The cybersecurity landscape is a relentless battlefield. Attackers are constantly innovating, churning out new threats at an alarming rate. Traditional security solutions are struggling to keep pace. But fear not, weary defenders! Artificial Intelligence (AI) and Machine Learning (ML) are emerging as powerful weapons in our arsenal, offering the potential to revolutionize cybersecurity.
The Numbers Don’t Lie: Why AI/ML Matters
Security Incidents on the Rise: According to the IBM Security X-Force Threat Intelligence Index 2023 https://www.ibm.com/reports/threat-intelligence, the average organization experienced 270 data breaches in 2022, a staggering 13% increase from the previous year.
Alert Fatigue is Real: Security analysts are bombarded with a constant stream of alerts, often leading to “alert fatigue” and missed critical threats. A study by the Ponemon Institute found that it takes an average of 280 days to identify and contain a security breach https://www.ponemon.org/.
AI/ML to the Rescue: Current Applications
AI and ML are already making a significant impact on cybersecurity:
Reverse Engineering Malware with Speed: AI can disassemble and analyze malicious code at lightning speed, uncovering its functionalities and vulnerabilities much faster than traditional methods. This allows defenders to understand attacker tactics and develop effective countermeasures before widespread damage occurs.
Prioritizing the Vulnerability Avalanche: Legacy vulnerability scanners often generate overwhelming lists of potential weaknesses. AI can prioritize these vulnerabilities based on exploitability and potential impact, allowing security teams to focus their efforts on the most critical issues first. A study by McAfee found that organizations can reduce the time to patch critical vulnerabilities by up to 70% using AI https://www.mcafee.com/blogs/internet-security/the-what-why-and-how-of-ai-and-threat-detection/.
Security SIEMs Get Smarter: Security Information and Event Management (SIEM) systems ingest vast amounts of security data. AI can analyze this data in real-time, correlating events and identifying potential threats with an accuracy far exceeding human capabilities. This significantly improves threat detection accuracy and reduces the time attackers have to operate undetected within a network.
The Future of AI/ML in Cybersecurity: A Glimpse Beyond
As AI and ML technologies mature, we can expect even more transformative applications:
Context is King: AI can be trained to understand the context of security events, considering user behaviour, network activity, and system configurations. This will enable highly sophisticated threat detection and prevention capabilities, automatically adapting to new situations and attacker tactics.
Automating Security Tasks: Imagine a future where AI automates not just vulnerability scanning, but also incident response, patch management, and even threat hunting. This would free up security teams to focus on more strategic initiatives and significantly improve overall security posture.
Challenges and Considerations: No Silver Bullet
While AI/ML offers immense potential, it’s important to acknowledge the challenges:
Explainability and Transparency: AI models can sometimes make decisions that are difficult for humans to understand. This lack of explainability can make it challenging to trust and audit AI-powered security systems. Security teams need to ensure they understand how AI systems reach conclusions and that these conclusions are aligned with overall security goals.
Data Quality and Bias: The effectiveness of AI/ML models heavily relies on the quality of the data they are trained on. Biased data can lead to biased models that might miss certain threats or flag legitimate activity as malicious. Security teams need to ensure their training data is diverse and unbiased to avoid perpetuating security blind spots.
The Takeaway: Embrace the Future
Security practitioners and engineers are at the forefront of adopting and shaping AI/ML solutions. By understanding the current applications, future potential, and the associated challenges, you can ensure that AI becomes a powerful ally in your cybersecurity arsenal. Embrace AI/ML, and together we can build a more secure future!
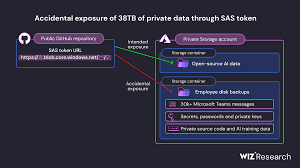
Note: I started this article last weekend to try and explain the attack path “Midnight Blizzard” used and what Azure admins should do to protect themselves from a similar attack. Unfortunately, I couldn't complete/publish it in time and now there is another breach at Microsoft. (🤦🏿) Now, I had to completely redraft it and change the focus to a summary of data breaches at Microsoft and a walkthrough on the current breach. I will publish the Midnight Blizzard defence later this week.
The Timeline of the Breaches
20th-25th September 2023: 60k State Department Emails Stolen in Microsoft Breach
12th-25th January 2024: Microsoft breached by “Nation-State Actors”
11th-14th February 2024: State-backed APTs are weaponising OpenAI models
16th-19th February 2024: Microsoft admits to security issues with Azure and Exchange servers.
Date/Month
Breach Type
Affected Service/Area
Source
February 2024
Zero-day vulnerabilities in Exchange servers
Exchange servers
Microsoft Security Response Center blog
January 2024
Nation State-sponsored attack (Russia)
Email accounts
Microsoft Security Response Center blog
February 2024
State-backed APTs are weaponising OpenAI models
Not directly impacting MS services
July 2023
Chinese Hackers Breach U.S. Agencies Via Microsoft Cloud
Azure
The New York Times, Microsoft Security Response Center blog
October 2022
BlueBleed Data Leak, 0.5 Million user data leaked
User Data
December 2021
Lapsus$ intrusion
Source code (Bing, Cortana)
The Guardian, Reuters
August 2021
Hafnium attacks Exchange servers
Exchange servers
Microsoft Security Response Center blog
March 2021
SolarWinds supply chain attack
Various Microsoft products (indirectly affected)
The New York Times, Reuters
January 2020
Misconfigured customer support database
Customer data (names, email addresses)
ZDNet
This is a high-level summary of breaches and successful hacks that got reported in the public domain and picked up by tier 1 publications. There are at least a dozen more in the period, some are of negligible impact, and others are less probable
Introduction:
Today, The digital landscape is a battlefield, and even tech giants like Microsoft aren’t immune to cyberattacks. Understanding recent breaches/incidents and their root causes, and effective defence strategies is crucial for Infosec/IT and DevSecOp teams navigating this ever-evolving threat landscape. This blog post dives into the security incidents affecting Microsoft, analyzes potential attack paths, and equips you with actionable defence plans to fortify your infrastructure/network.
Selected Breaches:
January 2024: State actors, purported to be affiliated with Russia leveraged password spraying and compromised email accounts, including those of senior leadership. This highlights the vulnerability of weak passwords and the critical need for multi-factor authentication (MFA).
January 2024:Zero-day vulnerabilities in Exchange servers allowed attackers to escalate privileges. This emphasizes the importance of regular patching and prompt updates to address vulnerabilities before they’re exploited.
December 2021: Lapsus$ group gained access to source code due to misconfigured access controls. This underscores the importance of least-privilege access and regularly reviewed security configurations.
Other incidents:Supply chain attacks (SolarWinds, March 2021) and data leaks (customer database, January 2020) demonstrate the diverse threats organizations face.
Attack Paths:
Understanding attacker motivations and methods is key to building effective defences. Here are common attack paths:
Social Engineering: Phishing emails and deceptive tactics trick users into revealing sensitive information or clicking malicious links.
Software Vulnerabilities: Unpatched software with known vulnerabilities offers attackers an easy entry point.
Weak Passwords: Simple passwords are easily cracked, granting access to accounts and systems.
Misconfigured Access Controls: Overly permissive access rules give attackers more power than necessary to escalate privileges and cause damage.
Supply Chain Attacks: Compromising a vendor or partner can grant attackers access to multiple organizations within the supply chain.
Defence Plans:
Building a robust defense requires a multi-layered approach:
Patch Management: Prioritize timely patching of vulnerabilities across all systems and software.
Strong Passwords & MFA: Implement strong password policies and enforce MFA for all accounts.
Access Control Management: Implement least privilege access and regularly review configurations.
Security Awareness Training: Educate employees on phishing, social engineering, and secure password practices.
Threat Detection & Response: Deploy security tools to monitor systems for suspicious activity and respond promptly to incidents.
Incident Response Planning: Develop and test a plan to mitigate damage, contain breaches, and recover quickly.
Penetration Testing: Regularly test your defenses by simulating real-world attacks to identify and fix vulnerabilities before attackers do.
Network Segmentation: Segment your network to limit the potential impact of a breach by restricting access to critical systems.
