The LiteLLM Supply Chain Cascade: Empirical Lessons in AI Credential Harvesting and the Future of Infrastructure Assurance
TL:DR: This is an Empirical Study and could be quite long for non-researchers. If you’d prefer the remediation protocol directly, you can head to the bottom. In case you want to understand the anatomy of the attack and background, I have made a video that can be a quick explainer.
Background and Summary:
The compromise of the LiteLLM Python library in March 2026 stands as a definitive case study in the fragility of modern AI infrastructure. LiteLLM, an open-source API gateway, acts as a critical abstraction layer enabling developers to interface with over 100 LLM providers through a unified OpenAI-style format.¹ It effectively becomes the central node through which an organisation’s most sensitive AI credentials, including keys for OpenAI, Anthropic, Google Vertex AI, and Amazon Bedrock, are routed and managed.² Its scale is reflected in its reach, averaging approximately 97 million downloads per month on PyPI.³
On 24 March 2026, malicious actors identified as TeamPCP published two poisoned versions, 1.82.7 and 1.82.8, directly to PyPI.³ The choice of target was deliberate. By compromising a package designed to centralise AI credentials, the attackers positioned themselves for broad and immediate access across multiple providers. The breach impacted high-profile organisations such as NASA, Netflix, Stripe, and NVIDIA, underscoring LiteLLM’s deep integration into production environments.⁵
The attack itself leveraged a subtle but powerful mechanism. Version 1.82.8 introduced a malicious .pth file, ensuring code execution at Python interpreter startup, regardless of whether the library was imported.⁴ This effectively turned installation into a compromise. Detection, however, did not come from security tooling. A flaw in the attacker’s implementation triggered an uncontrolled fork bomb, exhausting system resources and crashing machines.⁵ This failure, described as “vibe coding”, became the only signal that exposed the breach, likely preventing widespread, silent exfiltration across production systems.
The Architectural Criticality of LiteLLM and the Blast Radius
The positioning of LiteLLM within the AI stack represents a classic single point of failure. Modern enterprise AI deployments often involve multiple providers to balance cost, latency, and performance requirements. LiteLLM provides the necessary proxy logic to handle these providers through a single endpoint. Consequently, the environment variables and configuration files associated with LiteLLM deployments house a concentrated wealth of sensitive information.
LiteLLM Market Penetration and Integration Scale
| Metric | Value / Entity |
| Monthly Downloads (PyPI) | 95,000,000 – 97,000,000 3 |
| Daily Download Average | ~3.4 – 3.6 Million 3 |
| Direct Institutional Users | NASA, Netflix, NVIDIA, Stripe 3 |
| Transitive Dependencies | DSPy, CrewAI, MLflow, Open Interpreter 2 |
| GitHub Stars | > 40,000 5 |
| Cloud Presence | Found in ~36% of cloud environments 8 |
The blast radius of the March 24th incident extended far beyond direct users of LiteLLM. The library is a frequent transitive dependency for a wide range of AI frameworks and orchestration tools. Organizations using DSPy for building modular AI programs or CrewAI for agent orchestration inadvertently pulled the malicious versions into their environments without ever explicitly initiating a pip install litellm command.2 This highlights a fundamental tension in the AI development cycle: the speed of adoption for agentic AI tools has outpaced the visibility that security teams have into the underlying software supply chain.2
The Anatomy of the Poisoning: Versions 1.82.7 and 1.82.8
The poisoning of the LiteLLM package was conducted with a high degree of stealth, bypassing the project’s official GitHub repository entirely. The malicious versions were published straight to PyPI using stolen credentials, meaning there were no corresponding code changes, release tags, or review processes visible to the community on GitHub until after the damage had been initiated.3
