As an Enterprise/Solution Architect, I have been called upon upteen times help make a decision on several technology platforms. Based on the company’s product/service road-map and the digital strategy (in cases defining these along the way) I have also helped them in selecting an WCMS.
Personally though, I am more inclined toward Drupal/Acquia and previously toward Zope in open-source and SiteCore and CQ5 (now rebranded as AEM) in enterprise class products. Still, I have found it very useful and at times helpful in convincing the client with the reports of 3 research corporations. Prime among them are Gartner, Forrester and IDC.
Naturally, I follow them with interest, and am sharing the latest Magic Quadrant here.
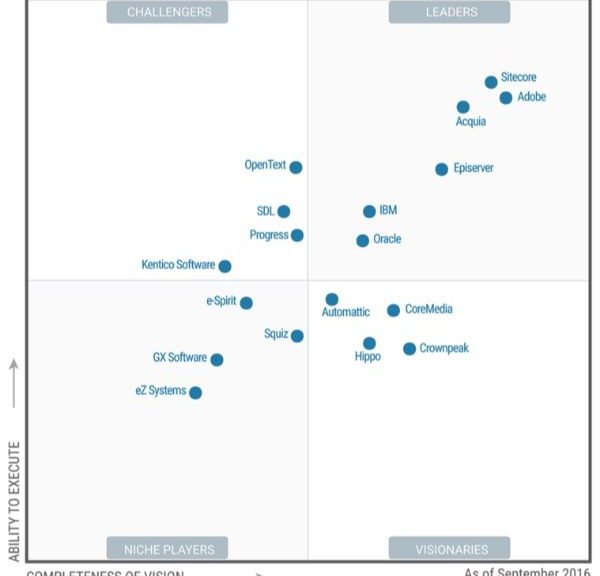
This Year, Gartner Research has downgraded OpenText, SDL and HP from the leader’s quadrant in its latest industry report on web content management (WCM).
Previous contenders Sitecore, Adobe, Acquia, EPiServer, IBM and Oracle retained their spots on the leaderboard in the Stamford, Conn.-based research firm’s Magic Quadrant for Web Content Management, which it released yesterday. According to Gartner report authors Mick MacComascaigh and Jim Murphy, Boston-based Acquia made the biggest positive move, closing the gap on Copenhagen-based Sitecore and San Jose, Calif.-based Adobe.3
But Sitecore and Adobe still lead the WCM pack, based on Gartner’s criteria of completeness of vision and ability to execute. It was the same story last year, with Sitecore edging Adobe for execution but Adobe winning in the vision department, Gartner concluded.
Acquia, a Drupal-based, open source content management system, jumped from a visionary to a leader in 2014 and hasn’t left the leaders’ spot since. It’s the lone open source vendor among the leaders.
Microsoft, rated a niche player last year, failed to make the cut this year. MacComascaigh and Murphy said Microsoft has focused its attention more on the digital workplace and less on WCM.
It places them in one of four quadrants:
Leaders: Those who “drive market transformation” and are “prepared for the future with a clear vision and a thorough appreciation of the broader context of digital business.”
Challengers: Those who may have a strong WCM product but have a product strategy that “does not fully reflect market trends.”
Visionaries: Those that are “forward-thinking and technically focused” but need to improve and execute better.
Niche Players: Those who focus on a particular segment of the market, such as size, industry and project complexity. But that, according to Gartner authors, “can affect their ability to outperform their competitors or to be more innovative.”
Gartner Magic Quadrant for WCMS – 2016
Hope you found this article useful.
GitHub will release as open source the GitHub Load Balancer (GLB), its internally developed load balancer.
GLB was originally built to accommodate GitHub’s need to serve billions of HTTP, Git, and SSH connections daily. Now the company will release components of GLB via open source, and it will share design details. This is seen as a major step in building scalable infrastructure using commodity hardware. for more details please refer to the GitHub Engineering Post .
GE & Bosch to leverage open source to deliver IoT tools
Partnerships that could shape the internet of things for years are being forged just as enterprises fit IoT into their long-term plans. Representation of an IoT & IIoT Convergence
As a vast majority of organisations have included #IoT as part of their strategic plans for the next two to three years. No single vendor can meet the diverse #IoT needs of all customers, so they’re joining forces and also trying to foster broader ecosystems. General Electric and Bosch did both recently announced their intention to do the same.