Data Backups & Disaster Recovery: Regularly back up data and have a plan to restore it in case of an attack or outage.
Stay Informed: Keep up-to-date on the latest security threats and vulnerabilities by subscribing to security advisories and attending industry conferences.
Conclusion:
Cybersecurity is an ongoing battle, but by understanding the tactics employed by attackers and implementing these defence strategies, IT/DevOps admins can significantly reduce the risk of breaches and protect their networks and data. Remember, vigilance and continuous improvement are key to staying ahead of the curve in the ever-evolving cybersecurity landscape.
Disclaimer: This blog post is for informational purposes only and should not be considered professional security advice. Please consult with a qualified security professional for guidance specific to your organization or mail me for an obligation free consultation call.
Nobody plans to leave AWS in the startup world, but as they say, “sh** happens.”
As engineers, when we write software, we’re taught to keep it elegant by never depending directly on external systems. We write wrappers for external resources, we encapsulate data and behaviour and standardise functions with libraries.
But, When it comes to the cloud… “eerie silence”
Companies have died because they needed to move off AWS or GCP but couldn’t do it in a reasonable and cost-effective timeline.
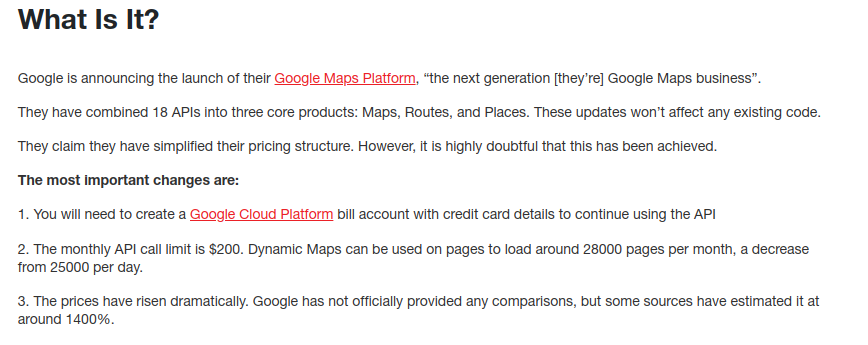
We (at Itilite) had a close call with GCP, which served as our brush with the fire. Google had arguably one of the best Distance Matrix capabilities out there. It was used in one of our core logic and ML models. And on one fine Monday afternoon, I have to set up a meeting with my CEO to communicate that we will have to spend ~250% more on our cloud service bill in about 60 days.
Actually, google increased the pricing by 1400% and gave 60 days to rewrite, migrate, move out or perish!
The closest competitor in terms of capability was DistanceMatrix and a reliable “Large” player was Bing. But, both left a lot for in the “Accuracy”. So, for us, the business decision was simple: make the entire product work in “Reduced Functionality” mode for all or start differential pricing for better accuracy! In either case, those APIs must be rewritten with a new adaptor.
It is not an enigma why we do this. It’s simple: there are no alternatives, there is no time to GTM, But maybe there is. I’ll explain why you should take cloud-agnostic architecture seriously and then show you what I do to keep my projects cloud-agnostic.
Cloud Service Rationalisation
The prime reason you should consider the ability to switch clouds and cloud services is so you can choose to use the cloud service that is price and performance-optimized for your use case.
When I first got into serverless, we wrote a transformative API on Oracle Cloud (Bcoz we were part of their Accelerator Program and had a huge credit.) but it fed part of the data that the customer-facing API relied on.
No prize for guessing what happened?
It was a horrible mistake. Our API had an insane latency problem. Cold start requests added additional latency of at least 2 seconds per request. The AWS team has worked hard to build a service that can do things that GCP’s Cloud Functions simply can’t, specifically around cold starts and latency.
I had to move my infrastructure to a different service and a revised network topology.
Guess we would have learned the problem by now, but as we will find out, we did not.
This time it was a combination of Kafka and the AWS Lambda that created an issue. We had relied on Confluent’s connectors for much of the workload interfaces and had to shell out almost $1000 per month per connector!
Avoiding the Cloud Provider Killswitch
Protect Your Business from Unexpected Termination
As a CXO, you may not be aware that cloud providers like AWS, GCP, and Azure reserve the right to terminate your account and destroy your infrastructure at any time, effectively shutting down your business operations. While this may seem like an extreme measure, it’s important to understand that cloud providers have strict terms of service that can lead to account termination for a variety of reasons, even if you’re not engaged in illegal or harmful activities.
A Chilling Example
I recently spoke with a friend who is the founder of a fintech platform. He shared a chilling incident that highlights the risks of relying on cloud providers. His team was using GCP’s Cloud Run, a container service, to host their API. They had a unique use case that required them to call back to their own API to trigger additional work and keep the service active. Unfortunately, GCP monitors this type of behaviour and flags it as potential crypto-mining activity.
On an ordinary Sunday, their infrastructure vanished, and their account was locked. It took them six days of nonstop effort to migrate to AWS.
Protect Your Business
This incident serves as a stark reminder that any business operating on cloud infrastructure is vulnerable to unexpected termination. While you may not be intentionally engaging in activities that violate cloud provider terms of service, it’s crucial to build your infrastructure with the possibility of termination in mind.
Here are some key steps you can take to protect your business from the cloud provider killswitch:
Read and understand the terms of service for each cloud provider you use.
Choose a cloud provider that aligns with your industry and business model.
Avoid relying on a single cloud provider.
Have a backup plan in place.
Regularly review your cloud usage and ensure compliance with cloud provider terms of service.
By taking these proactive measures, you can significantly reduce the risk of your business being disrupted by cloud provider termination and ensure the continuity of your operations.
Unleash the Power of Free Cloud Credits
For early-stage startups operating on a shoestring budget, free cloud credits can be a lifeline, shielding your runway from the scorching heat of cloud infrastructure costs. Acquiring these credits is a breeze, but the way most startups build their infrastructure – akin to an unbreakable blood oath with their cloud provider – restricts them to the credits granted by that single provider.
Why limit yourself to the generosity of one cloud provider when you could seamlessly switch between them to optimize your resource allocation? Imagine the possibilities:
AWS to GCP: Upon depleting your AWS credits, you could effortlessly migrate your infrastructure to GCP, taking advantage of their generous $200,000 credit offer.
Y Combinator: As a Y Combinator startup, you’re entitled to a staggering $150,000 in AWS credits and a mind-boggling $200,000 on GCP.
AI-Powered Startups: If you’re developing AI solutions, Azure welcomes you with open arms, offering $300,000 in free credits to fuel your AI models on their cloud.
By embracing cloud-agnostic architecture, you unlock the freedom to switch between cloud providers, potentially saving you a significant $200,000 upfront. Why constrain yourself to a single cloud provider when cloud-agnosticism empowers you to navigate the cloud landscape with flexibility and cost-efficiency?
Building Resilience: The Importance of Cloud Redundancy
In the ever-evolving world of technology, no system is immune to failure. Even industry giants like Silicon Valley Bank can outright disappear over a weekend or AWS’ main Datacenter can go offline due to a power fluctuation, highlighting the importance of proactively safeguarding your business operations.
Imagine the potential financial impact of a 12-hour outage on AWS for your company. The costs could be staggering, not only in lost revenue but also in reputational damage and customer dissatisfaction or even potential churn.
This is where cloud redundancy comes into play. By running parallel segments of your platform on multiple cloud providers, such as AWS and GCP, you’re essentially creating a fail-safe mechanism.
In the event of an outage on one cloud platform, the other can seamlessly pick up the slack, ensuring uninterrupted service for your customers and minimizing the impact on your business. Cloud redundancy is not just about disaster preparedness; it’s also about optimizing performance and scalability. By distributing your workload across multiple cloud providers, you can tap into the unique strengths and resources of each platform, maximizing efficiency and responsiveness.
In our case, we run the OCR packages, SAML, and Accounts service on Azure, our core “Recommendation engine” and “Booking Engine” on AWS. Yes, having a multi-cloud will involve initial costs that might be prohibitive, but in the long run, the benefits will far outweigh the costs.
