Sovereign Cryptography and the Strategic Evolution of the Guomi Suite: A Technical Analysis of SM3 and SM4
The global transition toward decentralised and sovereign cryptographic standards represents one of the most significant shifts in the history of information security. For decades, the international community relied almost exclusively on a handful of standards, primarily those vetted by the National Institute of Standards and Technology (NIST) in the United States. However, the emergence of the ShāngMì (SM) series, collectively known as the Guomi suite, has fundamentally altered this landscape.1 These Chinese national standards, including the SM2 public-key algorithm, the SM3 hash function, and the SM4 block cypher, were initially developed to secure domestic critical infrastructure but have since achieved international recognition through ISO/IEC standardisation and integration into global protocols like TLS 1.3.2
Following my 2023 article on SM2 Public Key Encryption, this follow-on provides a technical evaluation of the Guomi suite, focusing on the architectural nuances of SM3 and SM4. And considering I have spent the last 24 months under the tutelage of some of the finest Cryptographers and Infosec Practioners in the world at the ISG, Royal Holloway, University of London, this one should be more grounded and informative.
I have tried to analyse the computational efficiency, keyspace resilience, and the strategic importance of “cover-time.” This report examines why these algorithms are increasingly viewed as viable, and in some contexts superior, alternatives to Western counterparts like SHA-256 and AES. Furthermore, it situates these technical developments within the broader geopolitical context of cryptographic sovereignty, exploring the drive for independent verification without ideological bias.
Technical Architecture of the SM3 Hashing Algorithm
The SM3 cryptographic hash algorithm, standardised as ISO/IEC 10118-3:2018, is a robust 256-bit hash function designed for high-security commercial applications.3 Built upon the classic Merkle-Damgård construction, it shares structural similarities with the SHA-2 family but introduces specific innovations in its compression function and message expansion logic that significantly improve its resistance to collision and preimage attacks.6
Iteration Compression and Message Expansion
SM3 processes input messages of length bits through an iterative compression process. The message is first padded to a length that is a multiple of 512 bits. Specifically, the padding involves appending a “1” bit, followed by
zero bits, where
is the smallest non-negative integer satisfying
.6 Finally, a 64-bit representation of the original message length
is appended.6
The padded message is divided into 512-bit blocks . For each block, a message expansion process generates 132 words (
and
).3 This expansion is more complex than that of SHA-256, utilizing a permutation function
to enhance nonlinearity and bit-diffusion.6
The expansion logic for a message block is defined as follows:
- Divide
into 16 words
.
- For
to
:
- For
to
:
3
This expanded word set is then processed through a 64-round compression function utilising eight 32-bit registers ( through
). The compression function
employs two sets of Boolean functions,
and
, which vary depending on the round number.3
| Round Range (j) | FFj(X,Y,Z) | GGj(X,Y,Z) | Constant Tj |
| 0x79cc4519 | |||
| 0x7a879d8a |
The split in logic between the first 16 rounds and the subsequent 48 rounds is a strategic defence against bit-tracing. The initial rounds rely on pure XOR operations to prevent linear attacks, while the later rounds introduce nonlinear operations to ensure high diffusion and resistance to differential cryptanalysis.6
Performance and Computational Efficiency
While SM3 is structurally similar to SHA-256, its “Davies-Meyer” construction utilises XOR for chaining values, whereas SHA-256 uses modular addition.8 This architectural choice, combined with the more complex message expansion, historically led to the perception that SM3 is slower in software.8 However, contemporary performance evaluations on modern hardware present a different narrative. Research into GPU-accelerated hash operations, specifically the HI-SM3 framework, shows that SM3 can achieve remarkable throughput when parallelism is properly leveraged. On high-end NVIDIA hardware, SM3 has reached peak performance of 454.74 GB/s, outperforming server-class CPUs by over 150 times.11 Even on lower-power embedded GPUs, SM3 has demonstrated a throughput of 5.90 GB/s.11 This suggests that the complexity of the SM3 compression function is well-suited for high-throughput environments such as blockchain validation and large-scale data integrity verification, where GPU offloading is available.7