The two companies, both big players in #IIoT, said they will establish a core IoT software stack based on open-source software. They plan to integrate parts of GE’s #Predix operating system with the #Bosch IoT Suite in ways that will make complementary software services from each available on the other.
The work will take place in several existing open-source projects under the #Eclipse Foundation. These projects are creating code for things like messaging, user authentication, access control and device descriptions. Through the Eclipse projects, other vendors also will be able to create software services that are compatible with Predix and Bosch IoT Suite, said Greg Petroff, executive director of platform evangelism at GE Software.
If enterprises can draw on a broader set of software components that work together, they may look into doing things with IoT that they would not have considered otherwise, he said. These could include linking IoT data to ERP or changing their business model from one-time sales to subscriptions.
GE and Bosch will keep the core parts of Predix and IoT Suite unique and closed, Petroff said. In the case of Predix, for example, that includes security components. The open-source IoT stack will handle fundamental functions like messaging and how to connect to IoT data.
Partnerships and open-source software both are playing important roles in how IoT takes shape amid expectations of rapid growth in demand that vendors want to be able to serve. Recently, IBM joined with Cisco Systems to make elements of its Watson analytics available on Cisco IoT edge computing devices. Many of the common tools and specifications designed to make different IoT devices work together are being developed in an open-source context.
GE & Bosch to leverage open source to deliver IoT tools
Partnerships that could shape the internet of things for years are being forged just as enterprises fit IoT into their long-term plans. Representation of an IoT & IIoT Convergence
As a vast majority of organisations have included #IoT as part of their strategic plans for the next two to three years. No single vendor can meet the diverse #IoT needs of all customers, so they’re joining forces and also trying to foster broader ecosystems. General Electric and Bosch did both recently announced their intention to do the same.
The two companies, both big players in #IIoT, said they will establish a core IoT software stack based on open-source software. They plan to integrate parts of GE’s #Predix operating system with the #Bosch IoT Suite in ways that will make complementary software services from each available on the other.
The work will take place in several existing open-source projects under the #Eclipse Foundation. These projects are creating code for things like messaging, user authentication, access control and device descriptions. Through the Eclipse projects, other vendors also will be able to create software services that are compatible with Predix and Bosch IoT Suite, said Greg Petroff, executive director of platform evangelism at GE Software.
If enterprises can draw on a broader set of software components that work together, they may look into doing things with IoT that they would not have considered otherwise, he said. These could include linking IoT data to ERP or changing their business model from one-time sales to subscriptions.
GE and Bosch will keep the core parts of Predix and IoT Suite unique and closed, Petroff said. In the case of Predix, for example, that includes security components. The open-source IoT stack will handle fundamental functions like messaging and how to connect to IoT data.
Partnerships and open-source software both are playing important roles in how IoT takes shape amid expectations of rapid growth in demand that vendors want to be able to serve. Recently, IBM joined with Cisco Systems to make elements of its Watson analytics available on Cisco IoT edge computing devices. Many of the common tools and specifications designed to make different IoT devices work together are being developed in an open-source context.
DCNS's Scorpene Data Leak and Future of Indian Submarine Fleet
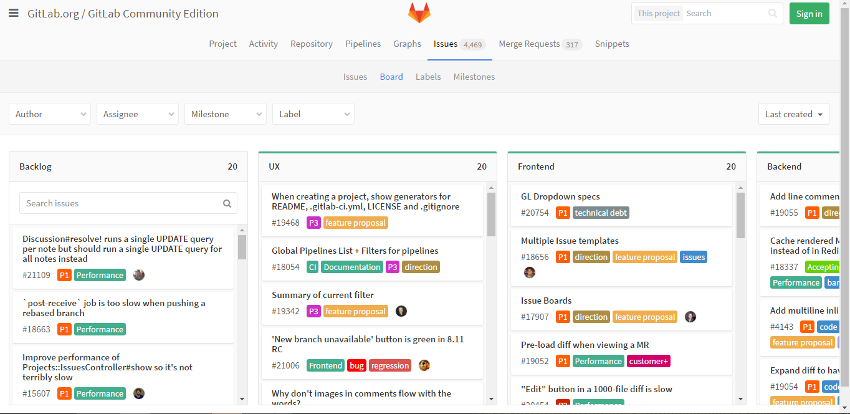
The startup today introduced an issue tracking feature for its fast-growing code hosting platform that promises to help development teams organize the features, enhancements and other items on their to-do lists more effectively.
