Achieve Peak Performance: AI Tools for Developers to Unlock Their Potential
You were scrolling through Twitter or your favourite SubReditt on the latest tech trend and a sudden feeling of FOMO creeps in. You’re not alone.
While the notion of a “10x developer” has traditionally been considered aspirational, the emergence of AI-powered tools is levelling the playing field, empowering developers to achieve remarkable productivity gains. While there might be 1000s of possible “AI tools”, I’ll restrict to tools which could yield a direct productivity boost to a developer’s day-to-day work as well as the outcome.
1. AI Pair-Developer / Code Assistants
Sourcegraph Cody & Github Copilot — Read, write and understand code
If you have used GitHub Copilot. Think of a Cody as a Turbocharger for Copilot. If you have not used Copilot, you should first try it. Either of these can understand your entire codebase, code graphs, and documentation and help you write efficient code, write unit tests, and document the codebase for you.
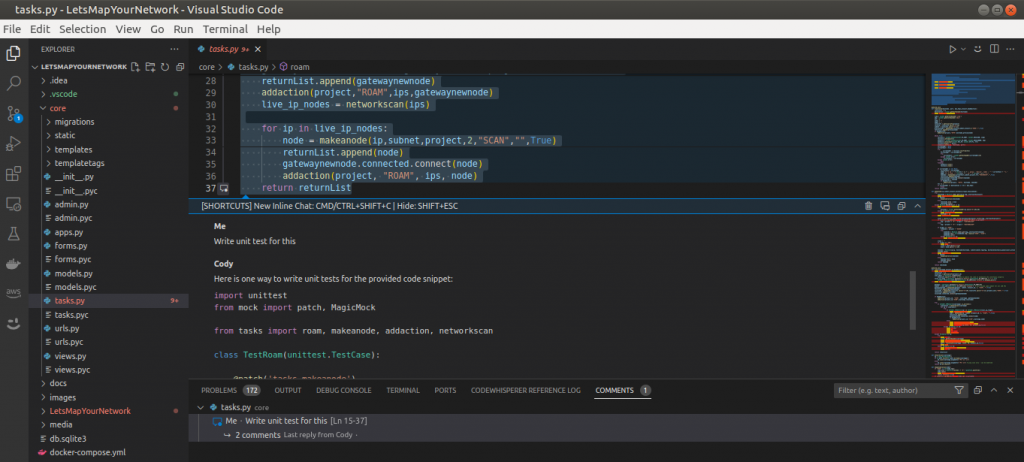
While the claim of a 10x speed increase is not substantiated, it shows clear intent to improve productivity drastically. However, it’s in beta, and the tool acknowledges that it’s not always correct, though they’re making rapid improvements. Yes, GitHub Copilot X is there — but then, your organisation needs to be on the Enterprise plan or you might have to add an additional $10-20 per user per month, and Cody is already here.
2. AI Code reviews – Offload the often mundane task of code reviews
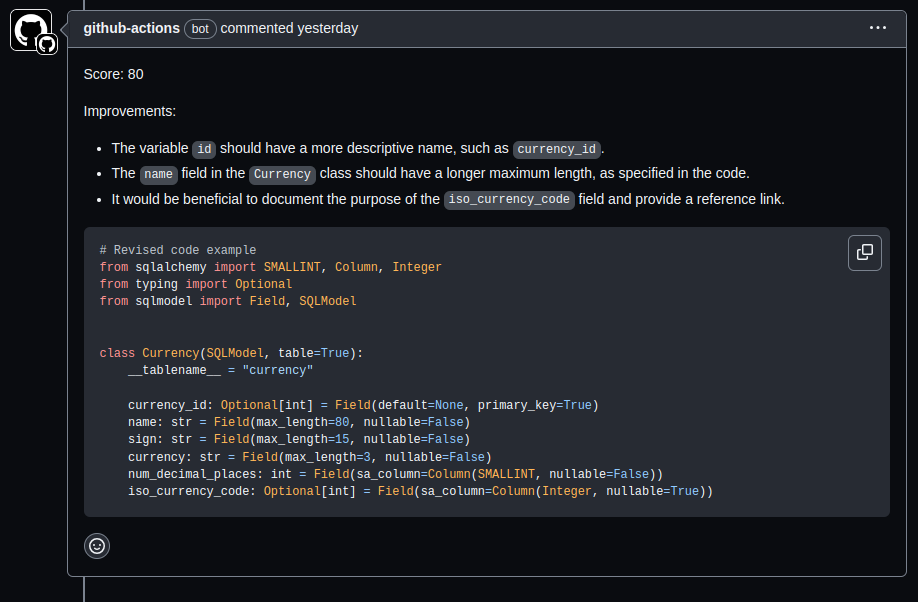
While CodeRabbit and DeepCode (now acquired by Snyk) are some of the trailblazers in this space, I have not had the opportunity to work with either of them for any stretch of time. If you know about their relative strengths or benefits, please add a comment, and I will incorporate it.