Cloud Cost Negotiation: A Matter of Leverage
In the realm of business negotiations, the ultimate power lies in the ability to walk away. If the other party senses your lack of alternatives, they gain a significant advantage, effectively holding you hostage. Cloud cost negotiations are no exception.
Imagine you’ve built a substantial $10 million infrastructure on AWS, heavily reliant on their proprietary APIs like S3, Cognito, and SQS. In such a scenario, walking away from AWS becomes an unrealistic option. You’re essentially at their mercy, accepting whatever cloud costs they dictate.
While negotiating cloud costs may seem insignificant to a small company, for an organization with $10 million of AWS infrastructure, even a 3% discount translates into substantial savings.
To gain leverage in cloud cost negotiations, you need to establish a credible threat of walking away. This requires careful planning and strategic implementation of cloud-agnostic architecture, enabling you to seamlessly switch between cloud providers without disrupting your operations.
Cloud Agnosticism: Your Negotiating Edge
Cloud-agnostic architecture empowers you to:
Diversify your infrastructure: Run your applications on multiple cloud platforms, reducing reliance on a single provider.
Reduce switching costs: Design your infrastructure to minimize the effort and cost of migrating to a new cloud provider.
Strengthen your negotiating position: Demonstrate to cloud providers that you have alternative options, giving you more bargaining power.
By embracing cloud-agnosticism, you transform from a captive customer to a savvy negotiator, capable of securing favorable cloud cost terms.
Unforeseen Challenges: The Importance of Cloud Agnosticism
In the dynamic world of business, unforeseen challenges (and opportunities) can arise at any moment. We often operate with limited visibility, unable to predict every possible scenario that could impact our success. Here’s an actual scenario that highlights the importance of cloud-agnostic architecture:
Acquisition Deal Goes Through
This happened with One of my previous organisations, we tirelessly built this company from the ground up. Our hard work and dedication paid off when a large SaaS Unicorn approached us with an acquisition proposal.
However, during the due diligence, a critical issue emerged: Our company’s infrastructure was entirely reliant on AWS. The Acquiring company had a multi-year multi-million dollar deal with Azure and the M&A team made it clear that unless our platform can operate on Azure, the deal is off the table!
Our team faced the daunting task of migrating the entire infrastructure to Azure within a limited timeframe and budget. Unfortunately, the complexities of the migration proved time-consuming and the merger took 5 months to complete and the offer was reduced by $2 million!
The Power of Cloud Agnosticism
This story serves as a stark reminder of the risks associated with a single-cloud strategy. Had our company embraced cloud-agnostic architecture, we would have possessed the flexibility to seamlessly switch between cloud providers, potentially leading to a bigger exit for all of us!
Cloud-agnostic architecture offers several benefits:
Reduced Vendor Lock-in: Avoids dependence on a single cloud provider, empowering you to switch to more favourable options based on your needs.
Improved Negotiation Power: Gains leverage in cloud cost negotiations by demonstrating the ability to switch providers.
Increased Resilience: Protects your business from disruptions caused by cloud provider outages or policy changes.
Enhanced Scalability: Enables seamless expansion of your infrastructure across multiple cloud platforms as your business grows.
Embrace Cloud Agnosticism for Business Continuity
In today’s ever-changing technological landscape, cloud-agnostic architecture is not just a benefit; it’s a necessity for businesses seeking long-term success and resilience. By adopting a cloud-agnostic approach, you empower your company to navigate the complexities of the cloud landscape with agility, adaptability, and cost-efficiency, ensuring that unforeseen challenges don’t derail your journey.
My Solution
Here’s what I do about it, now after the lessons learnt. I use Multy. Multy is an open-source tool that simplifies cloud infrastructure management by providing a cloud-agnostic API. This means that developers can define their infrastructure configurations once and deploy them to any cloud provider without having to worry about the specific syntax or nuances of each cloud platform. While Multy provides an abstraction layer for deploying cross-cloud environments, you will also need to incorporate cloud-environment agnostic libraries to really make a difference.
In this article, I will summarise effective strategies and best practices to tackle tech debt head-on.
Technical debt is an inevitable reality in software development. But, it can be leveraged just like a financial loan/debt can help you achieve your goals, if managed properly. It can be used to drive competitive advantage by allowing companies to launch new products and features faster, experiment with new technologies, and improve the scalability and performance of their systems. However, like all loans, it need to be “Repaid” properly and at the right time, failing on it will create a downward spiral.
If you’re not careful, technical debt can quickly become a major burden that slows down development and makes it difficult to add new features or even fix bugs in a timely manner.
We will discuss how to identify technical debt and the signs of poorly managed debt, and then provide a strategy for reducing it. We will also discuss what a healthy level of technical debt looks like and how leaders can use it to their advantage.
Bad debt takes money out of your pocket, while good debt puts money in your pocket.
– Robert Kiyosaki
The same is true of tech debt.
Technical debt is the cost of not doing things the right way the first time. Good technical debt is accrued when you make trade-offs to meet deadlines or deliver new features quickly.Bad technical debt is accrued when you make poor decisions or cut corners.
Bad tech debt will probably make your PMs, Sales and CEO happy for a quarter or two. But after that, they will be asking why everything is behind schedule and dealing with customer complaints because things aren’t working properly.
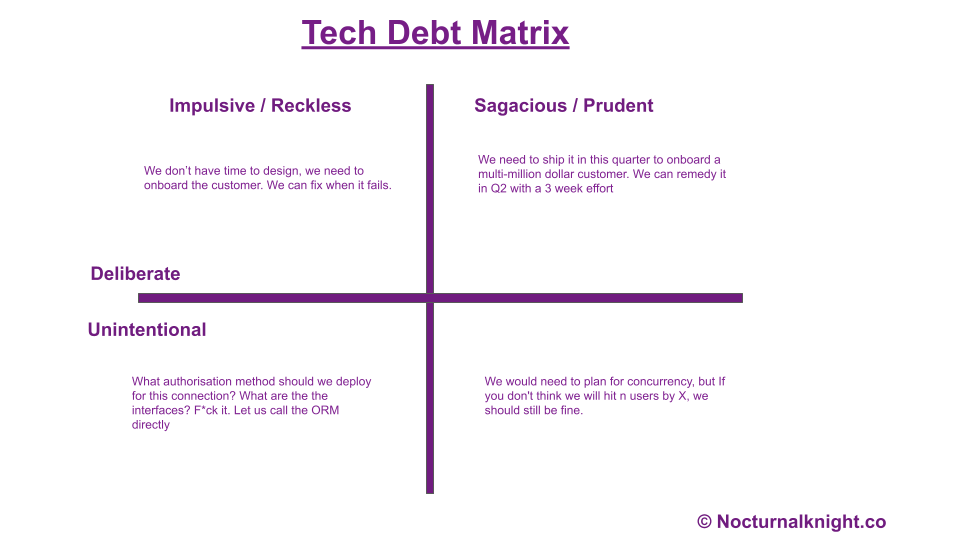
Now that I have presented the obvious in a familiar “Quadrant”, you can actually skip the terminologies and definitions part of this article! 😀
For my verbal brethren, Which is the Tech Debt you’d need to ruthlessly hunt down to extinction? Obviously, it is the untracked, undocumented ones. And the ones which are dragging your team on a downward spiral (immaterial of whether it is tracked or not)
Why does your Tech Debt keep accumulating?
Before we can think about building a strategy to solve tech debt, we need to understand how it gets out of control in the first place.
It’s called “impact visibility”.