The SM4 Block Cipher: Robustness and Symmetric Efficiency
SM4 (formerly SMS4) is the first commercial block cipher published by the Chinese State Cryptography Administration in 2006.2 It operates on 128-bit blocks using a 128-bit key, positioning it as the primary alternative to AES-128.2 Unlike the Substitution-Permutation Network (SPN) structure of AES, SM4 utilizes an unbalanced Feistel structure, where the encryption and decryption processes are identical, differing only in the sequence of round keys.2
Round Function and Key Schedule
The SM4 algorithm consists of 32 identical rounds. Each round takes four 32-bit words as input and uses a round key to produce a new word.14 The round function
involves a nonlinear substitution step (S-box) and a linear transformation
.2
The substitution function is defined by:
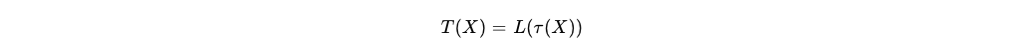
where is the nonlinear S-box transformation, applying four independent 8-bit S-boxes in parallel.16 The S-box is constructed via a multiplicative inverse over the finite field
, followed by an affine transformation.2
A critical advantage of the Feistel structure in SM4 is the elimination of the need for an inverse S-box during decryption.16 In AES, hardware implementations must account for both the S-box and its inverse, increasing gate counts.16 SM4’s symmetric round structure allows for more compact hardware designs, which is particularly beneficial for resource-constrained IoT devices and smart cards.2
Algebraic Attack Resistance
One of the most compelling arguments for SM4’s superiority in certain security contexts is its resistance to algebraic attacks. Studies comparing the computational complexities of algebraic attacks (such as the XL algorithm) against SM4 and AES suggest that SM4 is significantly more robust.20 This robustness is derived from the complexity of its key schedule and the overdefined systems of quadratic equations it produces. 20
| Algorithm | Key Variables | Intermediate Variables | Eqns (Enc) | Eqns (Key) | Complexity |
| AES | 320 | 1280 | 8960 | 2240 | |
| SM4 | 1024 | 1024 | 7168 | 7168 | Higher than AES |
The SM4 key schedule utilises nonlinear word rotations and S-box lookups, creating a highly complex relationship between the master key and the round keys.16 This makes the system of equations representing the cipher more difficult to solve than the relatively linear key expansion used in AES-128.20
SM2 and the Parallelism of Elliptic Curve Standards
Asymmetric cryptography is essential for key exchange and digital signatures. The SM2 standard is an elliptic curve cryptosystem (ECC) based on 256-bit prime fields, authorized for core, ordinary, and commercial use in China.21 While Western systems often default to NIST P-256 (secp256r1), SM2 provides a state-verified alternative that addresses concerns regarding parameter generation and “backdoor” potential in special-form curves.22
Curve Parameters and Design Philosophies
NIST curves are designed for maximum efficiency, utilizing quasi-Mersenne primes that facilitate fast modular reduction.26 However, the method used to select NIST parameters has faced criticism for a lack of transparency, leading to the development of “random” curves like the Brainpool series, which prioritize verifiable randomness at the cost of performance.25
SM2 occupies a strategic middle ground. It recommends a specific 256-bit curve but follows a design philosophy that aligns with the need for national security verification.22
| Parameter | SM2 (GB/T 32918.1-2016) | NIST P-256 (FIPS 186-4) |
| p | 0xFFFFFFFE FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF 00000000 FFFFFFFF FFFFFFFF | 2^256 – 2^224 + 2^192 + 2^96 – 1 |
| a | 0xFFFFFFFE FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF 00000000 FFFFFFFF FFFFFFFC | p – 3 |
