Why Startups Need To Architect Cloud Agnostic Products
Nobody plans to leave AWS in the startup world, but as they say, “sh** happens.”

As engineers, when we write software, we’re taught to keep it elegant by never depending directly on external systems. We write wrappers for external resources, we encapsulate data and behaviour and standardise functions with libraries.
But, When it comes to the cloud… “eerie silence”
Companies have died because they needed to move off AWS or GCP but couldn’t do it in a reasonable and cost-effective timeline.
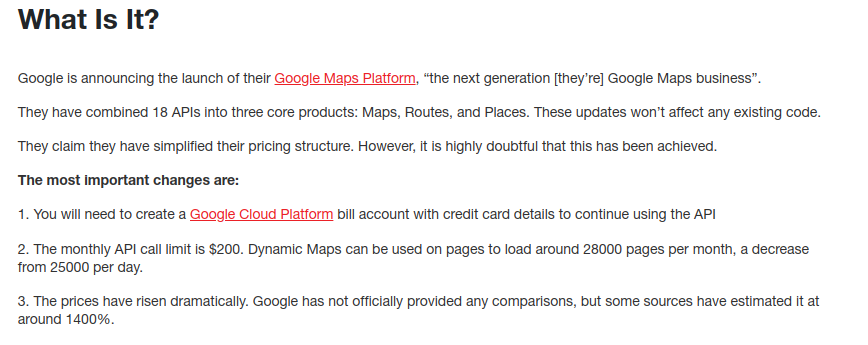
We (at Itilite) had a close call with GCP, which served as our brush with the fire. Google had arguably one of the best Distance Matrix capabilities out there. It was used in one of our core logic and ML models. And on one fine Monday afternoon, I have to set up a meeting with my CEO to communicate that we will have to spend ~250% more on our cloud service bill in about 60 days.
Actually, google increased the pricing by 1400% and gave 60 days to rewrite, migrate, move out or perish!
The closest competitor in terms of capability was DistanceMatrix and a reliable “Large” player was Bing. But, both left a lot for in the “Accuracy”. So, for us, the business decision was simple: make the entire product work in “Reduced Functionality” mode for all or start differential pricing for better accuracy! In either case, those APIs must be rewritten with a new adaptor.
It is not an enigma why we do this. It’s simple: there are no alternatives, there is no time to GTM, But maybe there is. I’ll explain why you should take cloud-agnostic architecture seriously and then show you what I do to keep my projects cloud-agnostic.
Cloud Service Rationalisation
The prime reason you should consider the ability to switch clouds and cloud services is so you can choose to use the cloud service that is price and performance-optimized for your use case.
When I first got into serverless, we wrote a transformative API on Oracle Cloud (Bcoz we were part of their Accelerator Program and had a huge credit.) but it fed part of the data that the customer-facing API relied on.
No prize for guessing what happened?
It was a horrible mistake. Our API had an insane latency problem. Cold start requests added additional latency of at least 2 seconds per request. The AWS team has worked hard to build a service that can do things that GCP’s Cloud Functions simply can’t, specifically around cold starts and latency.
I had to move my infrastructure to a different service and a revised network topology.
Guess we would have learned the problem by now, but as we will find out, we did not.
This time it was a combination of Kafka and the AWS Lambda that created an issue. We had relied on Confluent’s connectors for much of the workload interfaces and had to shell out almost $1000 per month per connector!
Avoiding the Cloud Provider Killswitch
Protect Your Business from Unexpected Termination
As a CXO, you may not be aware that cloud providers like AWS, GCP, and Azure reserve the right to terminate your account and destroy your infrastructure at any time, effectively shutting down your business operations. While this may seem like an extreme measure, it’s important to understand that cloud providers have strict terms of service that can lead to account termination for a variety of reasons, even if you’re not engaged in illegal or harmful activities.
A Chilling Example
I recently spoke with a friend who is the founder of a fintech platform. He shared a chilling incident that highlights the risks of relying on cloud providers. His team was using GCP’s Cloud Run, a container service, to host their API. They had a unique use case that required them to call back to their own API to trigger additional work and keep the service active. Unfortunately, GCP monitors this type of behaviour and flags it as potential crypto-mining activity.
On an ordinary Sunday, their infrastructure vanished, and their account was locked. It took them six days of nonstop effort to migrate to AWS.
Protect Your Business
This incident serves as a stark reminder that any business operating on cloud infrastructure is vulnerable to unexpected termination. While you may not be intentionally engaging in activities that violate cloud provider terms of service, it’s crucial to build your infrastructure with the possibility of termination in mind.
Here are some key steps you can take to protect your business from the cloud provider killswitch:
- Read and understand the terms of service for each cloud provider you use.
- Choose a cloud provider that aligns with your industry and business model.
- Avoid relying on a single cloud provider.
- Have a backup plan in place.
- Regularly review your cloud usage and ensure compliance with cloud provider terms of service.
By taking these proactive measures, you can significantly reduce the risk of your business being disrupted by cloud provider termination and ensure the continuity of your operations.
Unleash the Power of Free Cloud Credits
For early-stage startups operating on a shoestring budget, free cloud credits can be a lifeline, shielding your runway from the scorching heat of cloud infrastructure costs. Acquiring these credits is a breeze, but the way most startups build their infrastructure – akin to an unbreakable blood oath with their cloud provider – restricts them to the credits granted by that single provider.
Why limit yourself to the generosity of one cloud provider when you could seamlessly switch between them to optimize your resource allocation? Imagine the possibilities:
- AWS to GCP: Upon depleting your AWS credits, you could effortlessly migrate your infrastructure to GCP, taking advantage of their generous $200,000 credit offer.
- Y Combinator: As a Y Combinator startup, you’re entitled to a staggering $150,000 in AWS credits and a mind-boggling $200,000 on GCP.