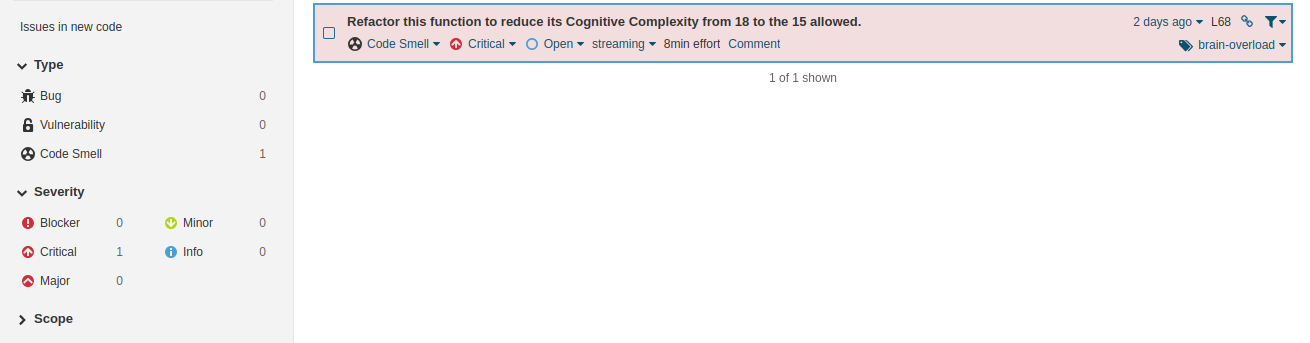
Fixing code debt issues is impossible if:
1, You’ve no record of what technical debt issues you have
2, You’ve got a backlog, but you can’t see which issues are related to what code
In both cases, you can’t prioritise tech debt over shipping new features.
We need to get more granular about what impacts these two tech debt cases above.
Issue invisibility — There’s no source of shared knowledge. Codebase health info is locked in (few) engineers’ heads.
No code quality culture — Shipping fast, whatever the cost, like it’s going out of fashion.
Poor process — Tech debt work sucks. Nobody likes creating Jira tickets. “Jira” has become a dirty word.
Low-time investment — Justifying the time to fix tech debt or to refactor is a constant uphill battle. After a point, engineers become silent!
Lack of context — Issues in Jira are a world away from the hard reality of the codebase. They’re not related in any way.
So what’s the source of this? Let’s talk strategy.
Spoiler… It’s about changing organisational culture and developer behaviour to track issues properly.
Creating a strategy to reduce technical debt
Track. Issues. Properly.
Good tech debt management starts with team-wide excellence at tracking issues.
You can’t have a tech debt strategy without tracking.
The engineering leader’s job is to make that “issue tracking” easy for your team. There is supposed to be a software for that – Jira, Asana, Rally or something of that sort.
The problem is, I’ve never believed they really get to the bottom of the problem, and after speaking with scores of engineers and leaders about it, they usually don’t either. My personal belief is most companies suffer on the velocity after their Jira rollout! It is a bit like,
No two countries that both have a McDonald’s have ever fought a war against each other.
Show engineers when they’re working on code with tech debt, without them having to jump thru 3 hoops.
Make it really easy for team members to report tech debt.
Create a natural way to discuss codebase issues.
Integrate tech debt work into your workflows and involve PMs if required.
There are multiple ways to achieve this, the easiest is to not address it. Ie: not address it intentionally, just tweak your existing pipeline. This can be done by,
A very robust linting & integration to the IDE
Tighter Git rules for commits
SAST which runs on the pipeline
and can feed into the IDE
Prioritising impactful tech debt
At this point, it should be obvious, but prioritising the right issues is only possible if you’re tracking the impact of these “issues” and it could be direct or indirect (Dependency, Sequencing, Rework avoidance etc) .
Once you’ve got them, you should regularly and consistently use them to decide what to address. This usually happens during the backlog grooming or sprint planning sessions. But, this decision-making process needs to be strategic. Not at all tactical, ie: DO NOT delegate it to the whims and whimsicals of your TL/PM or even EM.
You or someone with a context of the organisation and position on sales, clients, revenue etc., should be doing this.
A good way to start is by choosing a theme each time you prioritise issues. For example, you could prioritise issues that…
Are impacting a specific feature you need to work on in the next quarter
Are impacting the customer’s UX
Are affecting efficiency/morale on the team
Are impacting the security posture
This is often straightforward if you’ve got high-quality issues that traceable to code and tagged as such.
Most people wonder how to get the time for these “Tasks”. I have two recommendations.
Take an entire sprint every quarter to repay the tech debt (Will need high-level buy-in, It is slightly harder to align your CXOs)
Allocate 15-20% of bandwidth in every sprint. (Easier to achieve buy-in from CXOs, harder to drive with engineers)
Engineers generally won’t prioritise tech debt work by themselves because of the conflict of interest/pressure of shipping fast. This was evident from multiple high velocity/impact software engineering teams including ones at AirBnb, Netflix and Spotify. A commitment to code refactoring and maintenance work should be endorsed and supported from the top and reinforced regularly.
How much Tech Debt can you take on?
Managing technical debt is like managing financial debt. You can use it to your advantage, but you need to be careful not to let it get out of control.
Your technical debt budget is the amount of technical debt that you are willing to take on in order to achieve your business goals. You should not try to solve all of your technical debt at once, but instead focus on the most important items.
Prudent technical debt is debt that you take on deliberately and knowingly, in order to achieve a specific goal. For example, you might take on technical debt to launch a new product quickly, or to add a new feature that is in high demand by your customers.
If you manage your technical debt properly, it can be a powerful tool for gaining a competitive advantage. However, if you let your technical debt get out of control, it can lead to serious problems, such as increased costs, delays, and security vulnerabilities.
Concluding remarks:
Technical debt is one of the most neglected areas of software development. It is often only given priority when it is too late and has already caused serious problems.
However, when leaders work together and develop a consistent and process-driven strategy, technical debt can be effectively managed.
The best engineering teams are constantly thinking about how to use their technical debt budget to their advantage.
Disclaimer: I have been an enormous proponent of Developer Productivity and have tried to implement automated metrics collection in 3 orgs with varied success. In my Mentoring sessions with early-stage startup leaders as well, I (re)enforce the importance of being aware of Dev Productivity. So much so, that I have written a 2-part article on the same here, here and here. I have also been a huge fan of McKinsey and how they seem to get answers which eluded the attention and resources of mega-corporations or governments alike. However, this article is written to communicate an entirely different perspective. In my opinion, McKinsey has got this entire “framework” thing about “dev productivity” wrong.
Introduction:
About a month back, McKinsey published an article claiming that they have developed a framework to measure productivity. They also acknowledged the fact that they were simply rehashing some of the existing metrics (like DORA and SPACE), which were used by Engineering Leaders and have simplified it (without the context) and are pitching it to their traditional buyers, the C-Suite executives in Mega corporations. Actually, some of these metrics can be useful tools if used correctly -One example is Hand-offs. But, the main reason I have chosen to write this article is their central focus seems to be “Coders should code”. It also appears to have A) missed the context of every metric, OR B) Omitted the context so as not to burden their target audience.
Finally, there is a mix-max of things to track, metrics to monitor and Opportunities to Focus, which looks like
Captain Ramius Pointing to a young Jack Ryan that Admiral Halsey was Stupid!
The Legendary Kent Beck has written a deep 2-part piece on countering the conjectures presented by McKinsey and elaborating on the gaps that engineering orgs are traditionally bound to manifest. It is very well written and covers almost everything. There are also a bunch of other eminent Software Engineers who have written on this and I have tried to give a quick lot at the bottom of this article.
What Was I concerned about?
Focus On Activities
I was primarily concerned about the lack of focus on Outcomes and Impact and a focus on the “Activities” in the proposed framework!
Any engineering leader or manager will tell you that Code Review Velocity and Deployment Frequency have nothing to do with measuring outcomes. While I will not discount Cycle Time or MTTR (I take pride in building multiple teams with one of the lowest MTTR and Cycle times in the ecosystem). They are indicators of some process elements/activities that could lead to outcomes. If we want to measure something, it should be Outcomes, not activities!
Focus on Optimisation of Irrelevant Metrics
Code Review Velocity:
If you want to time-motion the code review process in the entire stream map, you’ll find that async code review is killing your productivity. Pairing improves that dramatically. Instead of trying to sub-optimize for code review, measure the thing we actually want to improve. Which will be “Cycel Time”.