The tool I use most regularly is called Robin-AI-Reviewer, from the good folks at Integral Healthcare (funded by Haystack). My reasoning is two-fold, It is open-source and if it is good enough for HIPPA-compliant app development and certification assessment, it’s a good starting point.
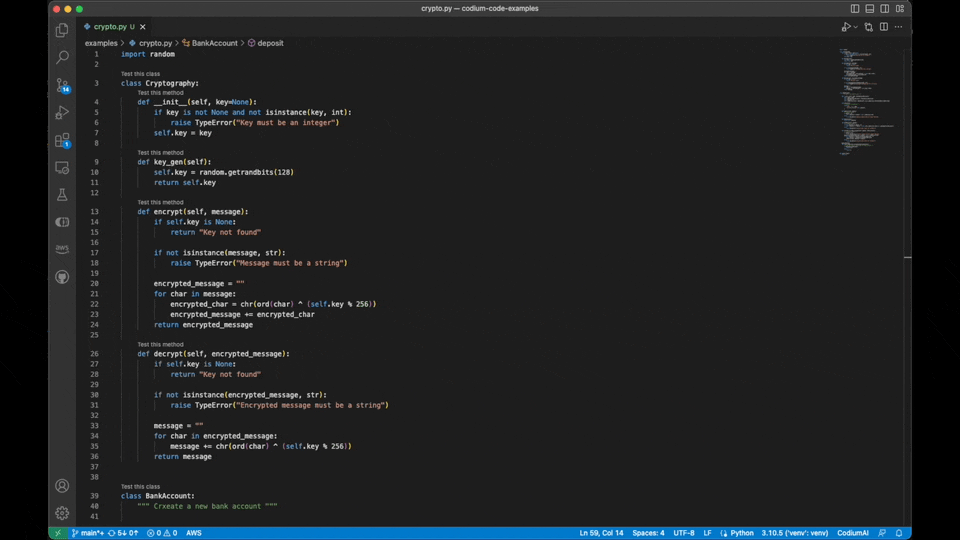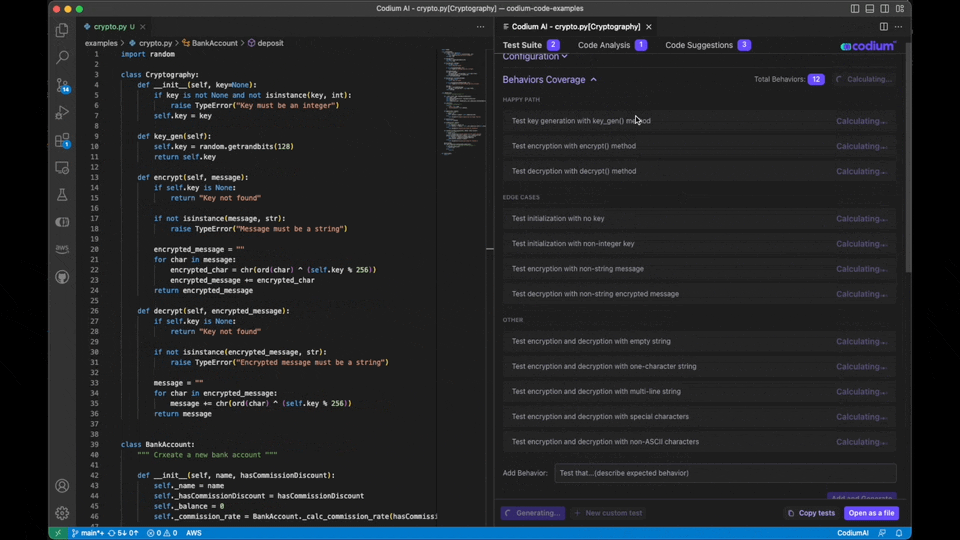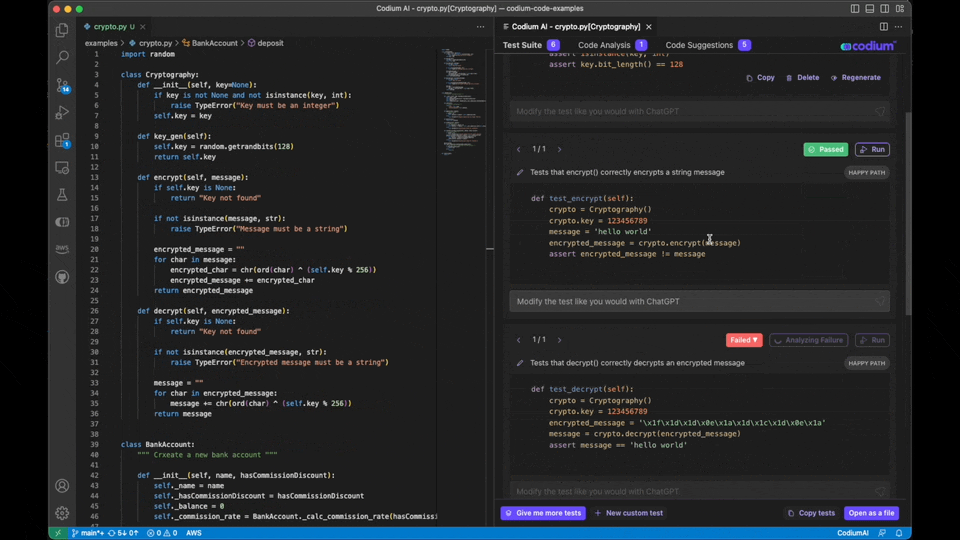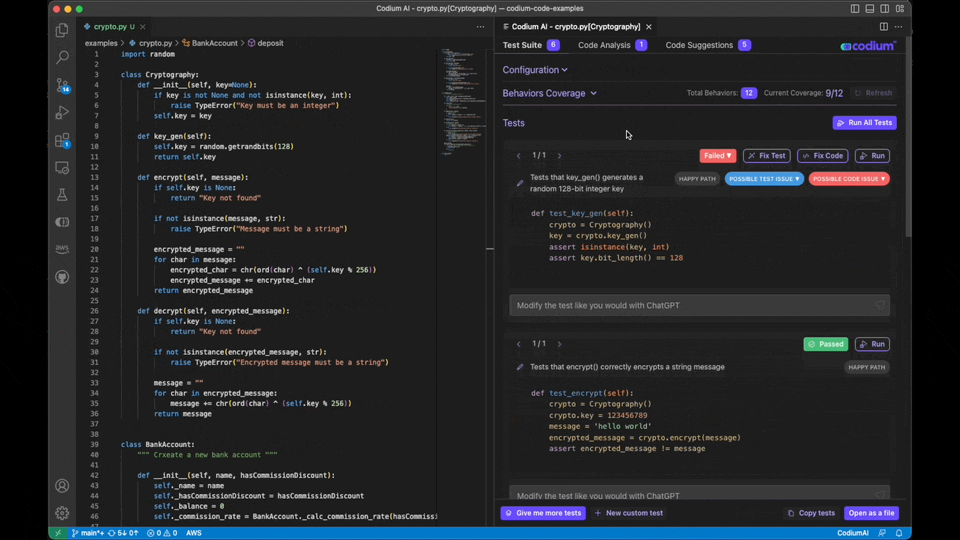
3. AI Test writing – Delegate the task of writing tests to AI- CodiumAI
CodiumAI serves as an AI test-writing assistant. It analyses your code, docstrings, and comments to suggest tests intelligently. CodiumAI addresses a critical aspect of software development that often consumes valuable time: testing. While numerous tools prioritize code writing and optimization, ensuring code functionality is equally vital. CodiumAI seamlessly fills this gap, and its intelligent test generation capability can substantially enhance development efficiency and maintain superior code quality.
4. AI Documentation Assistant — Get AI to write docs for you
This is a no-brainer, who loves writing code walkthroughs and docs? No? Didn’t think so! Mintlify serves as your team’s technical writer. It reads and interprets your code, turning it into a clear, readable document. By all accounts, it is a definite must.
Disclaimer: I have not personally used this and have been mostly able to get this done with Cody, itself. And then, I am no longer doing the primary documentation as my main responsibility.