| b | 0x28E9FA9E 9D9F5E34 4D5A9E4B CF6509A7 F39789F5 15AB8F92 DDBCBD41 4D940E93 | (Pseudo-random seed derivative) |
| n | 0xFFFFFFFE FFFFFFFF FFFFFFFF FFFFFFFF 7203DF6B 21C6052B 53BBF409 39D54123 | (Prime order of base point) |
| h | 1 | 1 |
The performance of SM2 is highly competitive with ECDSA. In optimised 8-bit implementations, SM2 scalar multiplication has set speed records, outperforming even the NIST P-192 curve in certain conditions.19 Against the traditional RSA algorithm, SM2 offers a significant efficiency gain; a 256-bit SM2 key provides security equivalent to a 3072-bit RSA key while requiring far less computational power for key generation and signature operations.21
Verification and Trust in ECC
The core of the “better option” argument for SM2 lies in trust and diversity. If a vulnerability were discovered in the specific mathematical form of NIST-recommended curves, the entire global financial and communication infrastructure could be at risk.24 By maintaining an independent, state-verified standard, the Guomi suite ensures cryptographic diversity, preventing a single point of failure in the global security ecosystem.32 This is particularly relevant as the community evaluates “nothing-up-my-sleeve” numbers; SM2 provides a layer of assurance for those who prefer an alternative to NIST-vetted parameters. 22
Security Metrics: Keyspace, Work Factor, and Cover Time
The strength of any cryptographic system is measured not only by its mathematical complexity but also by its practical resistance to brute-force and analytical attacks over time. Three key concepts are central to this evaluation: keyspace, work factor, and cover time.
Keyspace and Brute-Force Resilience
The keyspace of SM4 is , which is identical to AES-128.2 In today’s computational environment, cracking a 128-bit key through brute force is infeasible, requiring trillions of years on the most powerful existing supercomputers.35 While AES-256 offers a larger keyspace, the 128-bit security level remains the global benchmark for standard commercial encryption.35
SM3, with its 256-bit output, provides a security margin of 128 bits against collision attacks, which is equivalent to SHA-256.37 The “work factor”—the estimate of effort or time needed for an adversary to overcome a protective measure—is a function of this keyspace and the specific algorithmic efficiency of the attack method.39
The Critical Dimension of Cover Time
“Cover time” refers to the duration for which a plaintext must be kept secret.41 This metric is vital because all ciphers (excluding one-time pads) are theoretically breakable given enough time and energy.43
- Tactical Cover Time: For time-critical data, such as a command to launch a missile, the cover time might only be a few minutes. If an algorithm protects the data for an hour, it is sufficient. 42
- Strategic Cover Time: For financial records or diplomatic communications, the cover time may be 6 years or more.44
The concept of cover time is now being re-evaluated through the lens of “Harvest Now, Decrypt Later” (HNDL).33 Adversaries are currently collecting encrypted traffic with the intention of decrypting it once cryptographically relevant quantum computers (CRQC) arrive, a date often referred to as “Q-Day”.33 If the cover time of a piece of data exceeds the time remaining until Q-Day, that data is already effectively compromised if intercepted today.45The SM-series algorithms contribute to a longer cover time by providing resistance to classical analytical breakthroughs. Because SM3 and SM4 possess distinct internal designs from the MD4/MD5 lineage and SPN-based ciphers, they offer a hedge against “all-eggs-in-one-basket” scenarios where a new mathematical attack might break one family of algorithms but not another. 32
The Geopolitics of Independent Cryptographic Standards
The development of the Guomi suite is a manifestation of “Cryptographic Sovereignty”—a nation’s ability to govern, secure, and assert authority over its digital environment without overreliance on foreign technology.47 This move is motivated by the desire for technological autonomy and the belief that commercial readiness should precede international policy enforcement.32
Sovereignty versus Autonomy