Technical Divergence in Malicious Releases
In version 1.82.7, the attackers injected 12 lines of obfuscated, base64-encoded code into the litellm/proxy/proxy_server.py file.2 This payload was designed to trigger during the import of the litellm.proxy module, which is the standard procedure for users deploying LiteLLM as a proxy server. While effective, this required the package to be active to execute its malicious logic.9Version 1.82.8, however, utilised the much more aggressive .pth file mechanism. The attackers included a file named litellm_init.pth (approximately 34,628 bytes) within the package root.9 In Python, .pth files are automatically processed and executed during the interpreter’s initialisation phase. By placing the payload here, the attackers ensured that the malware would fire the second the package existed in a site-packages directory on the machine, whether it was imported or not.4 This mechanism is particularly dangerous in environments where AI development tools or language servers (like those in VS Code or Cursor) periodically scan and initialise Python environments in the background.5
Execution Triggers and Persistence Mechanisms

The .pth launcher in version 1.82.8 utilised a subprocess. Popen call to execute a second Python process containing the actual data-harvesting payload.10 Because the initialisation logic was flawed, an oversight attributed to “vibe coding”, this subprocess itself triggered the .pth file again, initiating a recursive chain of process creation.9 The resulting exponential fork bomb can be described by the function N(t)= 2t, where N is the number of processes and t is the number of initialisation cycles. Within a matter of seconds, the affected machines became unresponsive, leading to the crashes that ultimately exposed the operation.9
The Discovery: FutureSearch and the Cursor Connection
The identification of the LiteLLM compromise began with a developer at FutureSearch, Callum McMahon, who was testing a Model Context Protocol (MCP) plugin within the Cursor AI editor.2 The plugin utilised the uvx tool for Python package management, which automatically pulled in the latest version of LiteLLM as an unpinned transitive dependency.9When the Cursor IDE attempted to load the MCP server, the uvx tool downloaded LiteLLM 1.82.8. Almost immediately, the developer’s machine became unresponsive due to RAM exhaustion.9 Upon investigation using the Claude Code assistant to help root-cause the crash, McMahon identified the suspicious litellm_init.pth file and traced it back to the newly published PyPI release.7 This discovery highlights a significant security gap in the current AI agent ecosystem: many popular development tools and “copilots” automatically pull and execute dependencies with little to no review, creating a frictionless path for supply chain malware to reach the local machines of developers who hold broad access to corporate infrastructure.2
The TeamPCP Attack Chain: From Security Tools to AI Infrastructure
The compromise of LiteLLM was the culminating event of a multi-week campaign by TeamPCP (also tracked as PCPcat, Persy_PCP, DeadCatx3, and ShellForce).9 This actor demonstrated a profound ability to execute a “cascading” supply chain attack, where the credentials stolen from one ecosystem were used to penetrate the next.15
The March 19th Inflection Point: The Trivy Compromise
The campaign gained critical momentum on March 19, 2026, when TeamPCP targeted Aqua Security’s Trivy, the most widely adopted open-source vulnerability scanner in the cloud-native ecosystem.17 By exploiting a misconfigured workflow and a privileged Personal Access Token (PAT) that had not been fully revoked following a smaller incident in late February, the attackers gained access to Trivy’s release infrastructure.18