The GitLab Issue Board is a sleek graphical panel that provides the ability to display tasks as digital note cards and sort them into neat columns each representing a different part of the application lifecycle. By default, new panels start only with a “Backlog” section for items still in the queue and a “Done” list that shows completed tasks, but users are able to easily add more tabs if necessary. GitLab says that the tool makes it possible to break up a view into as many as 10 different segments if need be, which should be enough for even the most complex software projects.
An enterprise development team working on an internal client-server service, for instance, could create separate sections to hold backend tasks, issues related to the workload’s desktop client and user experience bugs. Users with such crowded boards can also take advantage of GitLab’s built in tagging mechanism to label each item with color-coded tags denoting its purpose. The feature not only helps quickly make sense of the cards on a given board but also makes it easier to find specific items in the process. When an engineer wants to check if there are new bug fix requests concerning their part of a project, they can simply filter the board view based on the appropriate tags.
Google this week has published a new version of its TensorFlow machine learning software that adds support for iOS. Google initially teased that it was working on iOS support for TensorFlow last November, but said it was unable to give a timeline. An early version of TensorFlow version 0.9 was released yesterday on GitHub, however, and it brings iOS support.
For those unfamiliar, TensorFlow is Google’s incredibly powerful artificial intelligence software that powers many of Google’s services and initiatives, including AlphaGo. Google describes TensorFlow as “neural network” software that processes data in a way that’s similar how our brain cells process data (via CNET).
With Google adding iOS support to TensorFlow, apps will be able to integrate the smarter neural network capabilities into their apps, ultimately making them considerably smarter and capable.
At this point, it’s unclear when the final version of TensorFlow 0.9 will be released, but the early pre-release version is available now on GitHub. In the release notes, Google points out that because TensorFlow is now open source, 46 people from outside the company contributed to TensorFlow version 0.9.
In addition to adding support for iOS, TensorFlow 0.9 adds a handful of other new features and improvements, as well as plenty of smaller bug fixes and performance enhancements. You can read the full change log below and access TensorFlow on GitHub.
Major Features and Improvements
Python 3.5 support and binaries
Added iOS support
Added support for processing on GPUs on MacOS
Added makefile for better cross-platform build support (C API only)
fp16 support for many ops
Higher level functionality in contrib.{layers,losses,metrics,learn}
More features to Tensorboard
Improved support for string embedding and sparse features
TensorBoard now has an Audio Dashboard, with associated audio summaries.
Big Fixes and Other Changes
Turned on CuDNN Autotune.
Added support for using third-party Python optimization algorithms (contrib.opt).
Google Cloud Storage filesystem support.
HDF5 support
Add support for 3d convolutions and pooling.
Update gRPC release to 0.14.
Eigen version upgrade.
Switch to eigen thread pool
tf.nn.moments() now accepts a shift argument. Shifting by a good estimate of the mean improves numerical stability. Also changes the behavior of the shift argument to tf.nn.sufficient_statistics().
Performance improvements
Many bugfixes
Many documentation fixes
TensorBoard fixes: graphs with only one data point, Nan values, reload button and auto-reload, tooltips in scalar charts, run filtering, stable colors
Tensorboard graph visualizer now supports run metadata. Clicking on nodes while viewing a stats for a particular run will show runtime statistics, such as memory or compute usage. Unused nodes will be faded out.
India successfully launched the first technology demonstrator of indigenously made Reusable Launch Vehicle (RLV), capable of launching satellites into orbit around earth and then re-enter the atmosphere, from Sriharikota near Chennai.
A booster rocket with the RLV-TD lifted up at 7 a.m. from the Satish Dhawan Space Centre, and the launch vehicle separated from it at an altitude of 50 km.