In the context of modern state power, digital sovereignty extends beyond physical borders into the informational domain.48 For many nations, relying on the encryption standards of a geopolitical rival is seen as a strategic vulnerability. The 2013 revelations regarding NIST standards and potential backdoors served as a wake-up call, accelerating the global drive toward national encryption algorithms.1
- Chinese Context: The 2020 Cryptography Law of the People’s Republic of China distinguishes between core, ordinary, and commercial cryptography.15 It mandates the use of SM-series algorithms for critical information infrastructure and commercial data, ensuring that national algorithms protect national secrets.47
Global Impact: This mandate has fundamentally impacted global supply chains. Multinational entities operating in China must implement TLS 1.3 with SM2, SM3, and SM4 to remain compliant with the Multi-Level Protection Scheme (MLPS 2.0).4 Utilising a Western-only platform secured by AES-256 is, from a legal standpoint in that jurisdiction, equivalent to submitting an unsigned document.47
Strategic Diversity in the Post-Quantum Era
The impulse toward digital sovereignty is often equated with control, but from a technical perspective, it is a project of “thick autonomy”.50 By diversifying the algorithmic landscape, the international community becomes more resilient to systemic risks.32 If a major breakthrough were to compromise lattice-based post-quantum schemes, the existence of alternative code-based or hash-based sovereign standards would provide a vital safety net.32
This drive for independence is not unique to China. Countries like Indonesia and various European states are increasingly exploring “indigenous algorithm design” and “sovereign cryptographic systems” to ensure long-term digital independence.48 The goal is not to isolate but to ensure that the “invisible backbone” of the digital economy, cryptography, is not entirely dependent on a single geopolitical actor.33
Implementation and TLS 1.3 Integration
The practical viability of the Guomi suite is demonstrated by its integration into standard internet protocols. RFC 8998 provides the specification for using SM2, SM3, and SM4 within the TLS 1.3 framework.4 This is critical for ensuring that high-security products can maintain interoperability while meeting national security requirements.3
TLS 1.3 Cipher Suites
RFC 8998 defines two primary cipher suites that utilize the Guomi algorithms to fulfill the confidentiality and authenticity requirements of TLS 1.3:
- TLS_SM4_GCM_SM3 (0x00, 0xC6)
- TLS_SM4_CCM_SM3 (0x00, 0xC7) 4
These suites use SM4 in either Galois/Counter Mode (GCM) or Counter with CBC-MAC (CCM) mode to provide Authenticated Encryption with Associated Data (AEAD).4
| Feature | AEAD_SM4_GCM | AEAD_SM4_CCM |
| Key Length | 16 octets (128 bits) | 16 octets (128 bits) |
| Nonce/IV Length | 12 octets | 12 octets |
| Authentication Tag | 16 octets | 16 octets |
| Max Plaintext | octets |
The choice between GCM and CCM often depends on the underlying hardware; GCM is widely preferred for its high-speed parallel processing capabilities, whereas CCM is often utilised in wireless standards like WAPI where resource constraints are more acute.2
Hardware and Software Ecosystem
A robust ecosystem has emerged to support the Guomi suite. The primary open-source implementation is GmSSL, a fork of OpenSSL specifically optimized for SM algorithms.2 In terms of hardware, support has expanded significantly:
- Intel: Processors starting from Arrow Lake S, Lunar Lake, and Diamond Rapids include native SM4 support.2
- ARM: The ARMv8.4-A expansion includes dedicated SM4 instructions.2
- RISC-V: The Zksed extension for RISC-V, ratified in 2021, provides ratified support for SM4.2
This hardware integration is crucial for narrowing the performance gap between SM4 and AES-128. Specialised ISA extensions can reduce the instruction count for an SM4 step to just 6.5 arithmetic instructions, making it a highly efficient choice for high-speed TLS communication and secure storage in mobile devices.16
Hands-on Primer: Implementing Guomi Locally
To truly appreciate the technical nuances of the Guomi suite, it is essential to move beyond the theoretical and experiment with these algorithms in a controlled environment. Most modern systems can support Guomi implementation through two primary channels: the GmSSL command-line toolkit and high-level Python libraries.