The attackers force-pushed malicious commits and tags (affecting 76 out of 77 tags) to the aquasecurity/trivy-action repository, silently replacing legitimate security tools with weaponized versions.6 Because LiteLLM utilized Trivy within its own CI/CD pipeline for automated security scanning, the execution of the poisoned Trivy binary allowed TeamPCP to harvest the PYPI_PUBLISH token for the LiteLLM project from the runner’s memory.9 This created a recursive irony: the security tool designed to protect the project became the very mechanism of its downfall.5
Multi-Ecosystem Campaign Timeline
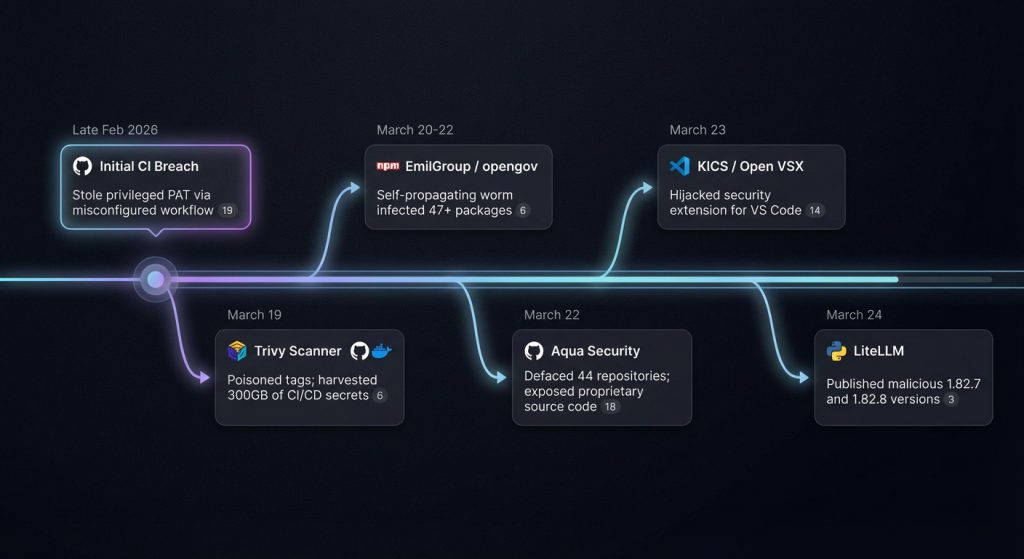
By the time LiteLLM was poisoned, TeamPCP had already breached five major package ecosystems in a period of two weeks.4 Their operations moved with a speed that exceeded the industry’s ability to respond, using each breach as a stepping stone to unlock the next layer of the software stack.3
Deep Analysis of the Malware Payload
The malware deployed in the LiteLLM attack was a sophisticated, three-stage infostealer designed for a comprehensive credential-harvesting operation coupled with a long-term persistence within cloud-native environments.
Stage 1: The Harvest
Once triggered, the payload initiated an exhaustive sweep of the host file system and memory. The malware was specifically programmed to seek out the “keys to the kingdom”—credentials that would allow for further lateral movement or data theft.
- System and Environment: The malware dumped all environment variables, which in AI workloads almost invariably include OPENAI_API_KEY, ANTHROPIC_API_KEY, and other LLM provider tokens.2 It also captured hostnames, network routing tables, and auth logs from /var/log/auth.log.9
- Developer Credentials: The script targeted ~/.ssh/ for private keys, ~/.gitconfig and ~/.git-credentials for repository access, and shell history files to identify sensitive commands or passwords.2
- Cloud and Infrastructure: It explicitly searched for AWS credentials (via IMDSv2 and ~/.aws/), GCP service account files, Azure tokens, and Kubernetes kubeconfig files.9
- Financial and Database Data: The payload harvested database connection strings, Docker configs, and cryptocurrency wallet files for platforms including Bitcoin, Ethereum, and Solana.2
Stage 2: Encrypted Exfiltration
To avoid detection by network monitoring tools, the harvested data was bundled into an archive named tpcp.tar.gz and encrypted using a hybrid scheme. The malware generated a random 32-byte AES-256 session key to encrypt the archive and then encrypted that key using a hardcoded 4096-bit RSA public key.9 This ensured that only the threat actors could decrypt the stolen data. The encrypted bundle was exfiltrated via HTTPS POST to models.litellm.cloud, a typosquatted domain registered just one day prior to the attack.9
As a secondary exfiltration channel, if the primary C2 server was unreachable, the malware was configured to use a stolen GitHub PAT to create a public repository named tpcp-docs in the victim’s own GitHub account, uploading the stolen credentials as release assets.6
Stage 3: Persistence and the Kubernetes Worm
The malware went beyond simple data theft to ensure long-term access. On local development machines, it installed a script named sysmon.py in ~/.config/sysmon/ and created a systemd user service named “System Telemetry Service” to ensure the backdoor would run persistently.9In environments where a Kubernetes service account token was discovered, the malware initiated a “worm” behavior. It attempted to deploy a DaemonSet or privileged pods (often named node-setup) in the kube-system namespace.9 These pods used hostPath mounts to escape the container environment and access the underlying node’s root filesystem, allowing the attackers to harvest SSH keys from every node in the cluster and establish a persistent foothold at the infrastructure level.7
The Adversary Persona: TeamPCP and the Telegram Thread