Story Points Completed:
Let’s agree on a basic fact. A “story point” is a made-up number. It was conceived as yet another way to obfuscate estimates for thought work that is difficult to estimate. As originally conceived, it represented the number of mythical “ideal days” of effort. There’s so much time wasted on getting better at “story pointing,” arguing about the Fibonacci sequence, “planning poker,” and other story point nonsense. Frankly, it is one of the “Bad” elements of Scrum! As a leader, you should find and remove handoffs and wait times. Story points are useless for anything and even more useless for this goal. Track throughput instead.
Handoffs:
This is a good one. Good job, McKinsey. You got something right. Stop using testing teams, use pairing instead of code review, operate what you build, and don’t have any people doing anything manual to the right of development.
Contribution Analysis and Opportunities focus
In the other focus areas, they have listed metrics at the individual level that can be useful unless you measure “developer satisfaction,” “retention,” and “interruptions” at the individual level. These should only be measured in aggregates to prevent any cognitive bias. IMO, Things start getting really toxic in the “Opportunities focus” section, though.
I have been part of organisations and processes where there was a focus on tracking and measuring the outcomes of individuals. It did not play out well, ever. My Conclusion after reading the article for the second time is that McKinsey thinks their intended audience (CEOs and CFOs) cannot understand “systems thinking.” Now, If you roll out this or a similar framework and announce this and what do you think will happen?
You have a group of people all working on the same backlog but not acting as a team. Code review suffers, mentoring sufferers, pairing is hard, work breakdown suffers, etc. Anything that requires more than one person to conduct/conclude, including helping someone get unstuck, will get deprioritised!
Overall, The inferences seem to be based on hard facts, but the conjectures are all flawed.
Why This Now?
At this point, I want to highlight what “Triggered” me to write this, read the following.,
For example, one company found that its most talented developers were spending excessive time on noncoding activities such as design sessions or managing interdependencies across teams. In response, the company changed its operating model and clarified roles and responsibilities to enable those highest-value developers to do what they do best: code.
McKinsey’s Article on the purported Framework
Wow. I pray for that company.
So, I believe after McKinsey pointed to the fact, that developers are involved in irrelevant things like design, architecture etc. They created separate towers of responsibility for design. In that case, I am puzzled about who will be responsible for the minor things like dependency management, prerequisites, versioning, capacity planning, concurrency, scalability etc.
Did they get anything Right?
Yes. There are tonnes, but they are buried at the bottom. Their focus on Hand-offs and cycle times are really worth tracking in any engineering org. To the authors’ credit, they have also identified some of the core issues with measuring Developer Productivity. But, someone higher in the firm seem to have suggested to soften the blow. So, they have diluted and buried those sections. I will share 2 gems here.
To truly benefit from measuring productivity, leaders and developers alike need to move past the outdated notion that leaders “cannot” understand the intricacies of software engineering, or that engineering is too complex to measure.
The real problem is that in many large organisations, “The Management” doesn’t understand the work they manage. Management can understand the intricacies of software engineering if they become leaders and study the work they manage. In a large behemoth, not all managers are leaders. They want a framework and will enforce it with an iron fist. Now, McKinsey has delivered them a framework!
Learn the basics. All C-suite leaders who are not engineers or who have been in management for a long time will need a primer on the software development process and how it is evolving.
This one Nailed it! The primary reason “Management” finds it difficult to measure the right thing is because they sometimes do not understand the work they want to measure. Leaders who understand do measure the right things. My primary concern with this framework is, in trying to solve this, McKinsey has made the problem worse!
Just google “McKinsey developer productivity” and you’ll find more articles on how this framework is flawed than the original article link!
Anto’s Response to the Article and the purported Framework.
Some say that NoOps is the end of DevOps. Is that really true? If you need to answer this question, you must first understand NoOps better.
Things are moving at warp speed in the field of software development. You can subscribe to almost anything “as a service” be it storage, network, computing, or security. Cloud providers are also increasingly investing in their automation ecosystem. This leads us to NoOps, where you wouldn’t require an operations team to manage the lifecycle of your apps, because everything would be automated.
Picture Courtesy: GitHub Blog
You can use automation templates to provision your app components and automate component management, including provisioning, orchestration, deployments, maintenance, upgradation, patching and anything in between meaning significantly less overhead for you and minimal to no human interference. Does this sound wonderful?
But is this a wise choice, and what are some advantages and challenges to implementing it?
Find out the answers to these questions, including whether NoOps is DevOps’s end in this article.
NoOps — Is It a Wise Choice?
You already know that DevOps aims to make app deployments faster and smoother, focusing on continuous improvement. NoOps — no operations — a term coined by Mike Gualtieri at Forrester, has the same goal at its core but without operations professionals!
In an ideal NoOps scenario, a developer never has to collaborate with a member of the operations team. Instead, NoOps uses serverless and PaaS to get the resources they need when they need them. This means that you can use a set of services and tools to securely deploy the required cloud components (including the infrastructure and code). Additionally, NoOps leverages a CI/CD pipeline for deployment. What is more, Ops teams are incredibly effective with data-related tasks, seeing data collection, analysis, and storage as a crucial part of their functions. However, keep in mind that you can automate most of your data collection tasks, but you can’t always get the same level of insights from automating this analysis.
Essentially, NoOps can act as a self-service model where a cloud provider becomes your ops department, automating the underlying infrastructure layer and removing the need for a team to manage it.
Many argue that a completely automated IT environment requiring zero human involvement — true NoOps — is unwise, or even impossible.
Maybe people are afraid of Skynet becoming self-aware!
NoOps vs. DevOps — Pros and Cons
DevOps emphasizes the collaboration between developers and the operations team, while NoOps emphasizes complete automation. Yet, they both try to achieve the same thing — accelerated GTM and a better software deployment process. However, there are both advantages and challenges when considering a DevOps vs. a true NoOps approach.
Pros
More automation, less maintenance
By automating everything using code, NoOps aims to eliminate the additional effort required to support your code’s ecosystem. This means that there will be no need for manual intervention, and every component will be more maintainable in the long run because it’ll be deployed as part of the code. But does this affect DevOps jobs?
Uses the full power of the cloud
There are a lot of new technologies that support extreme automation, including Container as a Service (CaaS) or Function as a Service (FaaS) as opposed to just Serverless, so most big cloud service providers can help you kickstart NoOps adoption. This is excellent news because Ops can ramp up cloud resources as much as necessary, leading to higher capacity, performance & availability planning compared to DevOps (where Dev and Ops work together to decide where the app can run).
Rapid Deployment Cycles
NoOps focuses on business outcomes by shifting focus to priority tasks that deliver value to customers and eliminating the dependency on the operations team, further reducing time-to-market.
Cons
You still need Ops!
In theory, not relying on an operations team to take care of your underlying infrastructure can sound like a dream. Practically, you may need them to monitor outcomes or take care of exceptions. Expecting developers to handle these responsibilities exclusively would take their focus away from delivering business outcomes and wouldn’t be advantageous considering NoOps benefits.
It also wouldn’t be in your best interest to rely solely on developers, as their skill sets don’t necessarily include addressing operational issues. Plus, you don’t want to further overwhelm devs with even more tasks.
Security, Compliance, Privacy
You could abide by security best practices and align them with automatic deployments all you want, but that won’t completely eliminate the need for you to take delicate care of security. Attack methods evolve and change each day, therefore, so should your cloud security controls.
For example, you could introduce the wrong rules for your AI or automate flawed processes, inviting errors in your automation or creating flawed scripts for hundreds or thousands of infrastructure components or servers. If you completely remove your Ops team, you may want to consider investing additional funds into a security team to ensure you’re instilling the best security and compliance methods for your environments.
Consider your environment
Considering NoOps uses serverless and PaaS to get resources, this could become a limiting factor for you, especially during a refactor or transformation. Automation is still possible with legacy infrastructures and hybrid deployments, but you can’t entirely eliminate human intervention in these cases. So remember that not all environments can transition to NoOps, therefore, you must carefully evaluate the pros and cons of switching.
So Is NoOps Really the End of DevOps?
TL:DR: NO!