5. AI Comment Assistant – Readable AI — Never write comments again
Readable AI automates the process of generating comments for your source code. It’s compatible with several popular IDEs, like VSCode, Visual Studio, IntelliJ, and PyCharm, and it can read most languages.
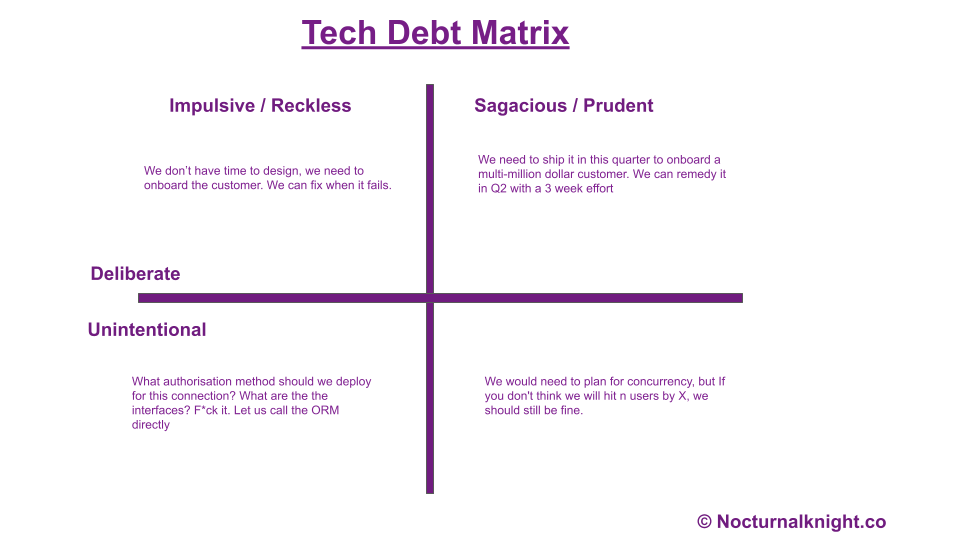
6. AI Tech Debt Assistant – Grit.io
Grit.io is an automated technical debt management tool. Its prime function is auto-generating pull requests that manage code migrations and dependency upgrades. Grit is in beta and available for free till beta moves to RC1. But it actually has about 50+ pattern libraries and it is growing.
I absolutely love it and Grit alleviates a significant portion of the manual work involved in managing migrations and dependency upgrades. They say it 10x’s the refactoring and migration process. I’d say at 33% of what they say, It will still be 300% of what productivity increases. And it is a considerable gain. If you’re an Engineering Leader and you have a “Budget” for 1 tool only, It should be this!
7. AI Pull Request Assistant – An “AI” powered DIff tool
What The Diff AI is an AI-powered code review tool. It writes pull request descriptions, scrutinises pull requests, identifies potential risks, and more. What The Diff claims to be able to significantly speed up development timelines and improve code quality in the long run. It could take a great deal of pain out of the process.
Disclaimer: I have not personally used this
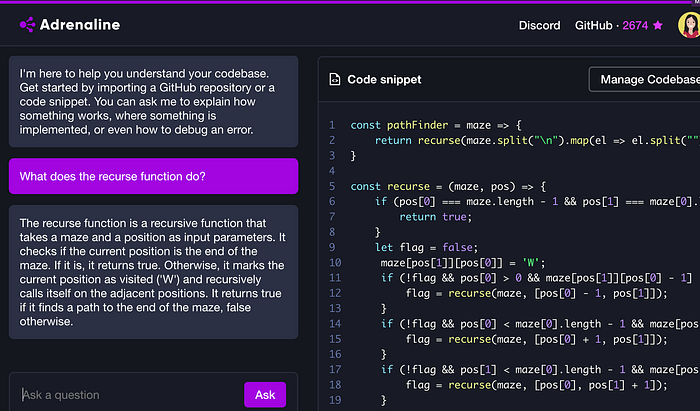
8. AI-driven residential Wizard – Adrenaline AI — Explain it to me
Adrenaline AI helps you understand your codebase. The tool leverages static analysis, vector search, and advanced language models to clarify how features function and explain anything about it to you. The thing I like about this tool very much is, it can be leveraged to automate the “How tos” for your software engineering teams!