Command-Line Walkthrough: GmSSL and OpenSSL
The standard tool for interacting with SM algorithms is GmSSL, an open-source project that implements SM2, SM3, and SM4. While standard OpenSSL has added support for these algorithms, GmSSL remains the reference implementation for developers seeking the full range of national standards.
- SM2 Key Generation:
Generating an SM2 private key results in an ASN.1 structured file (often .sm2 or .pem).Bash
# Generate a private key
gmssl sm2 -genkey -out private_key.pem
# Derive the public key (the (x, y) coordinates of point Q)
gmssl sm2 -pubout -in private_key.pem -out public_key.pem - SM3 Hashing:
Hash a file to verify its integrity, equivalent to a 256-bit “digital fingerprint.”Bash
gmssl sm3 <your_file.txt>
3. SM4 Symmetric Encryption:
Encrypt a file using SM4 in CBC mode, which requires a 128-bit key and an initialisation vector (IV).Bash
gmssl sms4 -e -in message.txt -out message.enc
Python Code Walkthrough: pygmssl
For developers building applications, Python provides straightforward wrappers such as pygmssl that abstract the complexity of C-based implementations.
Step 1: Environment Setup
Install the library via pip:
Bash
pip install pygmsslStep 2: Hashing with SM3
The library requires input data to be formatted as bytes. Strings must be encoded before processing.
Python
from pygmssl.sm3 import SM3
data = b"hello, world"
# Compute hash in a single call
print(f"SM3 Hash: {SM3(data).hexdigest()}")
# Or hash by part for streaming data
s3 = SM3()
s3.update(b"hello, ")
s3.update(b"world")
print(f"Streaming Hash: {s3.hexdigest()}")Step 3: Symmetric Encryption with SM4
SM4 operates on 128-bit blocks, making it highly efficient for bulk data encryption when used in modes like CBC.
Python
from pygmssl.sm4 import SM4, MOD
# Key and IV must be 16 bytes (128 bits)
key = b'0123456789abcdef'
iv = b'fedcba9876543210'
cipher = SM4(key, mode=MOD.CBC, iv=iv)
plaintext = b"sensitive data"
# The library handles padding (typically PKCS7) automatically
ciphertext = cipher.encrypt(plaintext)
decrypted = cipher.decrypt(ciphertext)
assert plaintext == decryptedStep 4: Asymmetric Identity with SM2
SM2 can be used to generate key pairs and sign messages, proving possession of a private key without disclosing it.
Python
from pygmssl.sm2 import SM2
# Generate a new pair: 32-byte private key, 64-byte public key (x,y)
s2 = SM2.generate_new_pair()
print(f"Private Key: {s2.pri_key.hex()}")
print(f"Public Key: {s2.pub_key.hex()}")
This hands-on accessibility ensures that organisations can test for “crypto-agility” and compatibility within their local development cycles before committing to regional deployments.
Strategic Option
The determination of whether an encryption standard is “better” is contextual. When evaluated against the requirements of the modern geopolitical and technical era, the Guomi suite offers several unique advantages over the exclusive use of Western standards.