The RLV-TD or winged space plane then climed to another 20 km and began its descent. It re-entered to earth’s atmosphere at an hypersonic speed of more than 5 Mach and touched down the Bay of Bengal between Chennai and the Andaman archipelago. Known as hypersonic flight experiment, it was about 10 minutes mission from liftoff to splashdown.
An ISRO spokesman said the mission was accomplished successfully. “Everything went according to the projections” he said adding that the winged space plane will not be recovered from the sea.This successful experiment of the ISRO is only a very preliminary step towards developing reusable launch vehicles. Several flights of RLV-TD will have to be undertaken before it really becomes a reusable launch system to put satellites into orbit.
This project has been in the design board in one form or other for the past 10 years. It was called AVATAR, SLE and some other names. This is in-fact the first attempt to boost it out of the drawing board and into the launch platform. It will need at-least a dozen successful launches, each validating a multitude of technologies before the system can be put in production.
There are a multiple mission profiles for the proposed system. And it will infact bring down a significant portion of the launch cost down. Already the cost of launching a satellite or probe into LEO is way cheaper when using ISRO’s launch vehicle than say Ariane-space. But the cost shifts heavily in favour of the latter for a GTO. Which India herself uses often. There are several other technological benifits to the program, like Hypersonic flight profile study, Effective Heat Shielding, Autonomous Navigation and a lot more so called “Dual-USe” technologies can be spin-over.
I believe a hearty Congratulations are in order for the Project Team.
A Business Intelligence Strategy for Real-Time Analytics – RTInsights
In modern business, data flows in from a wide array of physical sensors and online user interactions in large volumes and at high speed. As a direct result of such speeds and volumes, the analysis of this data, as well as the data-driven decisions and actions, must be almost fully automated, with no more than rare exceptions being brought to human attention. The automobile example demonstrates clearly the ability of combined sensor and AI systems to recognize real-world situations and act accordingly.
This Article had in-depth analysis of the Strategy for BI. Worth your time.
Introduction
This series of How To or Case Study I am attempting to write was the result of the work of our team for the past 2+ years.We were developing a Predictive Analytics Platform for a global truck OEM. This was to be integrated with their live OBU data, Warranty, Research & Design, Customer Support, CRM and DMS among other things.
In this journey, we have attempted to solve the problem in incremental steps. Currently we are working on the predictive analytics with learning workflows. So, I believe Its time to pen down the experience with building the other 3 incremental solutions.
First Baby Step– Fast Data capture and Conventional Analytics –
Kafka, Redis, PostreSQL
Next Logical Step – Big Data capture, Warehousing and Conventional Analytics
Kafka, Storm/Spark, Hadoop/Hive, Zookeeper
The Bulls Eye – Real Time Analytics on Big-Data
Same as Above with Solr and Zeppelin
The Holy Grail – Predictive Analytics
Same as Above with MLib on Spark
Now, in this post I will write about “The First Baby Step”. This involves fast acquisition of data, Real-time analytics and long term data archival.
The disparate data sets and sources posed a significant complexity, not to mention the myriad polling frequencies, sync models and EOD jobs. It goes without saying that the #OEM had a significant investment in SAP infrastructure. We had studied multiple architecture models, (Some are available in this Reference Architecture Model from Horton Works and SAP)
The following are the considerations from the data perspective,
FastData – Realtime Telematics data from the OBU.
BigData – Diagonastics data from each truck had 40+ parameters and initial pilot of 7500 trucks.
Structured Data – Data from Dealer Management System and Customer Relationship Management System.
Transactional Data – Data from Warranty management and Customer Support systems.
Fast Data: Our primary challenge for the 1st phase of design/development was the scaling of the data acquisition system to collect data from thousands of nodes, each of which sent 40 sensor readings polled once per second and transmitted every 6 seconds once. While maintaining the ability to query the data in real time for event detection. While each data record was only ~300kb, our expected maximum sensor load indicated a collection rate of about 27 million records, or 22.5GB, per hour. However, our primary issue was not data size, but data rate. A large number of inserts had to happen each second, and we were unable to buffer inserts into batches or transactions without incurring a delay in the real-time data stream.