Detail: NoOps is not a Panacea. It is limited to apps that fit into existing #serverless and #PaaS solutions. As someone who builds B2B SaaS applications for a living, I know that most enterprises still run on monolithic legacy apps and even some of the new-gen Unicorns are in the middle of Refactoring/Migration which will require total rewrites or massive updates to work in a PaaS environment, you’d still need someone to take care of operations even if there’s a single legacy system left behind.
In this sense, NoOps is still a way away from handling long-running apps that run specialized processes or production environments with demanding applications. Conversely, operations occur before production, so, with DevOps, operations work happens before code goes to production. Releases include monitoring, testing, bug fixes, security and policy checks on every commit, etc.
You must have everyone on the team (including key stakeholders) involved from the beginning to enable fast feedback and ensure automated controls and tasks are effective and correct. Continuous learning and improvement (a pillar of DevOps teams) shouldn’t only happen when things go wrong; instead, members must work together and collaboratively to problem-solve and improve systems and processes.
The Upside
Thankfully, NoOps fits within some DevOps ways. It’s focused on learning and improvement, uses new tools, ideas, and techniques developed through continuous and open collaboration, and NoOps solutions remove friction to increase the flow of valuable features through the pipeline. This means that NoOps is a successful extension of DevOps.
In other words, DevOps is forever, and NoOps is just the beginning of the innovations that can take place together with DevOps, so to say that NoOps is the end of DevOps would mean that there isn’t anything new to learn or improve.
Destination: NoOps
There’s quite a lot of groundwork involved for true NoOps — you need to choose between serverless or PaaS, and take configuration, component management, and security controls into consideration to get started. Even then, you may still have some loose ends — like legacy systems — that would take more time to transition (or that you can’t transition at all).
One thing is certain, though, DevOps isn’t going anywhere and automation won’t make Ops obsolete. However, as serverless automation evolves, you may have to consider a new approach for development and operations at some point. Thankfully, you have a lot of help, like automation tools and EaaS, to make your transition easier should you choose to switch.
The fact that you clicked on this article tells me that you are leading/heading a Team, group or an entire Engineering function and most likely a fast-paced startup. Assume the following,
It was a regular weekday, and your CEO/CTO asked the most intriguing question.
Do we measure Engineering Productivity? How do we fare? What can we do to improve it?
Well, if your boss’s name is not Elon Musk or if you do not work for Twitter, you can still be saved. Go on and read through. I know it is a long read.
What is Engineering Productivity?
As with anything you’re trying to improve, it starts with measuring the right data. So, you can actually track the right metrics. This data will form the basis of your analysis and baseline. I strongly recommend you don’t change anything about your current engineering process before you can collect sex weeks’ worth of data about your processes. If you start working on processes, you could end up with a Survivorship Basis.
You should have sufficient historical data to make comparisons. On top of that, most teams work in sprints of two weeks, so six weeks of data allows you to collect data for at least three different sprints. This will give you the allowances for any spikes and eliminate any unusual stress or slack on the execution.
Next, you should make gradual changes to the engineering process to see what improves or impedes the value delivery. It’s ideal to only implement one change at a time, so you can see the effect of each change, with all other things being equal. (it never is :D)
For example, if your engineering squads suffer from significant technical debt, you may want to build an additional stub related to feature completion. Every time an engineer completes a new feature, they must document the new feature. This could mean describing the feature, how is it built, what are the outcomes, how it interacts with other functions and the reasoning behind the design decisions.
By continuously measuring engineering productivity metrics, you can determine if this change has positively impacted the developers’ productivity.
How Is Engineering Productivity Measured?
There are potentially 100s of metrics you can measure for an Engineering Org. Here are four key metrics that will help you to get started with measuring engineering productivity. And I have consciously excluded the Sprint Velocity.
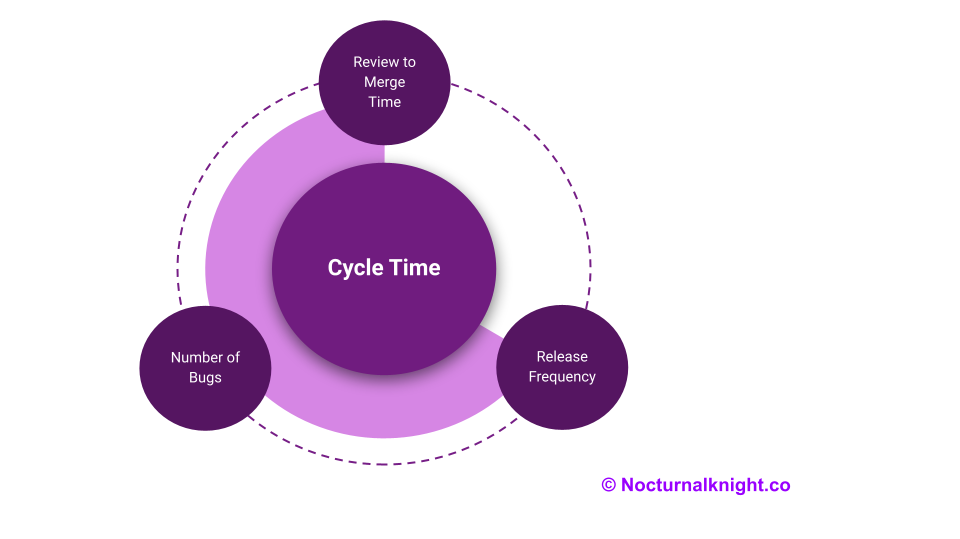
4 Prime Directives of Engineering Metrics
1. The One Metrics to rule them all metrics – Cycle Time
Software development cycle time measures the amount of time from work started to work delivered. It is a metric “borrowed” from lean manufacturing, and it is one of the most important metrics for software development teams. In plain speak, cycle time measures the amount of time from the first commit to production release.
2. The Oracle of an Engineering Leader – Release Frequency
You should measure how often you deploy new changes to your customers (production). In addition, you can track deployments to various branches/instances, such as feature branches, hotfix branches, or QA branches. This data would show you how long it takes for a feature/fix to move through the different development stages. In addition, the Release Frequency reflects the throughput of your team. It’s a good stand-in replacement for Agile Velocity, so you don’t spook your Engineers and you are not blind as well.
3. The Guardrail – Number of Bugs
You should definitely track the number of bugs that your team has to resolve within 2 sprints of releasing a feature. This metric helps you to understand the quality of your code better. Higher-quality code should display fewer bugs after feature deployment.
While there are derivative and more evolved metrics like Defect Density, Mean Time to Detect (MTtD), Mean Time to Resolve (MTrR) and Code coverage, those onces makes sense after you’ve taken stock of and address the prime metric “ No: of Bugs” first.
If you want a more detailed list, methodology of QA metrics, refer the links given below.
4. What is your “Blocker” – Review to Merge Time (RTMT)
This may look like a zoom-in on “Cycle time” metric we discussed earlier. But, in fact it is very different. In fact, it is an interesting metric suggested by GitLab’s development handbook.
You should measure the time between asking for a pull request (PR) review and merging the PR. Ideally, you want to reduce the time a feature spends in the review state (or pending review state). A high RTMT prevents developers from progressing while they wait for feedback and encourages context-switching between different issues/features.
Arguably, Context-Switching is the highest productivity killer and should be avoided as much as possible.
So, why would you measure all these engineering productivity metrics?
Why Is Measuring Engineering Productivity Important?
When you’re a “fast-growing startup”, it’s important to keep an eye on engineering productivity. It happens that these startups favour growth through feature delivery at the cost of effectively scaling the engineering team and ensuring the team’s efficiency.
I hear your question.
But, why does my CEO/VP/MD not understand?
Answer is simple
Assume you have to manage multiple VP’s expectations and outcomes (Sales, Marketing, Support etc), Company’s OKRs, and investors (or) board, will you have more time to dedicate to Engineering Productivity?
In these cases, technical debt can quickly grow, which will slowly kill your team’s productivity. Technical debt can have many negative consequences:
More bugs for your team to fix
Lower code quality—not only bugs but also worse code design
Harder to debug code
Scalability issues
A decline in overall happiness and job satisfaction
To avoid all of these scenarios, you should measure the engineering team’s efficiency and avoid technical debt buildup. Avoiding these problems before they occur is an excellent Occam’s razor. But addressing them head-on will have a significant impact on your organisation, both materially and culturally.