- AI-Powered Startups: If you’re developing AI solutions, Azure welcomes you with open arms, offering $300,000 in free credits to fuel your AI models on their cloud.
By embracing cloud-agnostic architecture, you unlock the freedom to switch between cloud providers, potentially saving you a significant $200,000 upfront. Why constrain yourself to a single cloud provider when cloud-agnosticism empowers you to navigate the cloud landscape with flexibility and cost-efficiency?
Building Resilience: The Importance of Cloud Redundancy
In the ever-evolving world of technology, no system is immune to failure. Even industry giants like Silicon Valley Bank can outright disappear over a weekend or AWS’ main Datacenter can go offline due to a power fluctuation, highlighting the importance of proactively safeguarding your business operations.
Imagine the potential financial impact of a 12-hour outage on AWS for your company. The costs could be staggering, not only in lost revenue but also in reputational damage and customer dissatisfaction or even potential churn.
This is where cloud redundancy comes into play. By running parallel segments of your platform on multiple cloud providers, such as AWS and GCP, you’re essentially creating a fail-safe mechanism.
In the event of an outage on one cloud platform, the other can seamlessly pick up the slack, ensuring uninterrupted service for your customers and minimizing the impact on your business. Cloud redundancy is not just about disaster preparedness; it’s also about optimizing performance and scalability. By distributing your workload across multiple cloud providers, you can tap into the unique strengths and resources of each platform, maximizing efficiency and responsiveness.
In our case, we run the OCR packages, SAML, and Accounts service on Azure, our core “Recommendation engine” and “Booking Engine” on AWS. Yes, having a multi-cloud will involve initial costs that might be prohibitive, but in the long run, the benefits will far outweigh the costs.
Cloud Cost Negotiation: A Matter of Leverage
In the realm of business negotiations, the ultimate power lies in the ability to walk away. If the other party senses your lack of alternatives, they gain a significant advantage, effectively holding you hostage. Cloud cost negotiations are no exception.
Imagine you’ve built a substantial $10 million infrastructure on AWS, heavily reliant on their proprietary APIs like S3, Cognito, and SQS. In such a scenario, walking away from AWS becomes an unrealistic option. You’re essentially at their mercy, accepting whatever cloud costs they dictate.
While negotiating cloud costs may seem insignificant to a small company, for an organization with $10 million of AWS infrastructure, even a 3% discount translates into substantial savings.
To gain leverage in cloud cost negotiations, you need to establish a credible threat of walking away. This requires careful planning and strategic implementation of cloud-agnostic architecture, enabling you to seamlessly switch between cloud providers without disrupting your operations.
Cloud Agnosticism: Your Negotiating Edge
Cloud-agnostic architecture empowers you to:
- Diversify your infrastructure: Run your applications on multiple cloud platforms, reducing reliance on a single provider.
- Reduce switching costs: Design your infrastructure to minimize the effort and cost of migrating to a new cloud provider.
- Strengthen your negotiating position: Demonstrate to cloud providers that you have alternative options, giving you more bargaining power.
By embracing cloud-agnosticism, you transform from a captive customer to a savvy negotiator, capable of securing favorable cloud cost terms.
Unforeseen Challenges: The Importance of Cloud Agnosticism
In the dynamic world of business, unforeseen challenges (and opportunities) can arise at any moment. We often operate with limited visibility, unable to predict every possible scenario that could impact our success. Here’s an actual scenario that highlights the importance of cloud-agnostic architecture:
Acquisition Deal Goes Through
This happened with One of my previous organisations, we tirelessly built this company from the ground up. Our hard work and dedication paid off when a large SaaS Unicorn approached us with an acquisition proposal.
However, during the due diligence, a critical issue emerged: Our company’s infrastructure was entirely reliant on AWS. The Acquiring company had a multi-year multi-million dollar deal with Azure and the M&A team made it clear that unless our platform can operate on Azure, the deal is off the table!
Our team faced the daunting task of migrating the entire infrastructure to Azure within a limited timeframe and budget. Unfortunately, the complexities of the migration proved time-consuming and the merger took 5 months to complete and the offer was reduced by $2 million!
The Power of Cloud Agnosticism
This story serves as a stark reminder of the risks associated with a single-cloud strategy. Had our company embraced cloud-agnostic architecture, we would have possessed the flexibility to seamlessly switch between cloud providers, potentially leading to a bigger exit for all of us!
Cloud-agnostic architecture offers several benefits:
- Reduced Vendor Lock-in: Avoids dependence on a single cloud provider, empowering you to switch to more favourable options based on your needs.
- Improved Negotiation Power: Gains leverage in cloud cost negotiations by demonstrating the ability to switch providers.
- Increased Resilience: Protects your business from disruptions caused by cloud provider outages or policy changes.
- Enhanced Scalability: Enables seamless expansion of your infrastructure across multiple cloud platforms as your business grows.
Embrace Cloud Agnosticism for Business Continuity
In today’s ever-changing technological landscape, cloud-agnostic architecture is not just a benefit; it’s a necessity for businesses seeking long-term success and resilience. By adopting a cloud-agnostic approach, you empower your company to navigate the complexities of the cloud landscape with agility, adaptability, and cost-efficiency, ensuring that unforeseen challenges don’t derail your journey.
My Solution
Here’s what I do about it, now after the lessons learnt. I use Multy. Multy is an open-source tool that simplifies cloud infrastructure management by providing a cloud-agnostic API. This means that developers can define their infrastructure configurations once and deploy them to any cloud provider without having to worry about the specific syntax or nuances of each cloud platform. While Multy provides an abstraction layer for deploying cross-cloud environments, you will also need to incorporate cloud-environment agnostic libraries to really make a difference.