TeamPCPs’ operations are characterised by a blend of technical innovation and explicit psychological warfare. The group maintains an active presence on Telegram through channels such as @teampcp and @Persy_PCP, where they showcase their exploits and interact with the security community.9 Following the successful poisoning of the security and AI stacks, the group posted a chilling warning: “Many of your favourite security tools and open-source projects will be targeted in the months to come. Stay tuned”.22
Analysis of their techniques suggests a group that is highly automated and focused on the “security-AI stack”.15 Their willingness to target vulnerability scanners like Trivy and KICS indicates a strategic choice to subvert the tools that organizations trust implicitly.2 Furthermore, their “kamikaze” payload—which on Iranian systems was programmed to delete the host filesystem and force-reboot the node—suggests a geopolitical dimension to their operations that may be independent of their broader credential-harvesting goals.6
Structural Vulnerabilities in AI Agent Tooling
The LiteLLM incident exposes a fundamental tension in the current era of AI development. The speed with which companies are shipping AI agents, copilots, and internal tools has created a “credential dumpster fire” where thousands of packages run in environments with broad, unmonitored access.2The fact that LiteLLM entered a developer’s machine through a “dependency of a dependency of a plugin” is illustrative of the lack of visibility that currently plagues the ecosystem.2 Tools like uvx and npx, while providing immense convenience for running one-off tasks, create a frictionless environment for supply chain attacks to propagate.9 Because these tools often default to the latest version of a package, they are the primary propagation vector for poisoned releases that stay active on PyPI for even a few hours.23
Closing the Visibility Gap: From Recovery to Prevention
The failure of traditional security measures during the LiteLLM and Trivy attacks highlights a structural limitation in current software assurance. Standard vulnerability scanners—including the very ones compromised in this campaign—were unable to detect the threat because the malicious code was published using legitimate credentials and passed all standard integrity checks.9 Recovering from this incident requires immediate action; preventing the next one requires a fundamentally different approach to supply chain visibility.
Comprehensive Remediation Protocol
For organizations that have been affected by LiteLLM versions 1.82.7 or 1.82.8, the path to recovery must be rigorous and comprehensive. A simple upgrade to version 1.82.9 or later is insufficient, as the primary objective of the malware was the theft of long-term credentials.9

Moving forward, security teams should implement “dependency cooldowns” and use tools like uv or pip with the --exclude-newer flag to prevent the automatic installation of packages that have been available for less than 72 hours.24 Furthermore, pinning dependencies to immutable commit SHAs rather than version tags is now a requirement for secure CI/CD pipelines, as tags can be easily force-pushed by a compromised account.10
The remediation steps above address the immediate crisis, but they do not answer a harder question: what would have caught this attack before it reached production? The LiteLLM poisoning succeeded precisely because it exploited the blind spots of CVE-based scanning. There was no vulnerability to match against; only behavioural anomalies that require a different class of analysis to detect.
Why Trace-AI Detects What Traditional Tools Miss
Trace-AI provides real-time visibility into both direct and transitive dependencies by extracting a complete SBOM directly from builds and pipelines.25 Rather than relying solely on a lagging database of known vulnerabilities (NVD/CVE), Trace-AI uses five key scoring dimensions to identify risk before it is publicly disclosed.