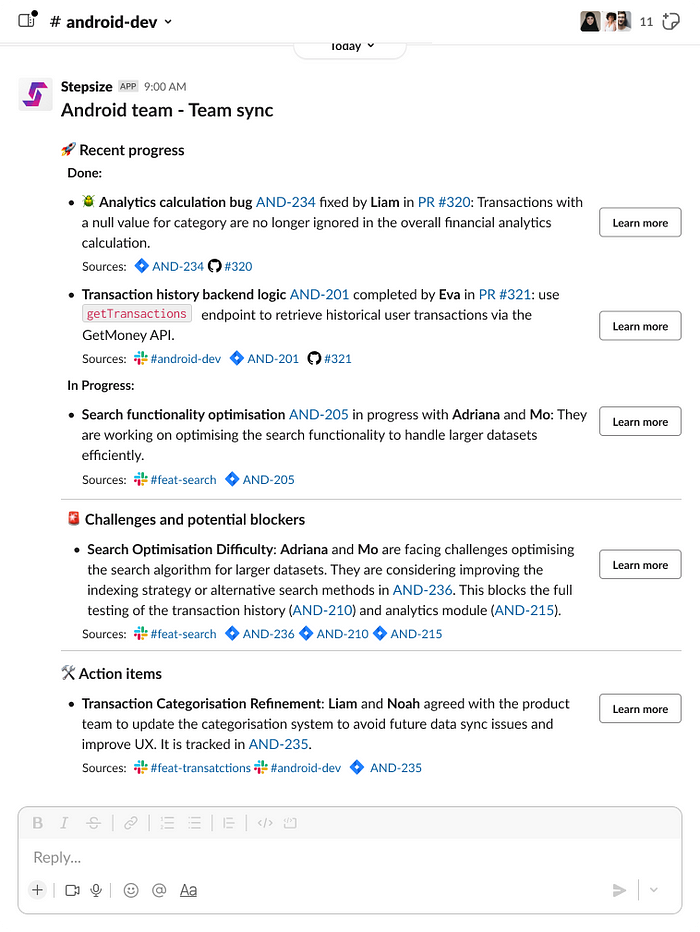
9. AI collaboration companion for software projects
Stepsize AI by Stepsize is an AI companion for software projects. It seamlessly integrates with tools like Slack, Jira, and GitHub, providing insightful overviews of your activities and offering strategic suggestions.
The tool uses a complex AI agent architecture, providing long-term “memory” and a deep understanding of the context of your projects.
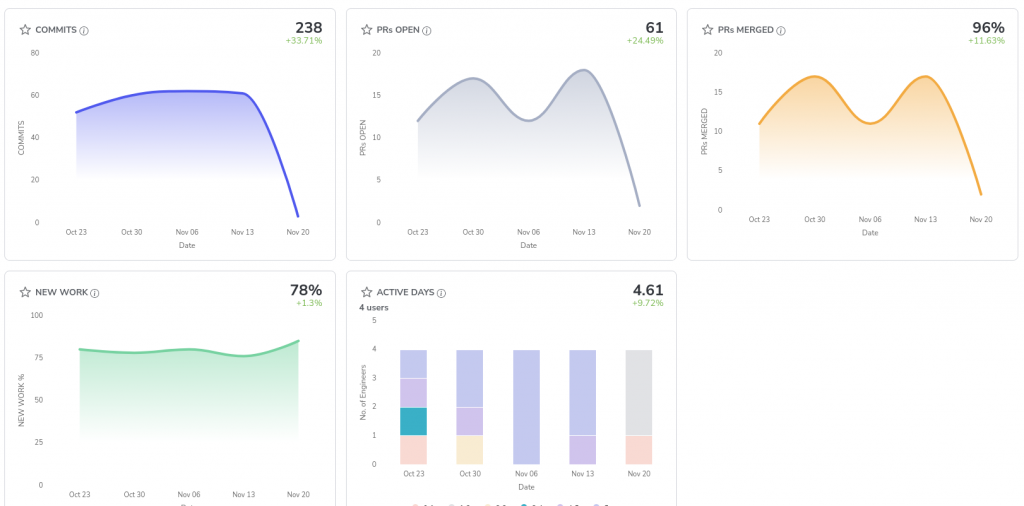
10. AI-Driven Dev Metrics Collection – Hivel.ai
While strictly speaking, not an AI-driven “assistant” to an average developer, I feel it is nevertheless a good tool for the Engineering org and Engineering leaders to keep track and make course corrections. It provides a Cockpit/Dashboard of all the metrics that matter.
Hivel is built by an awesome team of devs and led by Sudheer