What Does It Take To Become a “Senior” Software Engineer.
This article is a result of a discussion with one of our ” Ninja-neer”. He was interested in “Delivering Business Value” but not interested to take up People Management or other responsibilities. Do I have any pointers for people like him? Of course. So, we started discussing on ways he can contribute at a different level. In the end we talked for about 90+ minutes. This is an extract & summary of that discussion.
In the late 2000s, it was a trend for companies to hire developers based on the programming language they had experience with, frameworks, tech stack, and such. (I still remember the disappointing gaze I got when I told the interviewer that I have only worked with CVS and Mercurial and not in SVN, which the team I was interviewing for was using)
It is preferable to hire engineers skilled with a particular stack, it is not crucial. After all, great software developers should be able to learn and ramp up quickly with the massive knowledge available on the internet.
With that being the absolute baseline, companies started to value developers with great complimentary soft skills, as their technical expertise is now baseline to work in the industry, setting the bar even higher for people starting a career right out of college.
The Three Fundamental Traits
After almost 12 years of managing/leading Software Engineering teams as a Technical Lead, PM, Engineering Manager, Director etc., I have observed the skills that tech organisations generally value the most. I believe I have identified a pattern that generally falls into three different categories:
1. Technical expertise and craftsmanship
Understanding the fundamental concepts of computing is the baseline to becoming a software engineer. Even though this looks like common sense, this science is vast and is continuously evolving. Gone are the days when knowing some data structures, array transformations and basic algorithms will get you over the ledge. Also, the organisational/product context is very important as well. For example, my peers at Paypal prided in getting sub 500ms latency for all the “processes” they wrote, while my colleagues in Hinduja Tech focussed on ensuring “zero-packet loss” from the telematics devices.
It really boils down to what is your company’s key priorities are. It can be quicker release cycles/velocity, resilience/ fault-tolerance or efficient memory management. Whatever it is, you need to first understand the “value” and then follow it in your implementations.
2. Scope and autonomy
We do not live in a world where working alone and implementing specifications from LLD/UML diagrams is sufficient anymore. For that matter, in the last 18+ years, I have met exactly two people who were able to pull it off and one was a 62-year-old Ingres developer, who was single-handedly managing the 40year old databases of PA. Those who know how to navigate complexity requiring minimum supervision are now extremely valuable professionals. Actively communicating and ensuring alignment is more important in these times of high-velocity organisations.
3. Communication and influence
Even though nobody expects you to be a skilled public speaker, we are long past the era where programmers were introverts that spoke an unintelligible alien language. Knowing how to work with people and interact with non-technical partners is a valued skill in the market.
I had a very first-hand experience of why clarity in communication is so important as you grow up the ladder in your tech org.
I was (hastily) called to a meeting, where my boss (VP) was explaining to our CEO, of why we should not be building the next generation of BRTS for Congo, Senegal and Ghanna on Desfire EV1. The primary concern was around security and privacy. There were major concerns around its security and was exposed just before the London Olympics. (It had taken me 3 meetings over 2 weeks to convince my Boss to go with EV2) I still do not know why he thought I might be able to do it in 10 minutes and that too in front of the CEO!! But the important thing was, My boss was willing to give me a chance to try it and in the process, he was giving me visibility to the inner workings on the 11th floor (C-Suite).
How do I convince my CEO to opt for a solution with almost 20% additional initial cost?
Is it with NXPs’ security from relay attack or with 16KB vs 4KB of usable memory or something else? Then it struck me if the topline is something my CEO was interested in he could definitely understand the bottom line! I fumbled something around potential “Revenue loss” and did a whiteboard tabulation of some numbers. (Desfire
Surprisingly, my CEO got it despite my ramblings and corrected my statement, It is a potential Revenue Leakage, not a loss!
That one meeting changed almost every communication I did after it.