Diversity as a Defense Strategy
Systemic risk reduction is perhaps the strongest technical argument for adopting SM3 and SM4 alongside traditional standards.32 A “monoculture” in cryptography—where everyone uses the same NIST curves and SHA-2 functions—is a security vulnerability.32 A breakthrough against one design would leave the global economy exposed.33 The Guomi suite provides a separate mathematical lineage, ensuring that the digital landscape remains resilient even if unforeseen vulnerabilities are found in SPN-based ciphers or specific ECC parameter sets.32
Computational and Algebraic Superiority
- Hashing Efficiency: While SHA-256 remains the global baseline, SM3’s structural design is highly optimized for GPU parallelism, making it a “better” option for emerging high-throughput applications like distributed ledgers and real-time data integrity audits.7
- Symmetric Robustness: SM4’s Feistel structure offers a more compact hardware profile than AES and exhibits greater resistance to algebraic attacks, which are a primary concern in the era of advanced analytical cryptanalysis.16
- Asymmetric Versatility: SM2 offers a state-vetted alternative to NIST curves, avoiding the “black box” controversies that have plagued Western ECC while providing a significant performance leap over legacy RSA systems.21
Navigating the Geopolitical Reality
From a strategic standpoint, an independent encryption standard is a prerequisite for state autonomy.48 For organisations operating globally, “crypto-agility”, he ability to support both NIST and Guomi suites is no longer optional; it is a regulatory and commercial necessity.34 The transition to sovereign standards ensures that the “cover time” of sensitive data is protected not just by the length of a key, but by the independence of the verification process and the diversity of the underlying mathematics. 32 As we approach the quantum era and the potential of “Q-Day,” the maturity of the Guomi suite provides a vital fallback. Its international standardisation and robust hardware support signify that China’s recommended algorithms have transitioned from a regional requirement to a foundational element of the global secure communication framework. The case for SM3 and SM4 is not one of replacing existing standards, but of expanding the arsenal of cryptographic tools available to defend the integrity and confidentiality of the world’s digital infrastructure.32
References & Further Reading:
- SM4 modes: CBC, CFB, OFB, and ECB – ASecuritySite.com, accessed on April 7, 2026, https://asecuritysite.com/symmetric/symsm4
- SM4 (cipher) – Wikipedia, accessed on April 7, 2026, https://en.wikipedia.org/wiki/SM4_(cipher)
- SM3 Cryptographic Hash Algorithm in a Nutshell – Zhejiang Dahua Technology Co., Ltd., accessed on April 7, 2026, https://www.dahuasecurity.com/about-dahua/trust-center/secure-and-trust/sm3-cryptographic-hash-algorithm-in-a-nutshell
- RFC 8998: ShangMi (SM) Cipher Suites for TLS 1.3, accessed on April 7, 2026, https://www.rfc-editor.org/rfc/rfc8998.html
- SM3 (hash function) – Wikipedia, accessed on April 7, 2026, https://en.wikipedia.org/wiki/SM3_(hash_function)
- draft-sca-cfrg-sm3-01 – The SM3 Cryptographic Hash Function – IETF Datatracker, accessed on April 7, 2026, https://datatracker.ietf.org/doc/draft-sca-cfrg-sm3/01/
- SHA3-256 vs SM3 | Compare Top Cryptographic Hashing Algorithms – MojoAuth, accessed on April 7, 2026, https://mojoauth.com/compare-hashing-algorithms/sha3-256-vs-sm3
- On the Design and Performance of Chinese OSCCA-approved Cryptographic Algorithms – BTH, accessed on April 7, 2026, https://bth.diva-portal.org/smash/get/diva2:1444129/FULLTEXT01.pdf
- On the Design and Performance of Chinese OSCCA-approved …, accessed on April 7, 2026, https://www.researchgate.net/publication/342996423_On_the_Design_and_Performance_of_Chinese_OSCCA-approved_Cryptographic_Algorithms
