com/polyfill-supply-chain-attack-impacting-100k-sites-linked-to-north-korea/
- Weekly Security Articles 05-May-2023 – ATC GUILD INDIA, accessed on March 31, 2026, https://www.atcguild.in/iwen/iwen1923/General/weekly%20security%20items%2005-May-2023.pdf
- Strengthening npm security: Important changes to authentication and token management, accessed on March 31, 2026, https://github.blog/changelog/2025-09-29-strengthening-npm-security-important-changes-to-authentication-and-token-management/
- Vibe coding could reshape SaaS industry and add security risks, warns UK cyber agency, accessed on March 31, 2026, https://therecord.media/vibe-coding-uk-security-risk
- NCSC warns vibe coding poses a major risk to businesses | IT Pro – ITPro, accessed on March 31, 2026, https://www.itpro.com/security/ncsc-warns-vibe-coding-poses-a-major-risk
- Security Researchers Sound the Alarm on Vulnerabilities in AI-Generated Code, accessed on March 31, 2026, https://www.cc.gatech.edu/external-news/security-researchers-sound-alarm-vulnerabilities-ai-generated-code
- Sitemap – Cybersecurity Insiders, accessed on March 31, 2026, https://www.cybersecurity-insiders.com/sitemap/
- IAM – Nocturnalknight’s Lair, accessed on March 31, 2026, https://nocturnalknight.co/category/iam/
- Widespread Supply Chain Compromise Impacting npm Ecosystem – CISA, accessed on March 31, 2026, https://www.cisa.gov/news-events/alerts/2025/09/23/widespread-supply-chain-compromise-impacting-npm-ecosystem