In addition to preventing your team’s productivity from going down, the engineering productivity approach allows you to experiment with various approaches to try and improve throughput & efficiency.
So, the goal is to improve the engineering process itself. For example, introducing new tools or applying new techniques. Next, you can measure the impact of these changes on your team’s productivity.
In the next part, I will write down on how can measurement improve engineering productivity, Stay Tuned!
How to Attract the most relevant applicants with great job postings
One of the main problems in SaaS/Software engineering hiring is the way job descriptions are written. While I knew this for some time (read years) The problem is, I was too lazy to change anything about it! That is until recently, one of the candidates I was interviewing for an Engineering Manager Role said this in our introductory call,
Me: Hope you’ve had a discussion with Ms.ABC (our HR) regarding the Roles and Responsibilities. If there are questions on it I can answer them, or we can get into the agenda.
Candidate: Yes I had a discussion with Ms. ABC. But, quite frankly it was your boilerplate JD. I’d actually want to understand what exactly I’d be doing. What will I be in charge of? What will I move?
Needless to say, I spent the next ~30 minutes walking through the current team structure, where he’d come in, what will he own, what the growth trajectory looks like etc. Ultimately, we did 2 more calls before both of us were satisfied that there are mutual synergies and went ahead. It made me reevaluate all of our Job Descriptions over the weekend and rewrote almost half of them to include factual details on projects, outcomes expected, tools available, glimpse of growth among other things.
After this, I asked the HR to send this “revised” JD to the candidates once again.
And the result was visible from Monday!
Either candidates that the HR thought super suited started dropping voluntarily from the process or candidates started expressing interest, doing more research on our stack, infra, product proposition and competitor benchmarking, before the call. Some even did a cold reach-out on Linkedin.
So, I wanted to share the small titbit here.
Why General Descriptions Don’t work?
Most Job descriptions barely resemble “specifications” at all, but feel more like generic stubs. Sort of like the equivalent of shopping for a car with as much details as “red and goes fast” or “black and built to last.”
It leaves too much open to the imagination for it to be a successful criterion to enable fitment. With criteria as broad as this you’ll end up spending an inordinate amount of time executing the search, since so many things appear to be a match. For me, Red and goes fast is always a 1971 Ford Mustang, for you it could be a 1998 Ferrari 365.
A Red Ford Mustang & a Ferrari 365, What do you Fancy?
A Black Dodge Ram and Jeep Cherokee, What do you Prefer?
The truth is that statements like the above — or its equivalent in engineering hiring — “Get me a backed dev with OOPS in Python/Java/Go with 5 years experience” — guarantee a similarly frustrating shopping experience. You’ve made it needlessly difficult for yourself and your HR/TA team to identify the specific talent you want. In this trite example you’ve indicated that you’re looking for a mid-level engineer that knows OOPS, but that basically includes everyone that ever graduated with a CS degree in the past 5 (to 10?) years. Surprisingly, many job “specifications” we see contain rarely any more info. These are the “Boiler Plate” Job Descriptions.
How did we find ourselves in this mess?
I understand why hiring managers do this. Sometimes they’re not exactly sure what they want — after all, it takes real time and effort to work out the specific vision for the role. But instead of acknowledging this and then solving the real problem (their own laziness), they delegate the JD writing to their Team/HR and it turns into generic tech JD. But the hiring manager is unfazed — “I’ll know the right candidate when I see them,” they say. Really? It could be true in some instances. Sometimes, we start with a Backend developer, then we come across a candidate with experience in building a full pipeline or a payment system. Then we expand the role to cover wider scope and evaluate against it. But generally, How will they know the right candidate if they can’t write down specifically what the candidate looks like?
Another reason for generic job specs is because a hiring manager is recruiting in a talent-constrained market (sound familiar?), and it feels like a smart move to cast as wide of a net as possible. Theoretically, one should be able to get more candidates into the top of the funnel this way, right?
Perhaps. Theoretically. But in my experience, this approach usually, and utterly, backfires. Here’s why:
Boiler Plate Job Descriptionsaren’t designed to appeal to any engineer in particular
In the current job market, engineers are faced with a wide variety of options from some amazing established companies and lots of seemingly “sexy” startups. (after “the great resignation”)
You need to take your opportunityto stand out! The more specific you are about the challenges a specific engineer will get to work in a specific role, the more traction you’ll get with (the right) candidates.
The idea is to make an engineer excited when you describe what they will “Get to do” in the first 12-15 months in the role.
Be very specific,
Talk about the product/modules they will own/drive/be part of,
Talk about the outcomes and metrics they will own and drive,
Talk about the toolchains & frameworks they’ll use (or get to choose),
Talk about What’s hard/challenging about the role, How are they a great fit.
The more details you can squeeze into the spec to help them visualize their role and the projects they’ll be working on the better.
Boiler Plate Job Descriptions don’t arm others to help you
Another bad thing about generic JD is that they don’t help others help you. Think of how much reach could you get by using everyone in your network as a recruiter. But in today’s scenario, “everyone else” is already asking them if they know any Python Engineers or React Developers or Go Engineers. Why would they help you? Because you’ve taken the time to get specific about what you want? Maybe.
Take a look at the following Job Description. Anyone in software engineering who had some deployment, infra-planning & communication seems to be a candidate for the role.
I recently got a request from a founder friend of mine to refer a Sr.Tech Lead/Engineering Manager for an early-stage startup. When I saw the JD, it was so generic it did not even have the primary stack on it. Assume sharing it from your handle. I politely declined to share it and asked for some more information and said will come back once he shares. (I believe he is very busy and hence hasn’t come back)
The bottomline is, Make them want to help you — give them a JD that’s so amazing, well-written, specific, (even entertaining) — that they can’t help but pass it on, post it, tell their friends about it, etc. If you make it stand out — you’ll get more attention from the folks that can help because you’ll arm them with something interesting & effective that they can use to reach out to their network.
Boiler Plate Job Descriptions don’t enable you to know what success looks like
This is a very simple point — see above — if you can’t explain what the ideal candidate looks like, how will you know when you’ve found them? The JD shared by my friend looks as vague as this.
Typical Boiler Plate JD
Actually, his company was looking for a guy who could not just do Infrastructure Architecture. They wanted someone who has architected/built a cloud native SaaS application. His team has built the application and has no idea how to convert it to truly cloud native format to scale without breaking the bank!
The main idea here is about not being willing to settle for less. I realise the market is tough right now, and maybe you’ll need to make compromises. But do you want to start at the wrong end of the pool? When you go out the door with a generic description, you preemptively give up the battle. If you need to settle — fine! — but know exactly what points you’re compromising on.
The larger problem is that if you don’t know what the best candidate really looks like then the other people involved in making a decision likely don’t know what s/he looks like either. A well-defined, specific description of the role enables everyone involved in the interviewing and hiring process to be on the same proverbial page.
Now go get started!
Fixing your job descriptions will take some work(as I found out). To get to specifics, you’ll need to dig in and make additional efforts. You might also need to do some retraining in your organization and teach others these principles, too.
But when you get through the hard work, your postings will turn into valuable weapons that will,
a.) appeal to the engineers you want to reach,
b.) enable others to help you expand your outreach, and
c.) get your hiring team on the same page to quickly come to the right decision.
If you’re curious to see what roles we currently hire for, we have a lot of openings in Product, Design and Engineering:
It ranges from Kubernetes Architect, React Native Mobile Dev, Sr.Backend Dev, Tech Lead-Mobile Technologies, Engineering Managers, Associate Product managers, Product Managers etc.
This post is a summary of a series of “Mentoring” and “Advisory” calls I did with some early stage startups, over the past 6 months. Most of the time, one of the founder ideates, one builds/leads the build. But, they want to go fast and think they need a Product Manager. Unfortunately, most of them don’t need a Product Manager. If you are at a similar juncture, read on to find out more..
The title is a controversial question, I know!