- on the design and performance of chinese oscca-approved cryptographic algorithms | promis, accessed on April 7, 2026, https://promisedu.se/wp-content/uploads/2020/07/ilie2020-design_and_performance_of_chinese_cryptographic_algorithms.pdf
- HI-SM3: High-Performance Implementation of SM3 Hash Function on Heterogeneous GPUs, accessed on April 7, 2026, https://jcst.ict.ac.cn/article/cstr/32374.14.s11390-025-4285-7
- HMAC-SHA3-256 vs SM3 | Compare Top Cryptographic Hashing Algorithms – MojoAuth, accessed on April 7, 2026, https://mojoauth.com/compare-hashing-algorithms/hmac-sha3-256-vs-sm3
- View of Discussion and Optimization of AES and SM4 Encryption Algorithms, accessed on April 7, 2026, https://drpress.org/ojs/index.php/fcis/article/view/30618/30000
- Cryptography – SM4 Encryption Algorithm – TutorialsPoint, accessed on April 7, 2026, https://www.tutorialspoint.com/cryptography/cryptography_sm4_encryption_algorithm.htm
- Introduction to the Commercial Cryptography Scheme in China – International Cryptographic Module Conference (ICMC), accessed on April 7, 2026, https://icmconference.org/wp-content/uploads/C23Introduction-on-the-Commercial-Cryptography-Scheme-in-China-20151105.pdf
- A Lightweight ISA Extension for AES and SM4 – arXiv, accessed on April 7, 2026, https://arxiv.org/pdf/2002.07041
- A Secure and Efficient White-Box Implementation of SM4 – PMC, accessed on April 7, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC11764595/
- AES S-box as simple algebraic transformation – Math Stack Exchange, accessed on April 7, 2026, https://math.stackexchange.com/questions/4948050/aes-s-box-as-simple-algebraic-transformation
- Lightweight Implementations of NIST P-256 and SM2 ECC on 8-bit Resource-Constraint Embedded Device | Request PDF – ResearchGate, accessed on April 7, 2026, https://www.researchgate.net/publication/332339930_Lightweight_Implementations_of_NIST_P-256_and_SM2_ECC_on_8-bit_Resource-Constraint_Embedded_Device
- Algebraic attack to SMS4 and the comparison with AES – ResearchGate, accessed on April 7, 2026, https://www.researchgate.net/publication/220793576_Algebraic_attack_to_SMS4_and_the_comparison_with_AES
- What Makes SM2 Encryption Special? China’s Recommended …, accessed on April 7, 2026, https://nocturnalknight.co/what-makes-sm2-encryption-special-chinas-recommended-algorithm/
- oscca sm2 – DiSSECT, accessed on April 7, 2026, https://dissect.crocs.fi.muni.cz/standards/oscca
- rfc-crypto-sm2/sections/03-sm2.md at master – GitHub, accessed on April 7, 2026, https://github.com/riboseinc/rfc-crypto-sm2/blob/master/sections/03-sm2.md
- RFC 9563 – » RFC Editor, accessed on April 7, 2026, https://www.rfc-editor.org/rfc/rfc9563.txt
- Why I don’t Trust NIST P-256 | Credelius, accessed on April 7, 2026, https://credelius.com/credelius/?p=97
- Elliptic curve performance: NIST vs. Brainpool – Mbed TLS documentation – Read the Docs, accessed on April 7, 2026, https://mbed-tls.readthedocs.io/en/latest/kb/cryptography/elliptic-curve-performance-nist-vs-brainpool/
- SafeCurves: Introduction, accessed on April 7, 2026, https://safecurves.cr.yp.to/
- SM2 – Standard curve database, accessed on April 7, 2026, https://std.neuromancer.sk/oscaa/SM2/
- Public Key cryptographic algorithm SM2 based on elliptic curves Part 5: Parameter definition, accessed on April 7, 2026, http://www.gmbz.org.cn/upload/2018-07-24/1532401863206085511.pdf
- Lightweight Implementations of NIST P-256 and SM2 ECC on 8-bit Resource-Constraint Embedded Device | Semantic Scholar, accessed on April 7, 2026, https://www.semanticscholar.org/paper/Lightweight-Implementations-of-NIST-P-256-and-SM2-Zhou-Su/40b68e5dc8f777530cdd49f08d0d6abc23204baa