When designing network applications, one must consider the two canonical I/O bottlenecks: Network I/O, and Filesystem I/O. For our use case, we had little influence over network I/O speeds. We had no control over the locations where our truck sensors would be at any given time, or in the bandwidth or network infrastructure of said location (Our OBDs communicated using GPRS on GSM Network). With network latency as a known variant, we focused on addressing the bottleneck we could control: Filesystem I/O. For the immediate collection problem, this means we evaluated databases to insert the data into as it was collected. While we initially attempted to collect the data in a relational database (PostgreSQL), we soon discovered that while PostgreSQL could potentially handle the number of inserts per second, it was unable to respond to read queries simultaneously. Simply put, we were unable to read data while we were collecting it, preventing us from doing any real-time analysis (or any analysis at all, for that matter, unless we stopped data collection).
The easiest way to avoid slowdowns due to disk operations is to avoid the disk altogether, we mitigated this by leveraging Redis, an open-source in-memory NoSQL datastore. Redis stores all data in RAM and in hybrid models in Flash storage (like an SSD) allowing lightning fast reads and writes. With Redis, we were easily able to insert all of our collected data as it was transmitted from the sensor nodes, and query the data simultaneously for event detection and analytics. In fact, were were also able to leverage Pub/Sub functionality on the same Redis server to publish notifications of detected events for transmission to event driven workers, without any performance issues.
In addition to speed, Redis features advanced data structures, including Lists, Sets, Hashes,Geospatials and Sorted Sets, rather than the somewhat limiting key/value pair consistent with many NoSQL stores. Available Data Structures in Redis Sorted Sets proved to be an excellent data structure to model timeseries data, by setting the score to the timestamp of a given datapoint. This automatically ordered our timeseries’, even when data was inserted out of order, and allowed querying by timestamp, timestamp range, or by “most recent #” of records (which is merely the last # values of the set).
Our use case requires us to archive our data for a period of time, enabling the business users to run a historical analytics along with data from the real-time source.
Enter Data Temperatures, Data Temperatures Hot Data – The data which is frequently accessed and is currently being polled/gathered. Warm Data – The data which is currently not being polled but still frequently used. Cold Data – The data that is in warehouse-mode, but still can be accessed for BI or analytics jobs with a bit of I/O Overhead.
Since Redis keeps all data in RAM that is the HOT Area, our Redis datastore was only able to hold as much data as the server had “Available RAM”. Our data, inserted at a rate of 27GB/hour, quickly outgrew this limitation. To scale this solution and archive our data for future analysis, we set up an automated migration script to push the oldest data in our Redis datastore to a PostgreSQL database with more storage scalability. As explained above, since Redis has native data types for Time Series data, it was a simple enough process for the Load operation.
The other consideration to be exercised is the “Available RAM”. As the amount of data that is queried, CPU cycles used and the RAM used for the Processing determines the amount of memory available for data stores. be reminded if the data-stores are fill to the brim your processing job is going to utulise the disk I/O. Which is very bad.
We wrote a REST API as an interface to our two datastores allowing client applications a unified query interface, without having to worry about which data-store a particular piece of data resided in. This web-service layer defined the standards for the time, range and parameters. Fast Data Architecture with Redis and Kafka
With the above represented architecture in place, generating automated event detection and real-time notifications was feasible, again through the use of Redis. Since Redis also offers Pub/Sub functionality, we were able to monitor incoming data in Redis using a small service, and push noteworthy events to a notification channel on the same Redis server, from which subscribed SMTP workers could send out notifications in real-time. This can even be channeled to an MQ/ESB or any Asynchronous mechanism to initiate actions or reactions.
Our experiences show Kafka and Redis to be a powerful tool for Big Data applications, specifically for high-throughput data collection. The benefits of Kafka as a collection mechanism, coupled with inmemory data storage using Redis and data migration to a deep analytics platform, such as relational databases or even Hadoop’s HDFS, yields a powerful and versatile architecture suitable for many Big Data applications.
After we have implemented HDFS and Spark in Phase 2-3 of this roadmap, we have of-course configured redis in the said role. Hope I have covered enough of the 1st step in our Big-Data journey. Will write an article per week regarding the other 3 phases we have implemented successfully.