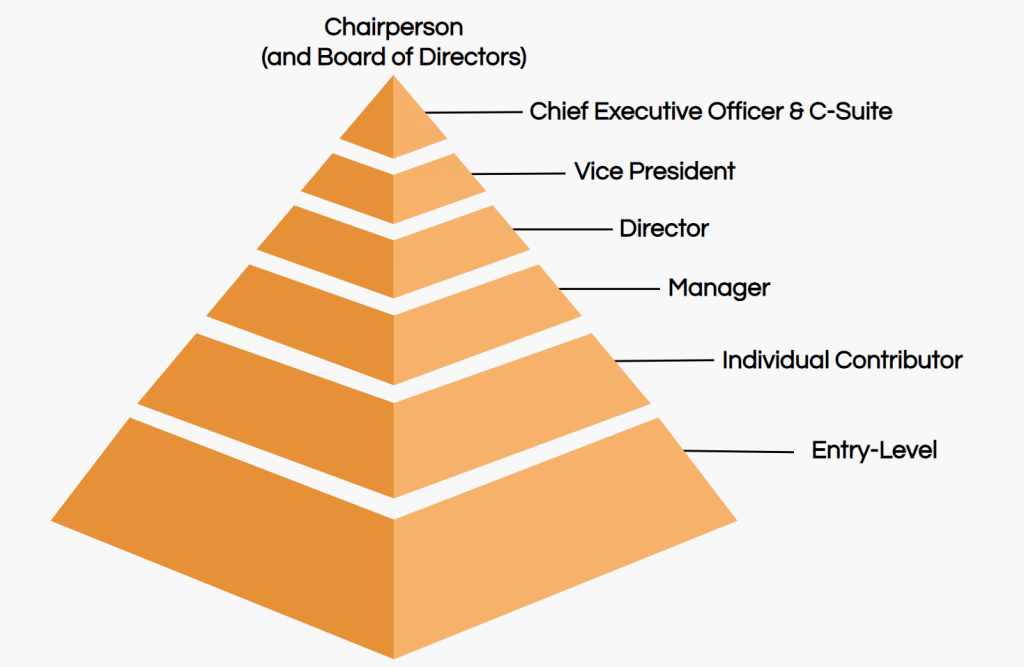
Becoming a Senior IC – Sr.Engineer, Staff Engineer, Principal Engineer, Architect (or any of the other dozen designations)
Again, this article is aimed to give some clarity on what are the options for rising up the ranks as an Indivudual Contributor. The Tech Ladder in most Startups are similar with slight deviations. After you become a Sr. Engineer you have 2 tracks – Technical Excellence leading to Staff Engineer and Principal Engineer. The other track involves People and Budget management leading to Tech Lead, Engineering Manager and Director, VP etc.
I’d like to help you understand important aspects that can place you at higher levels based upon the expectations set on each level of proficiency grouped into the following tiers: Beginner, Intermediate and Advanced.
| Expertise | Scope & Autonomy | Influence | |
| Beginner | Learning | Feature & Guided | Collobrators |
| Intermediate | Proficency | Product, Performance & Tactical | Team(s) Wide |
| Advanced | Expertise | Domain, Industry & Strategic | Teams & Function wide |
This grid above depicts the career trajectory of software engineers in a super-simplified way. It is generally more complex than that, but it still serves as a good guideline to identify career points of inflection. Note that I did not use the so popular “associate,” “mid-level,” and “senior” on the different levels. This is more of a grouping of related circles of roles.
Starting a Career as a Software Engineer
As a beginner in this new and adventurous area, there are lots of low-hanging fruits you can learn from. In fact, learning should be your focus. You should acquire as much knowledge as you can from being exposed to a variety of problems.
Up until a point, you will work on “very specific” problems or small features or bug fixes until you ramp up and have a good understanding of the lay of the land (product or system) you are helping to develop.
You will pair with more experienced engineers and learn from code reviews and feedback from your partners. Engineers at this level spend a reasonable amount of time learning until they get proficient with tools and acquire more domain knowledge. You’ll learn a lot of Tricks and Tools from your senior peers and you will also find the kind of problems you’re proficient in solving. Which will result in similar problems, fixes or features you’re assigned with.
The trick is to emrace the “Streotype” and make it your “Niche”, while also diversifing enough to get a hang of other things and continue to learn.
Working as a Proficient Developer
At this point, you would have gotten your hands dirty for a few years and developed mastery of computer science including algorithm design, data structures, design patterns, and the tools and frameworks you work with. You have very deep experience with at least one or two part of the technology stack you work with.
It is now taken for granted you will be able to deliver complex pieces of software with very little supervision. In fact, there is also the expectation you can help less experienced engineers to grow and guide them to execute the tactical plan you created. You help people to review their code as well as solve problems and develop new features.
One thing to remember is, “Code Review is a Bidirectional Learning exercise” – The proficient ones understand/learn new approaches from the beginner, the beginner
It is the time in your career that you start getting the opportunity to lead small projects and time-bound initiatives and likely start to get more exposure to cross-functional partners and some non-technical stakeholders. Most software engineers stay at this level for many years.
The Non-Comissioned Officers are called as the backbone of an Army. Similarly, Sr.Developer is the backbone of any product/Engineering Team. As this is the most visible and “on-the-ground” leadership.
The Making of a Senior Software Engineer
At this level, Coding in general starts to become less important as you are now a visible voice for your team and across the organization. You now understand how to make difficult trade-offs in the architectural level of your application across the entire domain.
As a domain expert, you own a substantial part of your company’s codebase, supervise its evolution and work from other engineers, as well as advise other teams on how to better approach or integrate with your services and applications.
As an advisor, your contribution is clear and visible across multiple teams. You are highly influential and your advice is constantly sought from other engineers and cross-functional partners.
This is the inflection point where you start considering a transition to leadership roles. It usually takes some years to land at this level. The next step for you is growing the impact of your work across teams, organizations, companies, and industry-wide.
Even though colleges prepare you to develop software, as you grow in your career that skill starts to become less important and other soft skills turn out to be more relevant. I hope i was able to nake justification to the topic of growing as an indivudual contributor and make higher impact and inspire you to reflect on your own trajectory and how to proceed with the next steps.