- Enhancing security in instant messaging systems with a hybrid SM2, SM3, and SM4 encryption framework – PMC, accessed on April 7, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC12435676/
- cryptography – Nocturnalknight’s Lair, accessed on April 7, 2026, https://nocturnalknight.co/category/information-security/cryptography/
- Implementation of Quantum Safe Ecosystem in India – Department Of Science & Technology, accessed on April 7, 2026, https://dst.gov.in/sites/default/files/Report_TaskForce_PQMigration_4Feb26%20%28v1%29.pdf
- Post Quantum Cryptography – Nocturnalknight’s Lair, accessed on April 7, 2026, https://nocturnalknight.co/category/post-quantum-cryptography/
- AES-128 Vs AES-256 : Real-World Differences (Speed, HW Accel, Risk) – Newsoftwares.net, accessed on April 7, 2026, https://www.newsoftwares.net/blog/aes-128-vs-aes-256-real-world-differences/
- AES-256 vs AES-128: Head to Head – Symlex VPN, accessed on April 7, 2026, https://symlexvpn.com/difference-between-256-and-128/
- I’m writing a high school essay comparing SHA-3 and SHA-2. Need some help on what kind of experimentation i can do to compare them : r/cryptography – Reddit, accessed on April 7, 2026, https://www.reddit.com/r/cryptography/comments/pt7qon/im_writing_a_high_school_essay_comparing_sha3_and/
- Choosing a hash function for 2030 and beyond: SHA-2 vs SHA-3 vs BLAKE3, accessed on April 7, 2026, https://kerkour.com/fast-secure-hash-function-sha256-sha512-sha3-blake3
- New bounds for randomized busing | Request PDF – ResearchGate, accessed on April 7, 2026, https://www.researchgate.net/publication/222550333_New_bounds_for_randomized_busing
- Elsevier’s Dictionary of Information Security – PDF Free Download – epdf.pub, accessed on April 7, 2026, https://epdf.pub/elseviers-dictionary-of-information-security.html
- Topics in Algebra: Cryptography, accessed on April 7, 2026, https://www.mat.univie.ac.at/~gagt/crypto2019/C1.pdf
- Implementing Cryptography – CGISecurity.com, accessed on April 7, 2026, https://www.cgisecurity.com/owasp/html/ch13s06.html
- cryptography | Atmel | Bits & Pieces – WordPress.com, accessed on April 7, 2026, https://atmelcorporation.wordpress.com/tag/cryptography/
- ECS655U Security Engineering – Shona QMUL – WordPress.com, accessed on April 7, 2026, https://shonaqmul.wordpress.com/category/modules/year-3/year-3-semester-b/ecs655u-security-engineering/
- The State of Post-Quantum Cryptography (PQC) on the Web | F5 Labs, accessed on April 7, 2026, https://www.f5.com/labs/articles/the-state-of-pqc-on-the-web
- What is the difference between SHA-3 and SHA-256? – Cryptography Stack Exchange, accessed on April 7, 2026, https://crypto.stackexchange.com/questions/68307/what-is-the-difference-between-sha-3-and-sha-256
- What Cryptographic Algorithms Are Mandated for Remote Interpretation Data in China?, accessed on April 7, 2026, https://translate.hicom-asia.com/question/what-cryptographic-algorithms-are-mandated-for-remote-interpretation-data-in-china/
- Information Security and Digital Sovereignty: A Cyber–Crypto–Signal Defense Model for Indonesia – ResearchGate, accessed on April 7, 2026, https://www.researchgate.net/publication/399768275_Information_Security_and_Digital_Sovereignty_A_Cyber-Crypto-Signal_Defense_Model_for_Indonesia
- Cryptography Law: OSCCA Seeks Public Comments on the Cryptography Law | China Law Vision, accessed on April 7, 2026, https://www.chinalawvision.com/2017/05/intellectual-property/cryptography-law-oscca-seeks-public-comments-on-the-cryptography-law/
- Thin sovereignty, thick autonomy – Binding Hook, accessed on April 7, 2026, https://bindinghook.com/thin-sovereignty-thick-autonomy/
- RFC 8998 – ShangMi (SM) Cipher Suites for TLS 1.3 – IETF Datatracker, accessed on April 7, 2026, https://datatracker.ietf.org/doc/html/rfc8998