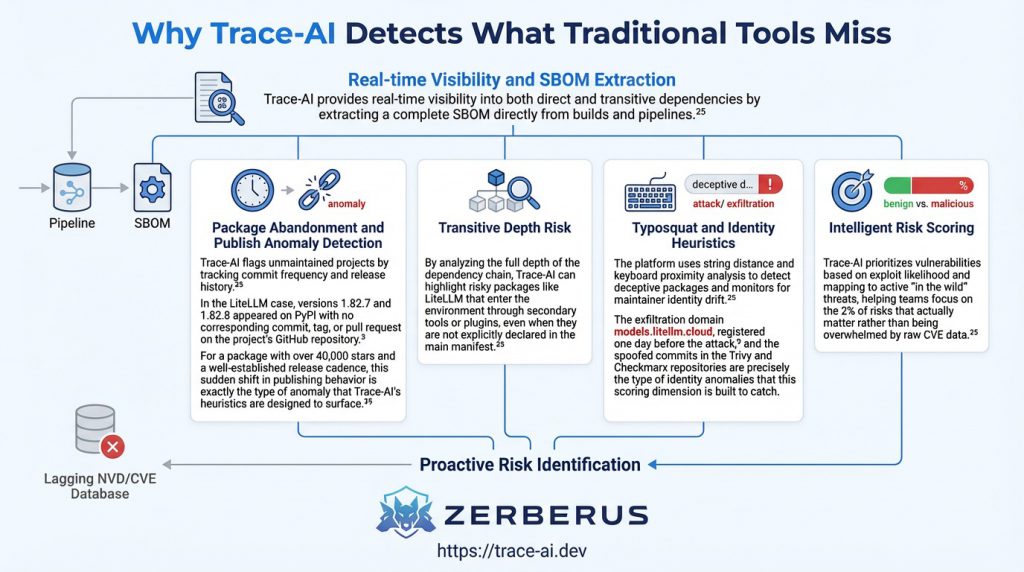
Final Conclusion
The LiteLLM supply chain attack of 2026 was not a failure of individual developers but a failure of the current trust model of the open-source ecosystem. When a single poisoned package can reach the production environments of NASA, Netflix, and NVIDIA in hours, the “vibe coding” approach to dependency management must end.3The TeamPCP campaign has shown that attackers are moving upstream, targeting the tools that security professionals and AI researchers rely on most. The concentrated value of AI API keys and cloud credentials makes the AI orchestration layer a prime target for high-impact harvesting operations.2 As organisations continue to deploy AI at scale, the only way to maintain a secure posture is to achieve deep, real-time visibility into the entire supply chain. Tools like Trace-AI by Zerberus.ai provide the necessary foundation for this new era of assurance, ensuring that the software you depend on is a source of strength, not a vector for catastrophic compromise.25
References and Further Reading
- litellm – PyPI, accessed on March 25, 2026, https://pypi.org/project/litellm/
- The Library That Holds All Your AI Keys Was Just Backdoored: The LiteLLM Supply Chain Compromise – ARMO Platform, accessed on March 25, 2026, https://www.armosec.io/blog/litellm-supply-chain-attack-backdoor-analysis/
- The LiteLLM Supply Chain Attack: A Complete Technical … – Blog, accessed on March 25, 2026, https://blog.dreamfactory.com/the-litellm-supply-chain-attack-a-complete-technical-breakdown-of-what-happened-who-is-affected-and-what-comes-next
- TeamPCP Supply Chain Attacks Escalate Across Open Source – Evrim Ağacı, accessed on March 25, 2026, https://evrimagaci.org/gpt/teampcp-supply-chain-attacks-escalate-across-open-source-534993
- litellm got poisoned today. Found because an MCP plugin in Cursor …, accessed on March 25, 2026, https://www.reddit.com/r/cybersecurity/comments/1s2sfbl/litellm_got_poisoned_today_found_because_an_mcp/
- LiteLLM compromised on PyPI: Tracing the March 2026 TeamPCP supply chain campaign, accessed on March 25, 2026, https://securitylabs.datadoghq.com/articles/litellm-compromised-pypi-teampcp-supply-chain-campaign/
- Supply Chain Attack in litellm 1.82.8 on PyPI – FutureSearch, accessed on March 25, 2026, https://futuresearch.ai/blog/litellm-pypi-supply-chain-attack/
- LiteLLM TeamPCP Supply Chain Attack: Malicious PyPI Packages …, accessed on March 25, 2026, https://www.wiz.io/blog/threes-a-crowd-teampcp-trojanizes-litellm-in-continuation-of-campaign
- How a Poisoned Security Scanner Became the Key to Backdooring LiteLLM | Snyk, accessed on March 25, 2026, https://snyk.io/articles/poisoned-security-scanner-backdooring-litellm/