The State of Product Management:
Off lately, Product Managers have to wear too many hats, leaving the role vague and blurring the boundaries of their area of responsibility. This ultimately leads to diminishing the value of the product manager’s core functions. Product Management is a strategic, cross-functional, front-line role that brings great value to the product and business.
But, it commonly gets abused by many fast-paced organisations expecting product managers to fill in the gaps in various disciplines. This may be process, pricing, unit-economics, partnerships, product-marketing to name a few. They can definitely do that due to their broad professional background.
Admittedly, product managers do have a broad background, otherwise they would have a hard time to be able to effectively collaborate with the stakeholders, lead the product and make the informed decisions. But this definitely should not end up with the product managers becoming de-facto “deciders” or “doers” originally intended to be done by other roles in other functions.
How do you decide if you need a Product Manager or Not?
Like any problem, there are two approaches, if an intellectual debate is more to your taste, continue reading on. If it is more of a rational “doer” approach, head straight down to it.
Intellectual Approach
Ask yourselves some questions:
If you are a founder or a leader or a decision maker, before hiring a Product Manager, question yourself as to your expectations from the product manager.
Think hard on what you want them to do:
What do you want your new product manager to change/fix in your organization? What is it that you are unable to do?
Do you not already have the in-house expertise that would help you address the current issues?
If you are still unsure about whether or not you need a product manager “in the house”,
I recommend that you go through this checklist and answer Yes/No to each of its questions:
Do you have a vision for your product? Do you believe it is aligned with the market needs?
Are you sure you are building the right product — the one that delivers value to your target audience?
Do you have a direction for your product? A long-term and a short-term roadmap?
Till now, have you been able to execute your roadmap without major distractions?
Are you capable of maintaining the strategic focus across all levels of the organization?
Do you know your competitors and what they have on the game? Proposition, not features.
Do you have an established feedback loop with your clients? (Not the feature request types)
Do you mostly base your decisions on evidence/data?
Do you find it easy to say “No” to various stakeholders from various functions while hearing their “suggestions” and “inputs” and explain them why what they think is not the “most” right thing?
If you answered “No” to more than 4 questions, you probably need a Product Manager, No doubt in that.
But the reality is, that hiring a highly capable Product Manager won’t magically change the DNA of your organisation. I have seen multiple orgs regress into a worser situation than before. Because, the person responsibl has delegated the product decisions to that Product manager with a shiny belt, without enabling/empowering him/her.
The result
Rational Approach
If you’re a CEO, founder, or senior leader considering hiring a PM, check this list and see if you need one. Lets play a guess and eliminate game.
If you can see your organisation is reflected in this article, don’t bother hiring a PM — save some money and hire a cheaper role. You would also spare a PM some misery.
Don’t bother hiring a PM…
If you have a fixed idea of what to build
You already know what you want to build, you just need somebody to build it. You’ve hired some engineers. You need somebody to gather the requirements from you and the team, and maybe manage the back-and-forth of different requirements from many stakeholders. This person then passes the requirements along to the engineers and makes sure they deliver on time.
You need a Project Manager, not a Product Manager.
If your Sales team or clients are dictating what to build
You have a handful of big clients and you’re ready to bend over backwards to deliver what they need, including building custom features. Your Sales team knows best what to build, surely, as they’re the ones talking to the customers all the time. Now it’s just a matter of writing the stories and prioritising them.
You need a Delivery Manager, not a Product Manager
If they won’t have access to your customers
You have some very-important-people as customers and their time is precious. You don’t want the new person you just hired to talk to them directly — may be they will say something untoward?
I don’t know what you need, but you certainly don’t need a Product Manager.
If you’re not ready to delegate authority
You know that product managers should be given a problem to solve, not a feature to build. Heck, you were probably a Product person yourself, who has now set up your own startup. You have the vision and the strategy and you know exactly how to get there…
What’s left for the Product Managers to do, then? Maybe hire an Engineering Manager or a Tech Lead?
If you see technology as a support function
An easy way to assess this: How much of your company budget is dedicated for product/technology/innovation? If you’re not willing to invest significant resources to staff the product/technology team properly, they’ll be left firefighting all year long.
Don’t hire a Product Manager — yet. Assess how you see technology plays a role in your company’s vision. Set aside a proper budget, hire a strong CTO or CPO, and let them build their team. Only do that if you’re willing to listen to them though — or don’t bother doing it at all.
In Sum and summary, Hire a Product Manager only if you believe you can delegate authority, and can come to a rational decision based on data. If not, hire a Project Manager, Engineering Manager or any of the other roles.
A Tech Lead writing code is a disservice to the company.
You have been coding your whole life or at least most of your professional life. Recently, you have been promoted/designated or as a Lead Engineer or a Tech Lead. Does anything change for you?
Should you stop coding?
People generally say, hell no!
Hell No!
And why should you now?
You like it;
You enjoy it and probably
really good at it too.
But then you start leading a team, which means that everything should change or at the minimum, something should change Or shouldn’t?
It’s an eternal question for every engineering manager. I have tried to answer it all along my career and
The hardest thing is to understand that you are not “just a” developer anymore.
I know, the above statement is controversial with multiple of my readers.
Most of you are now in a role with,
different responsibilities,
different daily schedules, and
tasks that involve different mental processes.
And you are most likely trying to combine two things at this time.
You’re trying to be a good developer (that you used to be).
You’re also trying to act as a “Coordinator” “Communicator” and also “Manage” things
I know, your designation/title says Tech “Lead” or “Lead” Engineer and not Engineering Manager. But, in most organisations, a TL is looked upon as an EM in waiting (For more insight on career tracks for a TL – Check out my previous article on Engineering Leadership on Startups )
And working two jobs may often lead to early burning out and, frankly, not being any good in either of them.
I will take two very probable examples here.
Case 1: You are a Lead and you want to own a particular piece of code rewrite, which is giving a lot of concurrency nightmares to both the product support and your on-call teams. Most design/debug and development tasks require high concentration and focus, which contradicts the very nature of the team leader’s work. Multiple planned meetings, calls, messages — a lead needs to be on alert. It’s tough to consider all the edge cases when your slack/hangout/teams is buzzing all the time.
Another essential element is most of these buzzing & pinging can be controlled if your team is good at Asynchronous Communication. (I will write more about it in a future article)
Case 2: You are a Lead, driving a new subscription module for your latest product. There are simply so many stakeholders, your PM, Payments team, external partner/vendor, Infra team etc. It will be hard to be prepared to answer your teammates’ or vendors or customers’ questions if all you can think about is the efficiency of that function you just wrote.
Time Share:
Another thing is that spending a lot of time on development gives you little time to do your actual job as a lead/manager. And your job is managing other people. Though you will probably make time for your primary duties — assigning tasks, making estimations, validating designs, communicating with the stakeholder — you will miss out on all the other “noncrucial” parts of your job.
You can get so invested in a feature that you will miss some critical signs of your employees becoming demotivated to do their work, tired, or less happy. And, as you are busy, you become less innovative. Who will come up with a new architecture for the 3-year-old service? Most certainly not you, since you are too deep in the code.
Anti-Growth
Minefields you’d inadvertently trigger are either the Martyr Effect or the Hero Syndrome (Think Bruce Wayne or Tony Stark). On the first & second one, You’d always take the toughest part of the code or the most interesting part of the code, respectively. Either way, you’d be creating a team who’d be ill-prepared to take up challenges on their own or ill-equipped.
But what if I do not want to give up coding?
It may so happen that plain management isn’t your path. So, from here on, you may not enjoy what the role has to offer. Being a Team Lead/EM is all about people; being a Principal Engineer (or staff engineer or architect) is about code. If programming is critical for you and brings you more joy, you may be more suited for a Technical Leader role. So choose wisely.
But as a Team Lead, you are still most welcome to join code reviews and help your teammates with challenging coding problems if you want to.
Consult. Guide. Assist. Communicate
This is going to be your Motto.
And of course, You should definitely continue to code in other “Non-paying” parts of your job. Start automating your units, create boiler plates, write smaller, niche, critical elements of your system.