- No Prompt Injection Required – FutureSearch, accessed on March 25, 2026, https://futuresearch.ai/blog/no-prompt-injection-required/
- Don’t Let Cyber Risk Kill Your GenAI Vibe: A Developer’s Guide – mkdev, accessed on March 25, 2026, https://mkdev.me/posts/don-t-let-cyber-risk-kill-your-genai-vibe-a-developer-s-guide
- LiteLLM Supply Chain Breakdown – Upwind Security, accessed on March 25, 2026, https://www.upwind.io/feed/litellm-pypi-supply-chain-attack-malicious-release
- Blogmarks – Simon Willison’s Weblog, accessed on March 25, 2026, https://simonwillison.net/blogmarks/
- Checkmarx KICS Code Scanner Targeted in Widening Supply Chain Hit – Dark Reading, accessed on March 25, 2026, https://www.darkreading.com/application-security/checkmarx-kics-code-scanner-widening-supply-chain
- When Security Scanners Become the Weapon: Breaking Down the Trivy Supply Chain Attack – Palo Alto Networks, accessed on March 25, 2026, https://www.paloaltonetworks.com/blog/cloud-security/trivy-supply-chain-attack/
- TeamPCP expands: Supply chain compromise spreads from Trivy to Checkmarx GitHub Actions | Sysdig, accessed on March 25, 2026, https://www.sysdig.com/blog/teampcp-expands-supply-chain-compromise-spreads-from-trivy-to-checkmarx-github-actions
- Guidance for detecting, investigating, and defending against the Trivy supply chain compromise | Microsoft Security Blog, accessed on March 25, 2026, https://www.microsoft.com/en-us/security/blog/2026/03/24/detecting-investigating-defending-against-trivy-supply-chain-compromise/
- The Trivy Supply Chain Compromise: What Happened and Playbooks to Respond, accessed on March 25, 2026, https://www.legitsecurity.com/blog/the-trivy-supply-chain-compromise-what-happened-and-playbooks-to-respond
- Trivy’s March Supply Chain Attack Shows Where Secret Exposure Hurts Most, accessed on March 25, 2026, https://blog.gitguardian.com/trivys-march-supply-chain-attack-shows-where-secret-exposure-hurts-most/
- From Trivy to Broad OSS Compromise: TeamPCP Hits Docker Hub, VS Code, PyPI, accessed on March 25, 2026, https://www.securityweek.com/from-trivy-to-broad-oss-compromise-teampcp-hits-docker-hub-vs-code-pypi/
- Trivy Compromised by “TeamPCP” | Wiz Blog, accessed on March 25, 2026, https://www.wiz.io/blog/trivy-compromised-teampcp-supply-chain-attack
- Incident Timeline // TeamPCP Supply Chain Campaign, accessed on March 25, 2026, https://ramimac.me/trivy-teampcp/
- Simon Willison on generative-ai, accessed on March 25, 2026, https://simonwillison.net/tags/generative-ai/
- Simon Willison on uv, accessed on March 25, 2026, https://simonwillison.net/tags/uv/
- Software Supply Chain (Trace-AI) | Zerberus.ai, accessed on March 25, 2026, https://www.zerberus.ai/trace-ai
- Trace-AI: Know What You Ship. Secure What You Depend On. | Product Hunt, accessed on March 25, 2026, https://www.producthunt.com/products/trace-ai-2